下一個教學是使用貼圖,但開始指揮顯卡少女工作之前先介紹一些shader的知識。
其他程式教學請看這篇目錄
Shark流程式教學一覽
顯卡少女主要是利用兩個技術做到高速運算:
1是平行處理,顯卡少女做的工作天生就適合平行處理。
2是SIMD (單指令多資料,single instruction, multiple data)
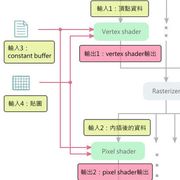
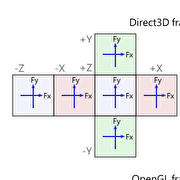
如下圖,只用vertex shader和pixel shader,不用其他shader的情況下,輸入有4種,輸出有2種
(本系列目標版本是Direct3D 11 feature level 10和OpenGL 3.3,較早的版本有其他方式就不介紹了)

輸入1:頂點資料,每個vertex shader會分配到一個頂點。
輸出1:vertex shader輸出,之後rasterizer會內插,讓polygon裡每個像素分配到一個值,再變成pixel shader的輸入。
輸入2:內插後的資料,通常可以直接把vertex shader的輸出作為pixel shader的輸入。
輸出2:pixel shader輸出,輸出畫面上的顏色。
輸入3. constant buffer (OpenGL稱為uniform buffer)
還有幾種比較特別的constant buffer和貼圖,現在先不詳細介紹,初學階段先不要記太多東西免得混亂,而且筆者目前也都沒用到。
D3D有tbuffer型態的buffer、Buffer型態的貼圖,OpenGL有buffer texture,這幾種在C/C++端是buffer物件,但在顯示記憶體裡視為貼圖儲存,特性也比較像貼圖:容量上限較大,編譯後GPU要用讀取貼圖的指令來讀取。
有找到這篇文件講到cbuffer與tbuffer的效能測試,它說tbuffer比較慢,如果容量夠用就儘量使用cbuffer。
DirectX Constants Optimizations for Intel? Integrated Graphics
D3D feature level 11和OpenGL 4.2以後新增了可讀也可寫的texture和buffer,如何防止多執行緒存取同一個資料出錯,程式師要自行負責。
本文D3D部分的color theme是Kimbie Dark,OpenGL的是Obsidian,這兩種比較單一色系,不像Monokai和Breeze Dark用了多種顏色。兩者好像原本都是先用在某個軟體,後來被移植到很多軟體上。
VS code安裝好之後就有內建Kimbie Dark,Obsidian有很多人做了很多版本,這兩個是筆者認為比較好看的。
(Actual) Obsidian Son of Obsidian Theme
KWrite的可以在KDE store下載
Obsidian Monokai
Kimbie Dark好像還沒有人做出來
其他程式教學請看這篇目錄
Shark流程式教學一覽
顯卡少女主要是利用兩個技術做到高速運算:
1是平行處理,顯卡少女做的工作天生就適合平行處理。
處理頂點資料時,各個頂點分配到自己的資料之後就各自跑程式計算,每個頂點並不需要知道其他頂點的資料;處理像素也一樣,rasterizer求出哪些像素被polygon覆蓋後,各個像素就各自執行pixel shader、depth test、blend,每個像素不需要知道其他像素的情況,所以GPU可以搭載幾十~幾千個處理單元,一次處理幾十~幾千個頂點或像素。
但想利用平行處理會有一些限制,multi thread程式的常識是,兩個thread同時修改一個變數,或一個thread讀一個thread寫的話,由於無法預測哪個thread會先做,無法預料最後讀到或寫入的值是什麼,但多個thread讀同一個變數是沒問題的。
vertex shader和pixel shader只能更新它被分配到的頂點或像素,假如能更新其他頂點或像素就有兩個處理單元寫入同一個變數的問題。
後述的constant buffer和貼圖由於是所有shader共用一份,顯卡少女只能讀不能寫,只能由電子妖精更新。(D3D和OpenGL比較新的版本有可寫的buffer和貼圖,但程式師要自己設法防止衝突)
還有貼圖(被shader讀取)和framebuffer(被shader寫入)如果是同一張點陣圖,雖然D3D和OpenGL不會阻止你這樣設定,但這樣是同時讀和寫一塊資料,無法預料執行結果會怎樣。
最後,CPU和GPU是兩個晶片獨立運作,電子妖精發出指令後就繼續執行自己的程式,不會等物體被畫出來才繼續。如果GPU正在忙碌,驅動程式會先把指令和資料暫存,等適當時機才送給GPU。
這也是顯卡少女做的工作的特性,大部分時候只有CPU傳資料給GPU,很少需要反方向傳資料,但如果呼叫一個GPU傳資料給CPU的函式,會等暫存的指令都做完才繼續。
2是SIMD (單指令多資料,single instruction, multiple data)
