主題
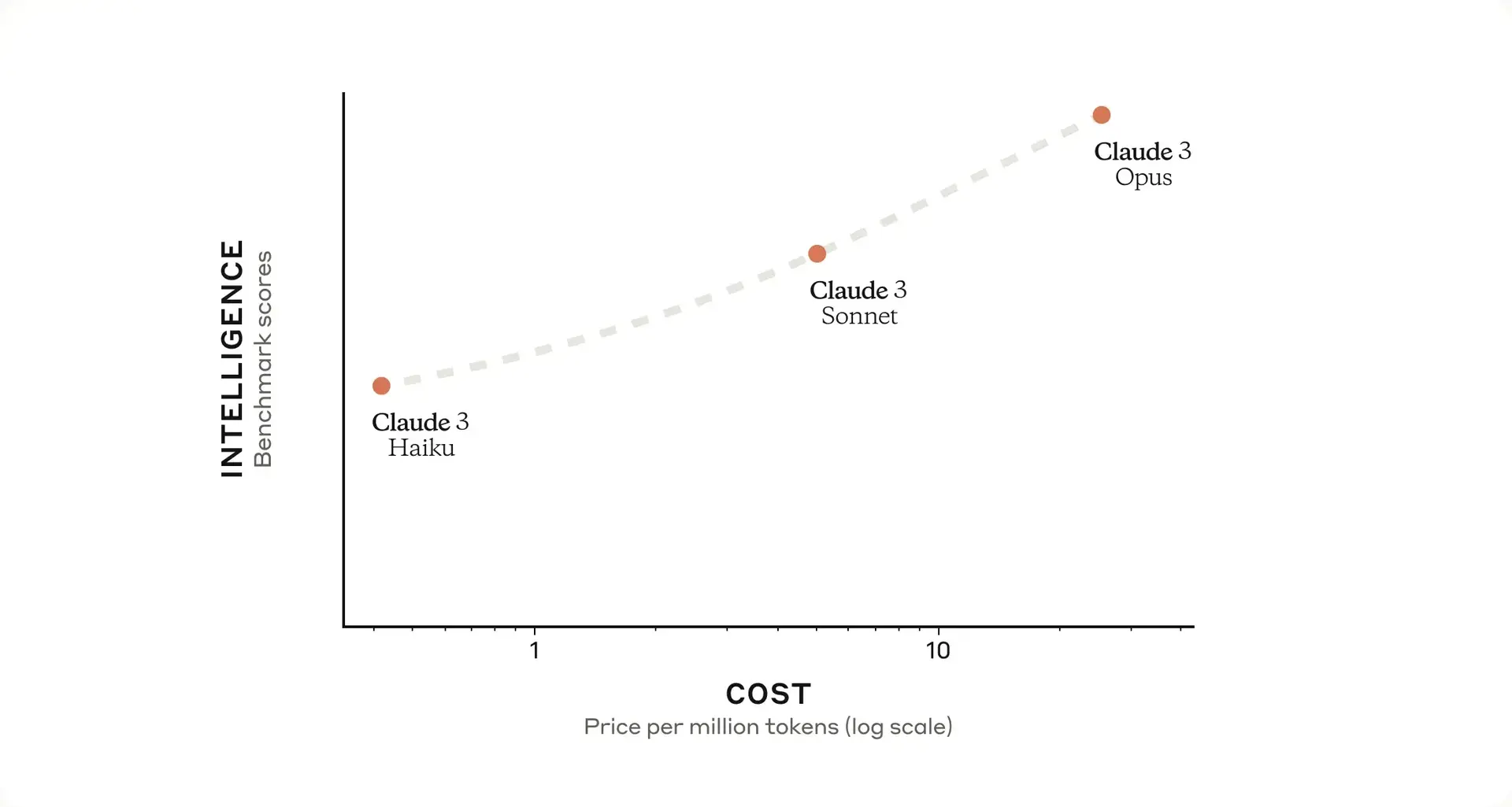 Anthropic繼去年七月推出Claude 2後的下一代模型,模型包含三種型號,
Anthropic繼去年七月推出Claude 2後的下一代模型,模型包含三種型號,按能力高到低分別為Opus > Sonnet > Haiku,目前已開放Sonnet和Opus,
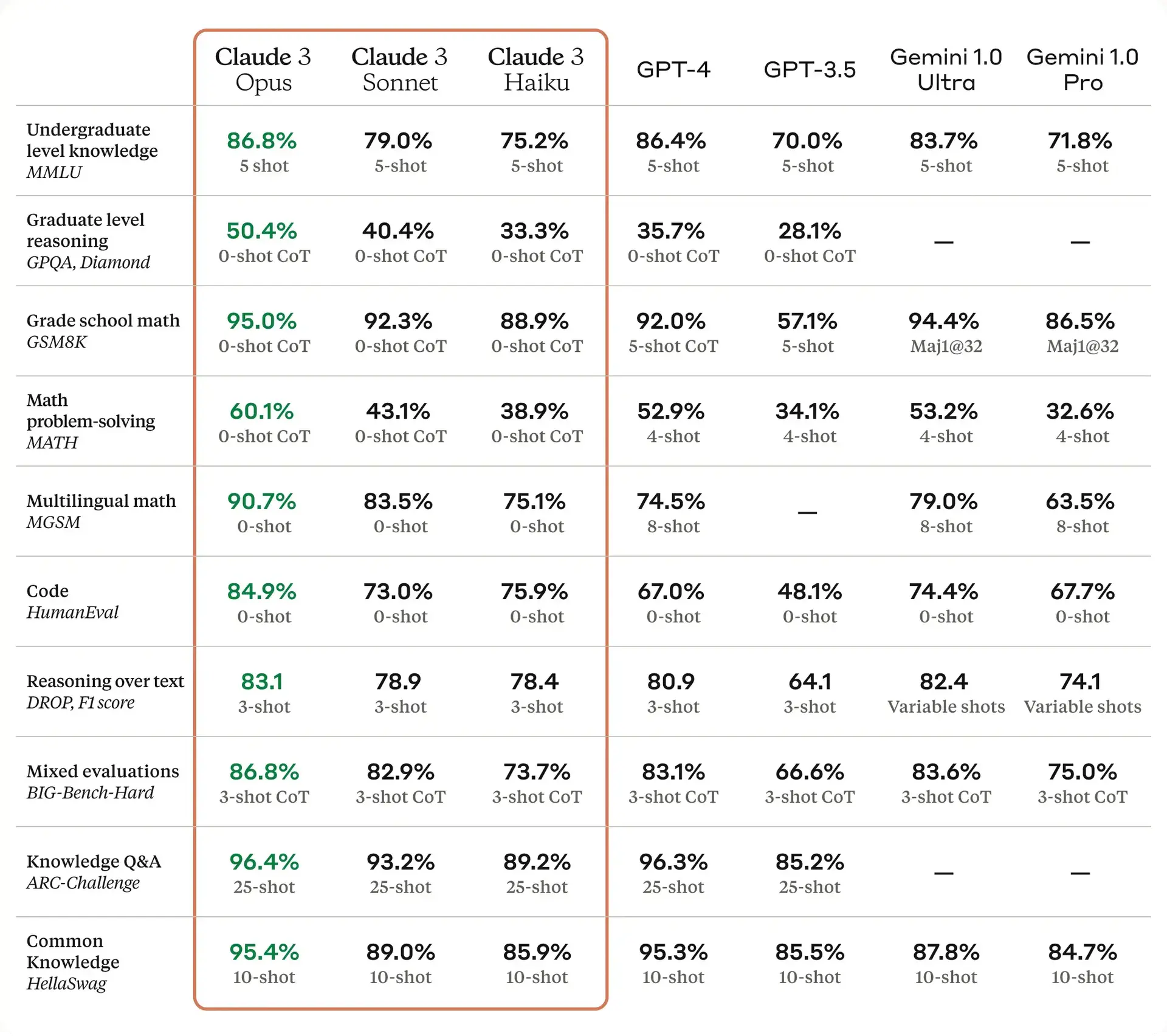
