通勤滑手機(jī),看到有趣的心理測驗,就丟到DC群。
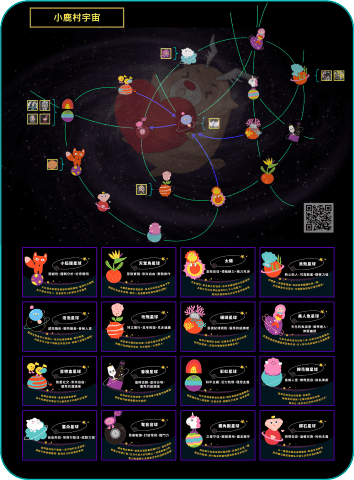
意外滿多人回覆,就想說整理一張全體的圖出來。
不過問題是,網(wǎng)站並沒有給出所有測驗結(jié)果的圖片,
只能自己去做試驗蒐集結(jié)果。
本來想說應(yīng)該試個幾次應(yīng)該可以試出來,
不知道是結(jié)果分配不均,還是運(yùn)氣不好,總之就是缺了四種。
已經(jīng)耗掉一天,無奈之下,還是只能搬出爬蟲來搞。
總之,最後有把圖弄出來:
動態(tài)爬蟲
主要函式庫:selenium
說明:
前一次只需要分析靜態(tài)頁面,找到位置,抓到對應(yīng)物件的資料即可。
這次不同,需要回答12個問題,點擊後讓頁面跳轉(zhuǎn),是動態(tài)的爬蟲。
因此需要webdriver─透過程式碼下指令,模擬實際網(wǎng)頁的各項操作。
每個瀏覽器的架構(gòu)都不同,也因此各自用到的webdriver也不同。
這邊我用到的是chrome,就是去載chromedriver。
流程:
driver = webdriver.Chrome() #開啟chromedriver
driver.get(url) #連上特定網(wǎng)頁
driver.find_element(By.CLASS_NAME, 'XXX').click() #找到物件,並執(zhí)行點擊
然而一開始就卡關(guān),馬上就頭大了起來。
最討厭搞這種環(huán)境設(shè)置的各種問題。
難關(guān)1:版本問題
即使是同一個瀏覽器,也會因為版本不同,對應(yīng)的webdriver也不同。
解法:(都弄到最新最方便)
把瀏覽器更新到最新,然後也抓最新版的chromedriver。
難關(guān)2:路徑問題
不知道為何,明明把chromedriver跟程式碼的檔案放在同一個資料夾,
就是抓不到chromedriver,一直跟我講沒有driver用。
想了一下,可能是抓底層設(shè)置,也就是python的位置,而找不到chromedriver。
解法:(直接指定路徑)
加了一行,指定路徑,並把參數(shù)丟到driver裡
s = Service(r"C:\......\chromedriver.exe")driver = webdriver.Chrome(service=s)
難關(guān)3:延遲問題
因為頁面跳轉(zhuǎn)時,畫面讀取的時間差,程式往下跑的時候,可能畫面資料還沒讀完,
結(jié)果就導(dǎo)致物件抓不到,引發(fā)錯誤,程式停擺。
解法:(設(shè)置延遲)
利用休眠,讓程式碼等網(wǎng)頁讀取完後再跑。
精進(jìn):time.sleep(1)
然而這個時間不好抓,每次執(zhí)行必須停等的時間會依據(jù)網(wǎng)路讀取速度而定。
等於是設(shè)定的越短,觸發(fā)錯誤的機(jī)率越大;
但設(shè)定太長,又會導(dǎo)致整體執(zhí)行時間過長。
可能寫成錯誤發(fā)生的例外,再延長停等時間,重複嘗試,更好。
圖片儲存
因為要把測驗的結(jié)果記錄下來,
而結(jié)果頁面是以圖片呈現(xiàn),等於要把圖抓下來。
方法1:GUI操作
函式庫:pyautogui
程式碼:
action = ActionChains(driver).move_to_element(result) # 移動到該元素action.context_click(result) # 右鍵點選該元素action.perform() # 執(zhí)行pyautogui.typewrite(['v']) # 敲擊V進(jìn)行儲存#單擊圖片另存之後等1s敲確認(rèn)time.sleep(1)pyautogui.typewrite(['enter'])
方法2:Image
函式庫:PIL
程式碼:
img_content = requests.get('http://...')