如果有四組數字要算乘法,一次計算一組需要四個指令。
在晶片裡增加一種暫存器,一次儲存四個數字,然後增加一次對整個暫存器計算的指令,一個指令就可以同時計算四組乘法。
至於能不能四個數字做不同操作,大概要考慮電路製作難度以及跟舊有指令配合的問題,不是所有操作都能做到,要晶片廠商有實作出指令才能用。
GPU的計算有很多是「一次對多組數字做相同計算」,剛好適合用SIMD處理,顏色RGBA和坐標XYZW都是四個數字,稱為四維向量。
「float[4]」可以說是顯卡少女的基本資料型態,shader裡的暫存器基本上都是四維向量,一次計算一個float也是做得到,但這是只用暫存器的一個分量,另外三個分量閒置;而且用整數計算不會比浮點數快,GPU是對浮點數特化的晶片,這點跟CPU不一樣。
SIMD技術不是只用在GPU,CPU也有這類指令,如x86的MMX和SSE、ARM的NEON,不過shader的程式語言對SIMD的支援比較好,能用比較簡單的寫法、支援比較多操作。如果在C/C++裡使用SSE,要做這些操作就比較費事。
//將分量調換順序(swizzle)
a.xxy = b.rgb;
//產生一個四維向量,x,y=a的x,y分量,z,w直接給數字
c = float4(a.xy, 0, 1); //HLSL寫法
c = vec4(a.xy, 0, 1); //GLSL寫法
/*宣告4列3欄,像這樣的的矩陣
┌* * *┐
│* * *│
│* * *│
└* * *┘
*/
float4x3 m; //HLSL寫法
mat3x4 m; //GLSL寫法
分量可以寫成xyzw或rgba,兩者差別只有程式可讀性,讓人看得出這個變數是坐標還是顏色,編譯後會變成相同的指令。



如下圖,只用vertex shader和pixel shader,不用其他shader的情況下,輸入有4種,輸出有2種
(本系列目標版本是Direct3D 11 feature level 10和OpenGL 3.3,較早的版本有其他方式就不介紹了)
輸入1:頂點資料,每個vertex shader會分配到一個頂點。
輸出1:vertex shader輸出,之後rasterizer會內插,讓polygon裡每個像素分配到一個值,再變成pixel shader的輸入。
至於程式寫法,HLSL要寫成main函式的參數或傳回值,輸入要加上in保留字,輸出加上out。變數名稱後面帶有:P、:T、:C、:SV_Position這些的稱為semantics,用來將C++、各階段shader之間的資料對應。
//資料少的時候可以這樣寫
float4 vsMain(in float2 pos:P) :SV_Position {
return float4(pos, 0, 1);
}//有多項資料時,寫成struct比較方便
struct VsIn{
float2 pos :P;
int2 texCoord :T;
float4 color :C;
};
//後面帶的:P、:T、:C是對應到C++端的input layout設定
struct VsOut{
float4 svPos :SV_Position;
float2 texCoord :T;
float4 color :C;
};
//這部分的:T、:C跟pixel shader的輸入對應
//vertex shader進入點
//「in VsIn IN」的意義是「保留字in, 資料型態VsIn, 變數名稱IN」
void vsMain(in VsIn IN, out VsOut OUT) {
OUT.texCoord=IN.texCoord;
OUT.color=IN.color;
OUT.pos=float4(IN.pos, 0, 1);
}
輸出一定要有:SV_Position,就是「Direct3D與OpenGL的繪圖管線(上)」講到的vertex shader輸出,X,Y是畫面上的坐標,Z用在depth test,W在內插時產生近大遠小的效果。
系統內建的semantics不分大小寫,寫成sv_position、SV_POSITION、sv_pOsiTioN也可以。
非內建的semantics D3D9會要求你寫成特定的名稱如POSITION、TEXCOORD,有些D3D10、D3D11的教學也會這樣寫,但其實可以用任意名稱。
GLSL要寫成全域變數,輸入用in保留字,輸出有兩種寫法,用out保留字或varying保留字。畫面坐標使用內建變數gl_Position輸出,GLSL有一些內建變數表示系統特殊的值,不用宣告就能使用。
layout(location=0) in vec2 inPos;
layout(location=1) in vec2 inTexCoord;
layout(location=2) in vec4 inColor;
//layout(location=?)是對應到C/C++端的vertex array object設定
//要內插的資料,寫法1
varying vec2 varTexCoord;
varying vec4 varColor;