各模型能力比較 (Claude 3 Opus、Sonnet、Haiku、GPT-4、GPT-3.5、Gemini 1.0 Ultra、Gemini 1.0 Pro)
 |
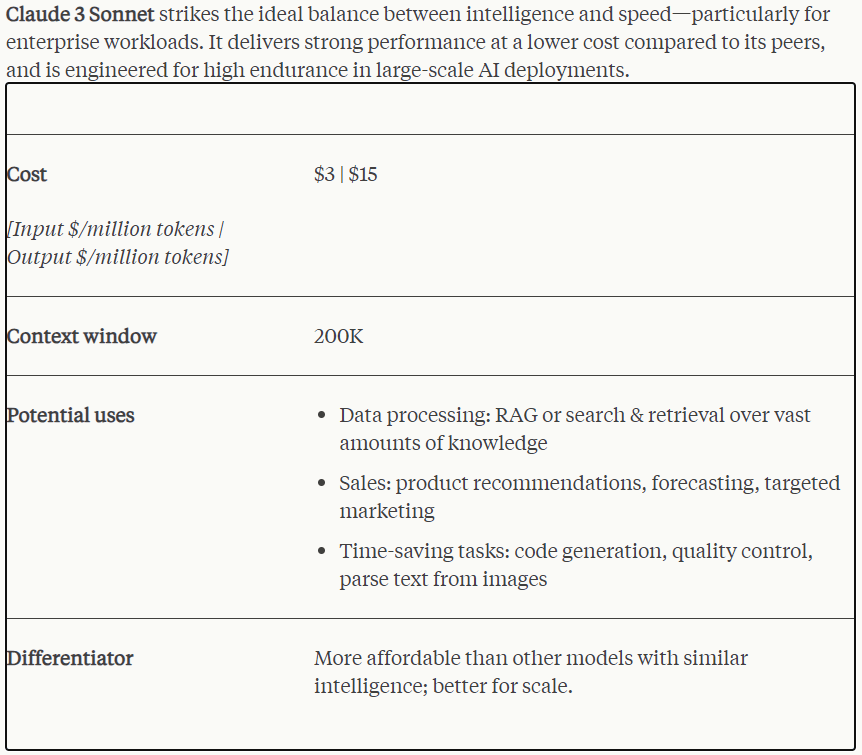 |
Sonnet(中)為聰明與速度之間平衡的模型,速度方面比Claude 2、2.1快2倍,且更強聰明,擅長處理需快速回應的任務(知識檢索、銷售自動化等)。
 |
Haiku(小)模型為速度最快並最具備成本效益的型號,可在不到3秒的時間內閱讀完論文網站arXiv上包含圖表、資料密集的研究論文(約10K