大致介紹有哪些新功能:
> 更強大的GPT-4模型,訓練資料終於來到2023年(4月),支援圖像、128K的Token輸入(相當於300頁左右的文字內容),最大的輸出Token數量為4,096個,強化JSON mode,新增seed參數使輸出一致化,比GPT-4更便宜的價格...等,目前許多搭配新的TTS模型的應用(Example)

> 運作原理
> Playground馬上體驗Assistants API測試版
> 開發大會展示
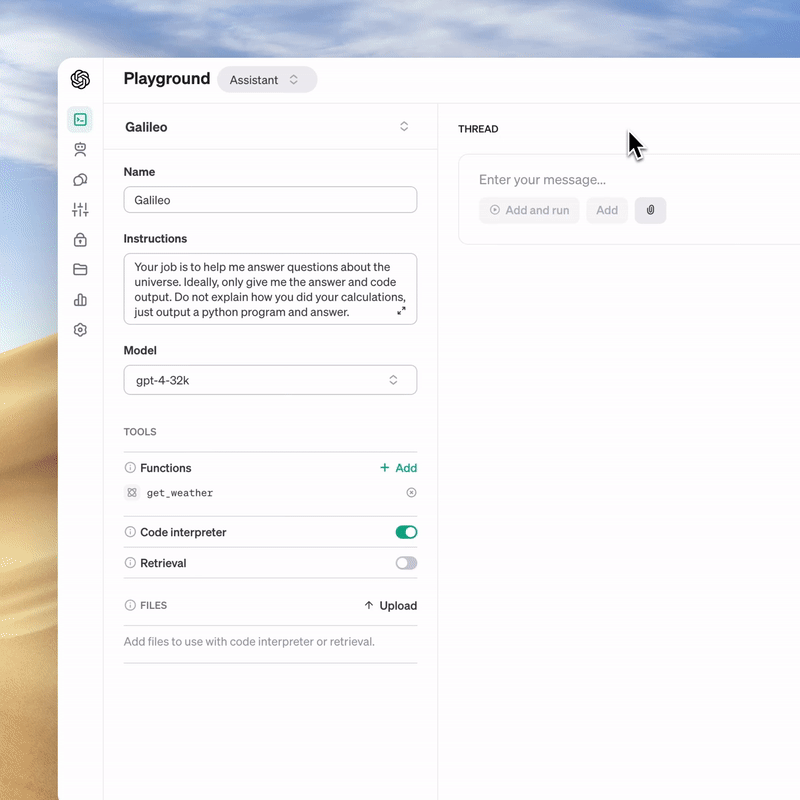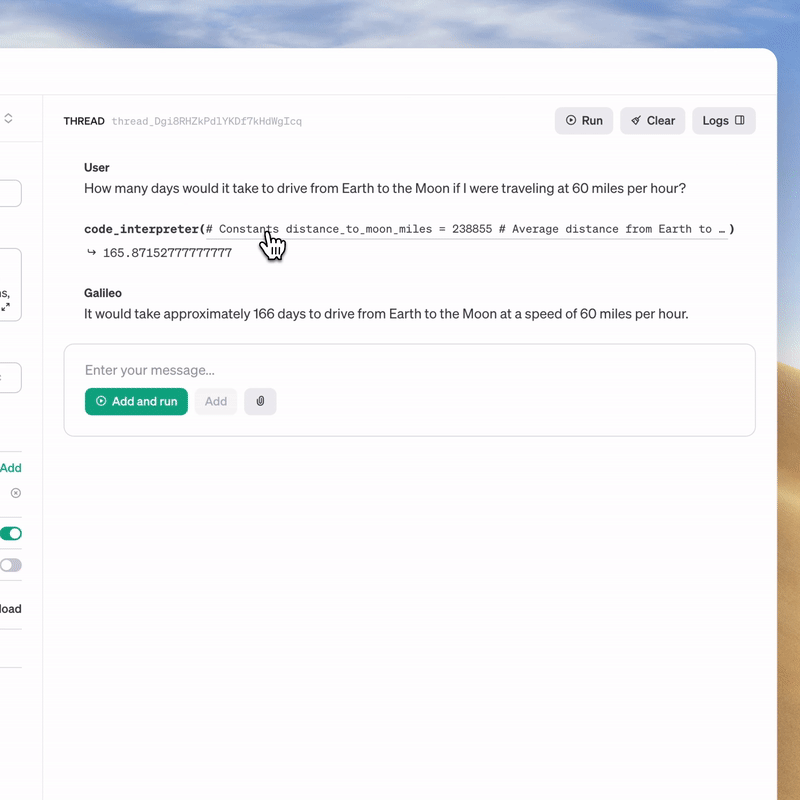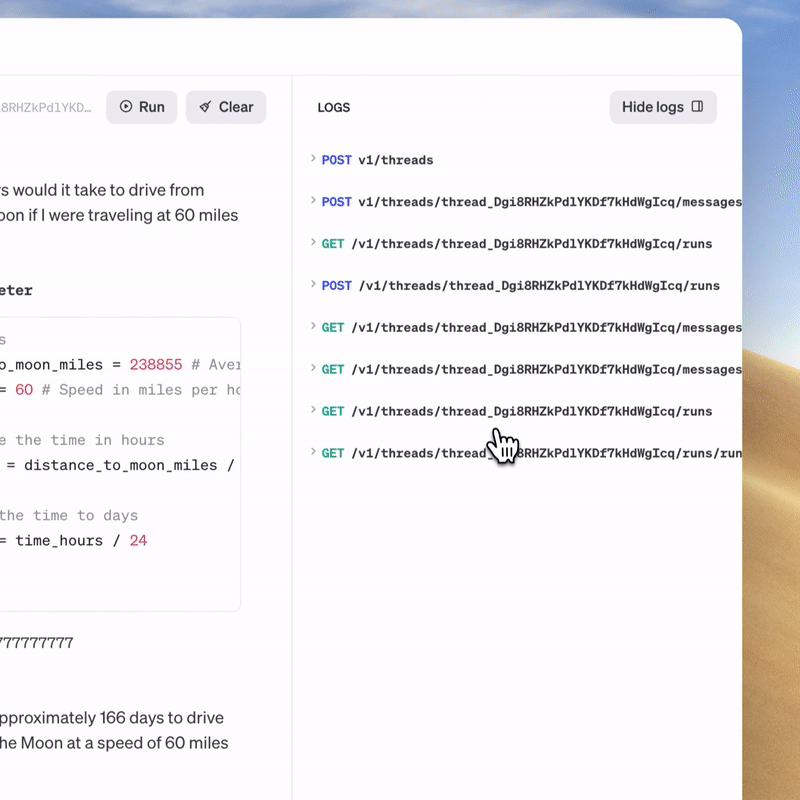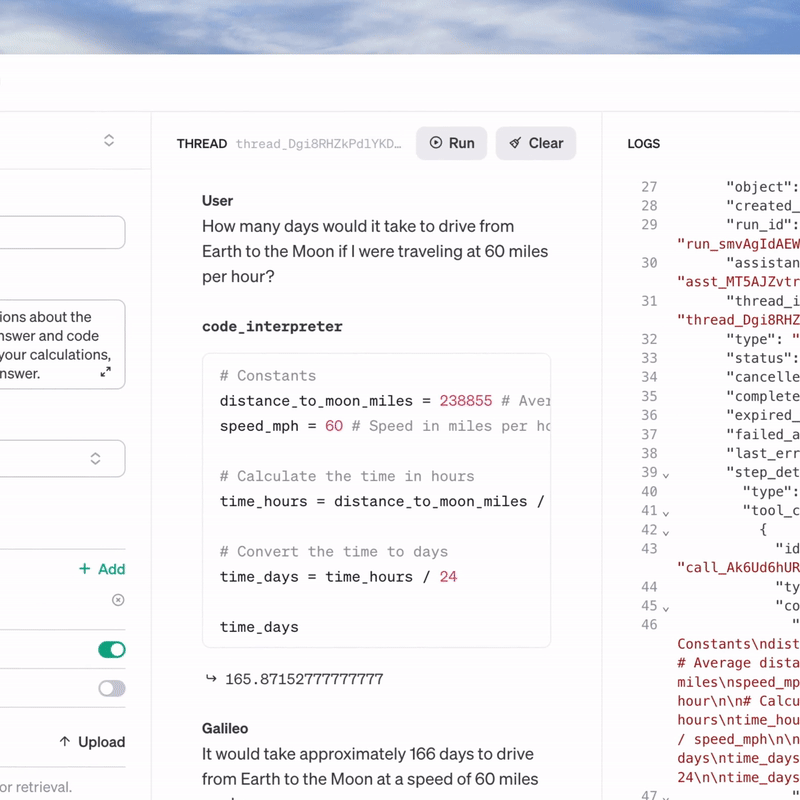
> 可生成人類品質的語音,內建了6種語音選擇與2種模型變體(tts-1、tts-1-hd)...
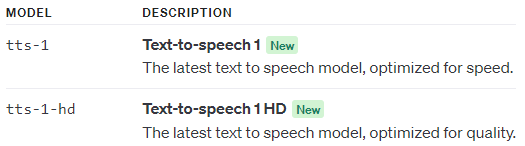
> tts-1針對速度進行優化,tts-1-hd則是針對品質優化
4. 新的語音辨識ASR模型(Whisper large-v3)
> Github
> 與前一代的模型相比,使用了128個Mel frequency bins而不是80個,並改進了跨語言的表現...

5. VAE的改進版(Consistency Decoder)
> 與傳統Stable Diffusion的VAE比較,在文字、臉部和直線方面有明顯的改善,但看了許多人試用後的效果並沒有太好,歡迎嘗試
> Automatic1111即將支援




6. GPTs (無程式碼客製化GPT)
> 無須編寫程式碼,訓練出屬於自己的客製化GPT,也可供企業內部使用,並且即將推出GPT商店(各個創作者所製作的GPT)可讓創作者進行營利
> 目前僅提供ChatGPT Plus、Enterprise用戶使用