//寫法2
//out vec2 varTexCoord;
//out vec4 varColor;
//vertex shader進入點
void main(){
varTexCoord=inTexCoord;
varColor=inColor;
gl_Position=vec4(inPos, 0, 1);
}
輸入2:內插後的資料,通常可以直接把vertex shader的輸出作為pixel shader的輸入。
輸出2:pixel shader輸出,輸出畫面上的顏色。
HLSL會把semantics跟vertex shader的輸出比對,相同semantics會視為相同的變數。
這裡SV_Position的X,Y分量變成這個像素在螢幕上的位置,單位是像素。pixel shader輸出是用SV_Target。
struct VsOut{
float4 svPos :SV_Position;
float2 texCoord :T;
float4 color :C;
};
//pixel shader進入點
float4 psMain(in VsOut IN):SV_Target {
float4 texColor=texture1.Sample(sampler1, IN.texCoord);
return texColor*IN.color;
}
目前還沒用到一次輸出至多個framebuffer的功能,如果有用到,要寫成陣列SV_Target[0]、SV_Target[1]、……。
GLSL輸入可以用in或varying保留字,link時會跟vertex shader輸出比對,把名稱相同的視為相同的變數。
varying是比較早期版本的寫法,現在OpenGL wiki只有介紹in、out的寫法。輸出使用內建變數gl_FragColor是比較早的方法,現在OpenGL wiki只有介紹out的方法。
//寫法1
varying vec2 varTexCoord;
varying vec4 varColor;
//寫法2
//in vec2 varTexCoord;
//in vec4 varColor;
//輸出除了gl_FragColor以外也可以這樣寫
//layout(location = 0) out vec4 outColor0;
//layout(location = 1) out vec4 outColor1;
//fragment shader進入點
void main(){
vec4 texColor=texture(sampler1, varTexCoord);
gl_FragColor=texColor*varColor;
}
輸出至多個framebuffer要用gl_FragData[0]、gl_FragData[1]、……。
用手上的晶片測試,現在的OpenGL仍然可以用varying和gl_FragColor,OpenGL ES則是只能用in、out。但我不確定有沒有晶片是一定不能用舊方法,用in、out比較保險。
D3D11的內建semantics都以SV_開頭,OpenGL的內建變數都以gl_開頭,所有能用的內建的值如下,有很多,但常用的並不多。
Direct3D這篇把9~11的都列出來,會讓人搞混,只有「System-Value Semantics」的部分是D3D10和11的。
MSDN: System-Value Semantics
OpenGL wiki: Built-in Variable (GLSL)
輸入3. constant buffer (OpenGL稱為uniform buffer)
所有階段的shader都共用的一組資料,shader裡不能修改它們,因為如果其中一個執行單元修改它,其他執行單元就會讀到錯的值,只有主程式可以上傳資料。這種輸入要注意的是C/C++怎麼宣告對應的資料。輸入4. 貼圖(texture)
HLSL裡用cbuffer保留字宣告,用:register()指定編號,然後用大括號寫類似struct的宣告。
//「register(b0)」用來跟C++的物件對應
//「cbuffer0」這個名稱無實際作用
cbuffer cbuffer0 :register(b0){
float4x3 transformMatrix;
float4 effectColor;
int autoTexCoordType;
int textureFormat;
};
//把上面宣告的當成全域變數使用
float4 someFunction(){
……
float3 outPos = mul(inPos, transformMatrix); //HLSL的矩陣乘法要用mul()函式
float4 outColor = inColor*effectColor;
……
}
GLSL用uniform保留字宣告如果沒有「layout(std140)」,變數在記憶體裡的位置不一定按照程式裡寫的,系統會看情況調換順序節省空間和效能,主程式必須呼叫一些函式查詢變數的位置。有加「layout(std140)」寫程式比較方便。