Tokens),目前尚未發佈(已於2024/3/14推出),並表示推出後期望能更進一步增強性能。
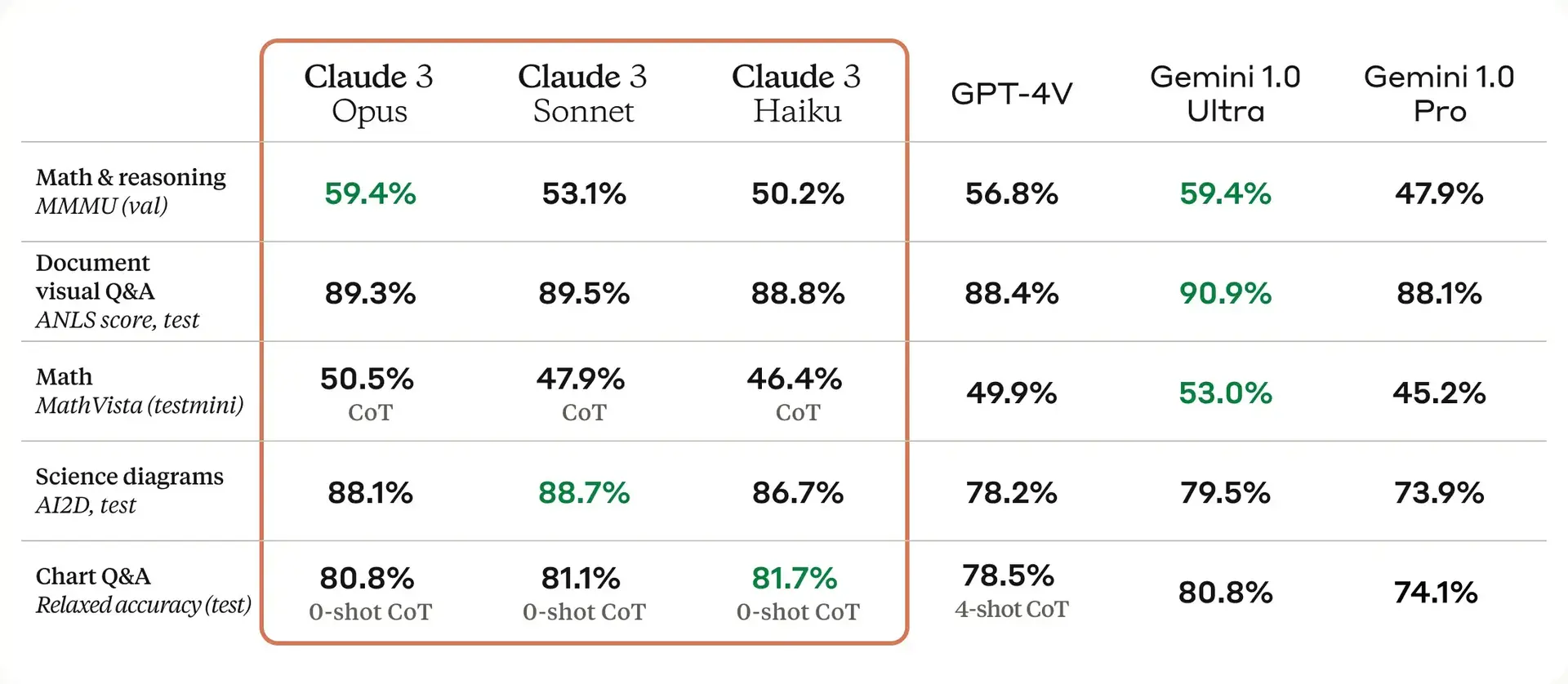
Claude 3具有強大的視覺處理能力,可以處理各種視覺格式檔案,包括照片、圖表、技術圖表、圖形等,並指出一些客戶的知識庫裡有高達一半都是PDF、流程圖和投影片等各種類型的視覺內容。
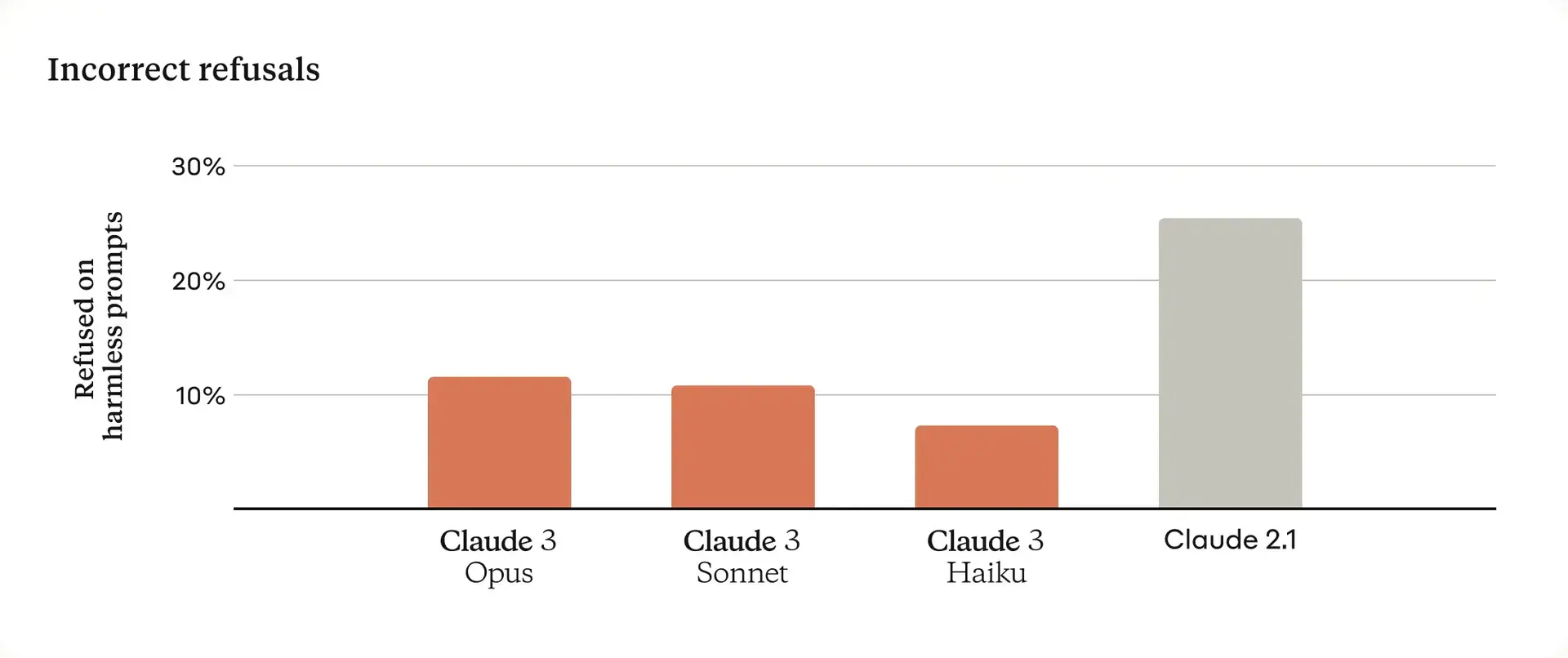