說明:img = Image.open(io.BytesIO(img_content)).save(filename)
用於可直接取得圖片網(wǎng)址的情形。
且不將圖片儲存,也可以直接對圖片內(nèi)容進(jìn)行後續(xù)其他操作。(去除.save段)
難關(guān)4:http之外的圖片"網(wǎng)址"
然而,網(wǎng)路圖片居然還有網(wǎng)址之外的表示方式,好死不好就遇到了。
大概是這種形式:"data:image/png;base64,...",也就是所謂的data URI。
解法:(資料型態(tài)轉(zhuǎn)換)
多寫兩行,將資料以byte的形式儲存,再用base64去解碼。
b = bytes(img_src, 'utf-8')img_content = base64.b64decode(b)
圖轉(zhuǎn)文字
然而,做到一半覺得好像沒必要存成圖片,浪費(fèi)空間。
因為重點是圖片中顯示結(jié)果種類的關(guān)鍵幾個字而已。
又想到已經(jīng)有圖轉(zhuǎn)文字的模組可以用。
主要函式庫:pytesseract
說明:
跟webdriver一樣,直接指定路徑。
pytesseract.pytesseract.tesseract_cmd = r'C:\Program Files\Tesseract-OCR\tesseract.exe'
難關(guān)5:缺中文模組
不給予任何參數(shù)的情況下,會以英文為預(yù)設(shè)來汲取文字。
而中文必須於安裝時,有選取才會安裝額外的模組。
解法:(補(bǔ)上模組)
最快就整個重裝,要勾選到中文模組。
並且於使用時,指定用繁體中文來解析。
text = pytesseract.image_to_string(img, lang='chi_tra')
資料輸出
主要函式庫:pandas
程式碼:
df = pd.DataFrame(data=article_info_row_data, columns=columns)df.to_csv('./test_pandas.csv', index=0, encoding='big5')
說明:
把資料裝一裝,然後用輸出成CSV檔。
難關(guān)6:亂碼
解法:(更改編碼)
就是試錯,本來以為應(yīng)該是用網(wǎng)頁內(nèi)容的UTF-8格式,
但既然是中文,就big5丟進(jìn)去試試,然後就正常顯示了。
實際執(zhí)行
難關(guān)7:Anaconda 閃退無法開啟
因為前面各種碰壁,寫了一個段落,想說隔天再來跑執(zhí)行。
結(jié)果過了一晚Anaconda 就爆炸,莫名其妙開不起來。
解法:(重灌)
萬金油,就是全部重來,然後就又可以執(zhí)行了。
之後發(fā)現(xiàn),好像是硬碟的某個部分壞掉,剛好是Anaconda 的資料夾位置。
難關(guān)8:執(zhí)行時間過長
也就是前面提的休眠時間的問題。
12個問題,總共4096種組合,
相較於機(jī)械學(xué)習(xí)動不動就5、6位數(shù)組的訓(xùn)練資料,感覺很少。
但實際上,休眠時間設(shè)定的關(guān)係,一組也要跑個30秒左右,
也就是4096組需要2048分鐘,也就是34小時多,超過一天。
解法:(無)
其實也不是沒有,就前面講的,可能弄成例外情形去處理,盡量最小化休眠時間。
精進(jìn):
另外,應(yīng)該階段性輸出資料,不然跑到一半停電甚麼的...時間就白等了。
還好一次就順順的成功。
難關(guān)9:資料錯誤
最後出來的資料只有三種測驗結(jié)果,顯然是有某個環(huán)節(jié)出錯,但是無法得知是甚麼問題。
可能是對於time.sleep() 理解上的錯誤,譬如程式碼實際是有先往下跑,導(dǎo)致接連後續(xù)的迴圈都是同樣的值,而使CSV輸出的值有誤。
解法:(切分執(zhí)行區(qū)塊)
結(jié)果還是半手動的方式,一小塊一小塊去執(zhí)行,然後也老老實實的存圖檔,看有沒有問題。
很幸運(yùn)的抓出漏掉的四種結(jié)果就不跑了。
原本是想測出4096種組合的結(jié)果,看16種性格的分布情形。
可是在做的時候,發(fā)現(xiàn)名稱不同好像也會導(dǎo)致結(jié)果受到影響...
等於是有第13個變項,詳細(xì)又要做更多試驗,
因為只是個支線任務(wù),所以就作罷了。