//「ubuffer0」的名稱用來跟C/C++的物件對應
layout(std140) uniform ubuffer0{
mat3x4 transformMatrix;
vec4 effectColor;
int autoTexCoordType;
int textureFormat;
};
/*
如果是4.2版以後或是有擴充功能「GL_ARB_shading_language_420pack」,
可以這樣寫,直接在shader裡指定編號
layout(std140, binding=0) uniform ubuffer0{
*/
//把上面宣告的當成全域變數使用
void main(){
……
vec3 outPos = inPos*transformMatrix; //GLSL的矩陣乘法可以用乘號
vec4 outColor = inColor*effectColor;
……
}
然後C/C++裡宣告一個對應的struct,建立物件與傳送資料的方法在別篇介紹。
struct {
float transformMatrix[12];
float effectColor[4];
int32_t autoTexCoordType;
int32_t textureFormat;
} constantBuffer0;
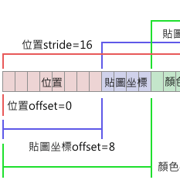
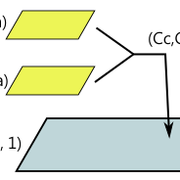
變數在記憶體裡的位置會按照你寫的順序,不過要注意對齊。constant buffer裡的資料是以float[4](16 bytes)為單位,如下圖,本篇暫且把一個float[4]稱為暫存器。
shader裡一個向量不能跨過兩個暫存器,必要時變數會被往後挪。例如在記憶體裡的位置如下:
//HLSL
cbuffer cbuffer0 :register(b0){
float2 d1;
float3 d2;
float2 d3;
float d4;
};//GLSL
layout(std140) uniform ubuffer0{
vec2 d1;
vec3 d2;
vec2 d3;
float d4;
};
C/C++裡宣告struct就要自己補上dummy資料。
struct {
float d1[2];
float dummy1[2];
float d2[3];
float dummy2;
float d3[2];
float d4;
} constantBuffer1;
把順序調換一下,需要的空間就比較少
//HLSL
cbuffer cbuffer0 :register(b0){
float2 d1;
float2 d3;
float3 d2;
float d4;
};//GLSL
layout(std140) uniform ubuffer0{
vec2 d1;
vec2 d3;
vec3 d2;
float d4;
};//C/C++
struct {
float d1[2];
float d3[2];
float d2[3];
float d4;
} constantBuffer1;
shader與C++資料型態的對應大部分很直覺,只有陣列和矩陣比較要注意,以下是一部分資料型態。
C/C++ HLSL GLSL float
float[2]
float[3]
float[4]float
float2
float3
float4float
vec2
vec3
vec432位元浮點數,1~4個分量 int32_t
uint32_tint
uint
boolint
uint
bool32位元整數,一個分量
整數2~4個分量請自行類推float m[8]; float4x2 mat2x4 4列2欄矩陣,佔用的buffer空間如下 矩陣是這種形狀
m[0] m[1] m[2] m[3] m[4] m[5] m[6] m[7]
┌[0] [4]┐
│[1] [5]│
│[2] [6]│
└[3] [7]┘float m[14]; float2x4 mat4x2 2列4欄矩陣,佔用的buffer空間如下 [2]、[3]、[6]、[7]、[10]、[11]變成空間浪費
m[0] m[1] m[4] m[5] m[8] m[9] m[12] m[13]
只有第四個暫存器右邊兩格可放其他變數
因此儘量讓非正方形矩陣是縱長形,比較節省空間float a[14]; float2 a[4] vec2 a[4] 長度4,元素的型態是float2的陣列,佔用的buffer空間如下 不論陣列元素是幾維向量,一個元素都佔一個暫存器
a[0] a[1] a[4] a[5] a[8] a[9] a[12] a[13]
如果元素大小是5~8個float則會佔兩個暫存器,依此類推



跟constant buffer一樣是記憶體裡的一塊區域,不一定真的是圖,也可以把非圖片的數值資料存在貼圖物件裡。
與constant buffer的差別如下取樣器第一個作用是貼圖被放大、縮小、旋轉時可做柔化處理,稱為texture filtering,有的地方把它翻譯成紋理過濾。