Claude 3拒絕回應的頻率已明顯降低,並會對問題表現出更細緻的理解能力。
例如以下測試:
 |
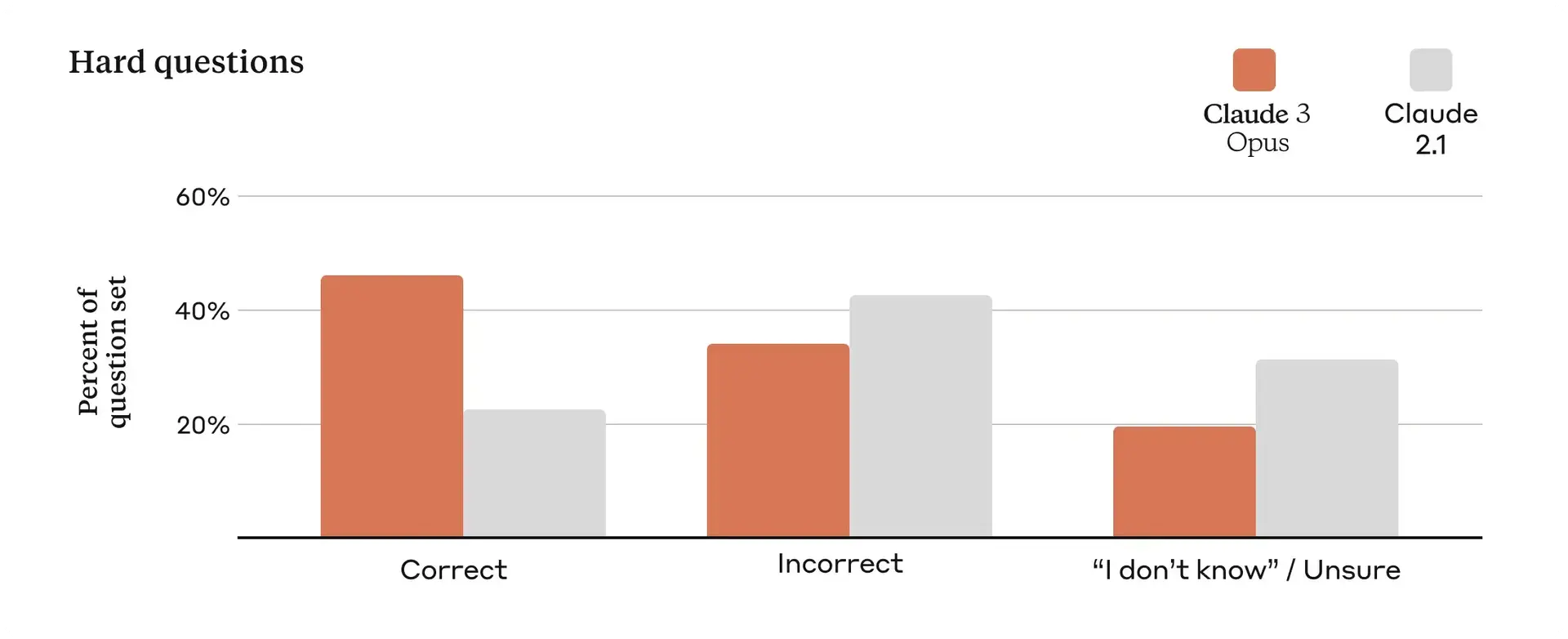
Claude 3在準確性方面與Claude 2.1相比,Opus模型的準確度提高了一倍,並減少幻覺(hallucinations)的產生。
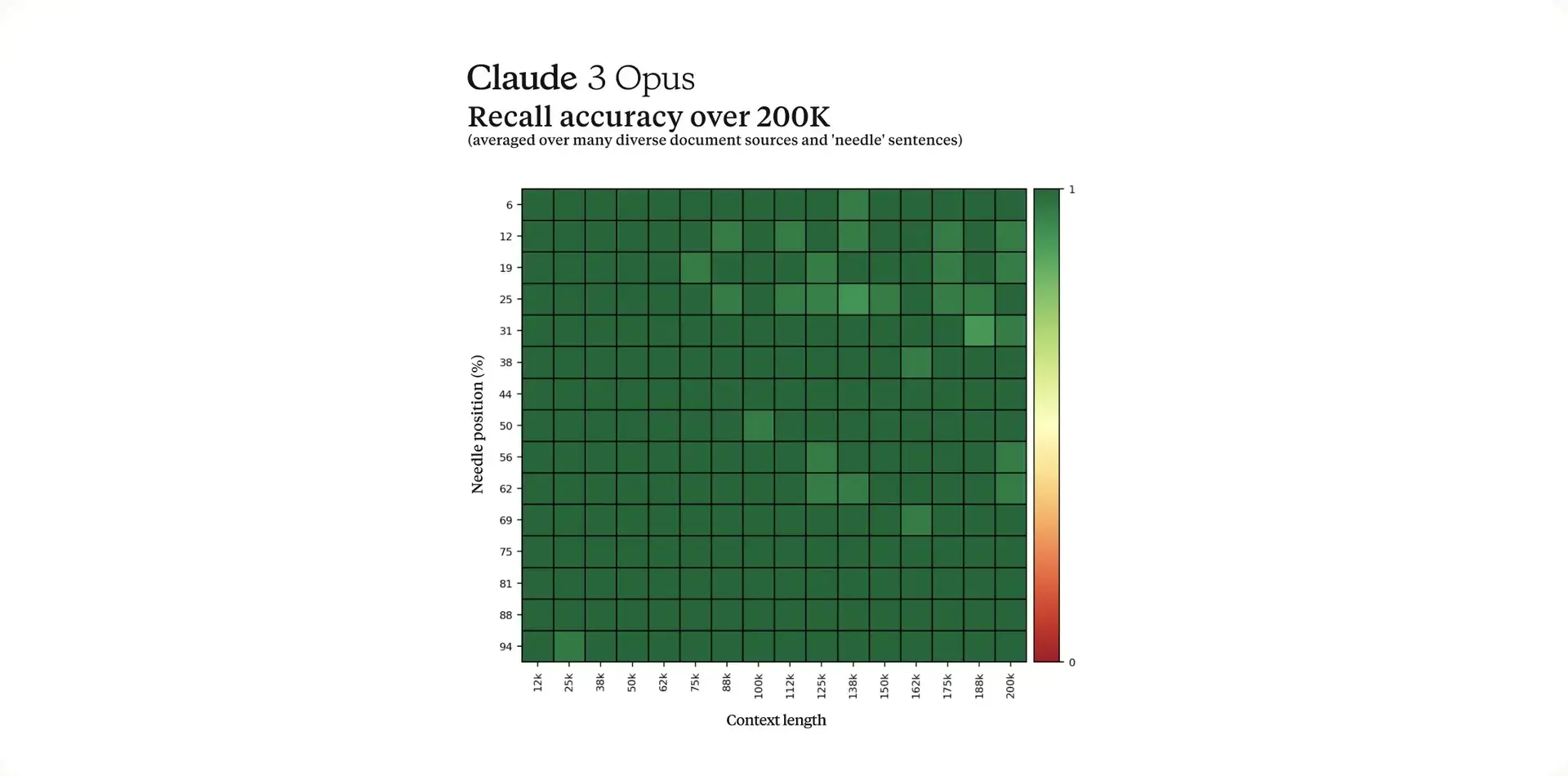
Claude 3一開始將提供200K的上下文窗口,並且三種型號(Haiku、Sonnet、Opus)都支援處理超過100萬Tokens的資料輸入。