- constant buffer可以存多種資料型態,容量上限較小,貼圖是一個資料型態重覆多次,容量上限較大。
D3D的文件有寫,一個constant buffer最大是4096個float[4],貼圖大小上限隨feature level而異,feature level 10可以到8192×8192個像素。- 必須用專用的指令讀取,速度比constant buffer慢。
- 可以使用取樣器(sampler)。
shader裡下「取得貼圖裡(0.353, 0.155)的像素」之類的指令時,NEAREST模式是只取一個像素,LINEAR模式是取出鄰近的4個像素平均。
(這張範例圖是下一個範例程式會用到的)
縮小在有些情況下只靠4個像素平均還是不太好看,會有閃爍和雜訊等問題,要用mipmap和anisotropic filtering(各向異性過濾)這兩個技術解決。
第二個作用是連續鋪排。使用取樣器讀取像素時,不論原圖大小貼圖坐標都是0~1的浮點數,如果貼圖坐標填其他數值,0~1以外的部分有以下5種處理方式:
(方括號內是OpenGL的名稱,左邊是Direct3D的名稱)
不過這要一次用整張貼圖時才有用,如果是只取出貼圖的一部分,就不能用這個功能做連續鋪排了,因此依筆者經驗這個功能派上用場的機會不多。
shader裡使用貼圖的方法,HLSL要分別宣告texture物件和sampler物件這篇SamplerType的項目列了很多sampler種類,但它把D3D9~11的全部列出來,會讓人搞掍,D3D10,11的只有兩種:SamplerState和SamplerComparisonState。
//宣告貼圖與sampler物件
Texture2D<float4> texture1 :register(t0);
SamplerState sampler1 :register(s0);
//register(t0)、register(s0)用來與主程式的物件對應
float4 psMain(in VsOut IN) :SV_Target {
……
//用這個函式讀取貼圖
float4 texColor = texture1.Sample(sampler1, texCoord,xy);
……
}
MSDN: Sampler Type
GLSL的sampler物件是把貼圖和sampler包在一起
//宣告sampler物件
//OpenGL 4.1以前的寫法,如何對應到主程式的物件是在主程式呼叫函式設定
uniform sampler2D texture1;
/*
如果是4.2版以後或是有擴充功能「GL_ARB_shading_language_420pack」,
可以這樣寫,直接在shader裡指定編號
layout(binding=0) uniform sampler2D texture1;
*/
void main(){
……
//用這個函式讀取貼圖
vec4 color = texture(sampler1, texCoord.xy);
……
}
讀取貼圖的指令種類繁多,除了以上基本的指令,還有不自動判斷mipmap,自行指定mipmap層數;以及不做texture filtering,只讀取一個像素等等,以後實際用到再介紹。
有興趣的話下面有列出全部的讀取貼圖指令,可以自己看。
MSDN: HLSL Texture Object
OpenGL wiki: Sampler (GLSL)


還有幾種比較特別的constant buffer和貼圖,現在先不詳細介紹,初學階段先不要記太多東西免得混亂,而且筆者目前也都沒用到。
D3D有tbuffer型態的buffer、Buffer型態的貼圖,OpenGL有buffer texture,這幾種在C/C++端是buffer物件,但在顯示記憶體裡視為貼圖儲存,特性也比較像貼圖:容量上限較大,編譯後GPU要用讀取貼圖的指令來讀取。
有找到這篇文件講到cbuffer與tbuffer的效能測試,它說tbuffer比較慢,如果容量夠用就儘量使用cbuffer。
DirectX Constants Optimizations for Intel? Integrated Graphics
D3D feature level 11和OpenGL 4.2以後新增了可讀也可寫的texture和buffer,如何防止多執行緒存取同一個資料出錯,程式師要自行負責。
本文D3D部分的color theme是Kimbie Dark,OpenGL的是Obsidian,這兩種比較單一色系,不像Monokai和Breeze Dark用了多種顏色。兩者好像原本都是先用在某個軟體,後來被移植到很多軟體上。
VS code安裝好之後就有內建Kimbie Dark,Obsidian有很多人做了很多版本,這兩個是筆者認為比較好看的。
(Actual) Obsidian Son of Obsidian Theme
KWrite的可以在KDE store下載
Obsidian Monokai
Kimbie Dark好像還沒有人做出來