為了有效的處理長上下文prompts,模型需要有強大的回憶能力,因此採用「Needle In A Haystack(大海撈針)」(NIAH)評估(在Paper的5.8.2 Needle In A Haystack)測試模型從龐大資料中準確回憶資訊的能力,在測試中Claude 3 Opus展現出近乎完美的recall(召回率)跟超過99%的accuracy(準確率),甚至能識別出測試本身的侷限性,從大量文本中判斷出人為插入的句子。
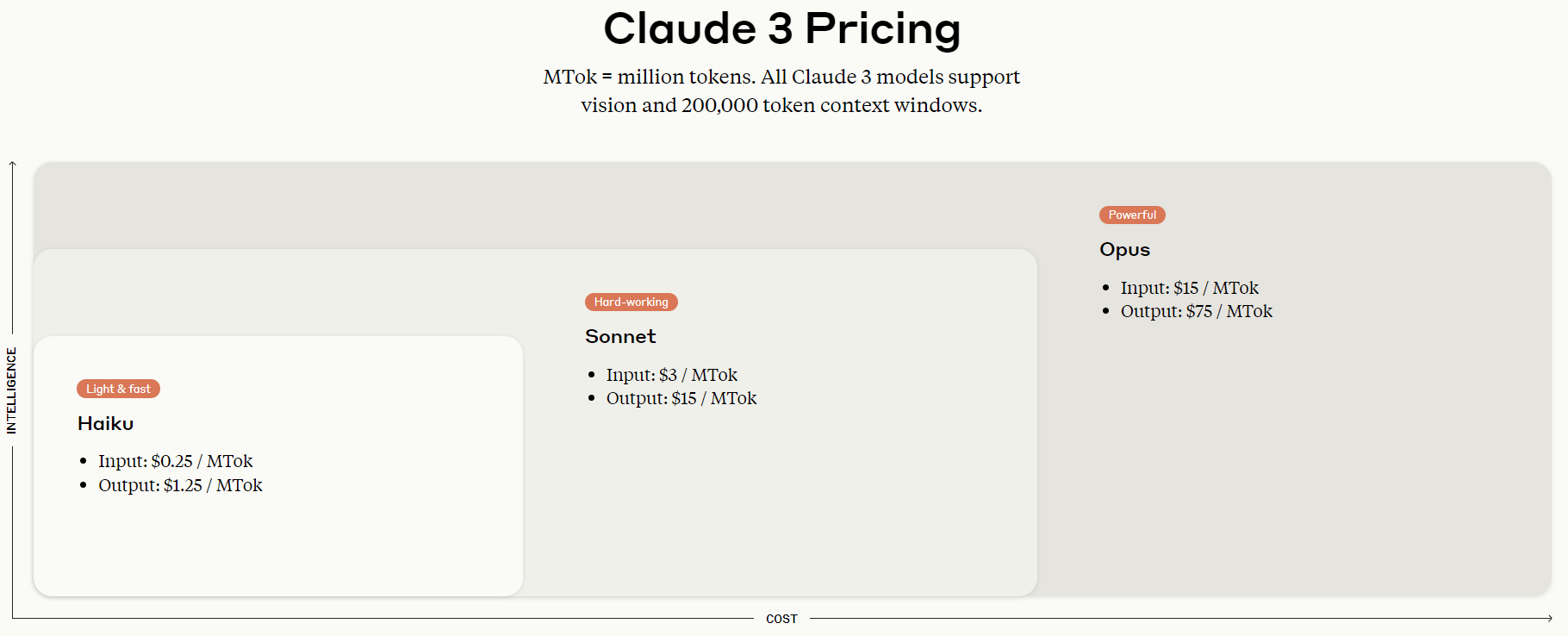
API價格:
| 模型 \ 價格 | Input (MTok) | Output (MTok) |
| Claude 3 Opus | $15 | $75 |
| Claude 3 Sonnet | $3 | $15 |
| Claude 3 Haiku | $0.25 | $1.25 |
使用途徑:
- Claude 官方 API:Opus、Sonnet、Haiku
- Amazon Bedrock:Sonnet、Haiku
- Google Cloud Vertex AI - Model Garden (Model Garden):Sonnet、Haiku

Blog / 相關消息:
- 官方Blog
- Paper
- Claude 3聊天介面 (免費版為第二大的Sonnet模型,付費版的為最強大的Opus模型)
- Claude API
- Haiku型號已於2024/03/14推出:
相關X(Twiiter)推文:
玩玩Claude 3 Sonnet:

持續更新...