

之前講到了標準差,
標準差就是指一組數據的離散程度。
在討論機率分部的時候,
我們很喜歡講所謂的「常態分布」,
並且會說 ±1 標準差下的機率為 68%,
±2 標準差下的機率為 95% 等等,
這邊的 ±1 顯然是有先決條件的。
舉例來說,
假設臺灣人中年男性的身高成常態分佈,
如果平均數是 175 公分,
按照上述例子描述,
代表有 68% 的人身高介於 174~176 公分之間,
有 95% 的人身高介於 173~177 公分之間。
按照常態分佈公式,
±6 個標準差以外的佔比為十億分之二,
換句話說,
身高低於 169 公分或身高高於 181 公分的人每五億人才有一個,
這顯然與事實不符對吧?
因此身高的標準差絕對不是 1 公分。
如果說,
連身高這種簡單的統計都不能使用標準常態機率分佈去求解,
那這個標準常態機率分佈又有什麼普適性可言?
因此呢,
我們需要對數據進行一個「修正」。
不同的數據,
自然會有不同的平均數與標準差,
因此要與常態機率分佈做匹配,
就需要進行平移與縮放。
標準差的定義:

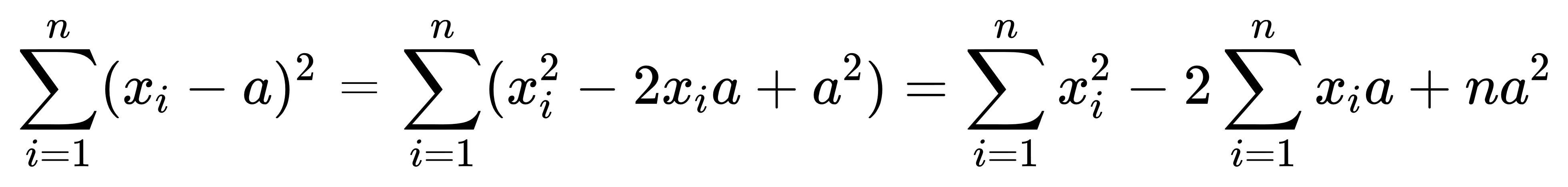
先將加總像獨立出來討論,
首先將括弧展開,
依照家法交換律的定義,
先合併再求和跟個別求和再合併意思相等,
因此將他分解成三項。
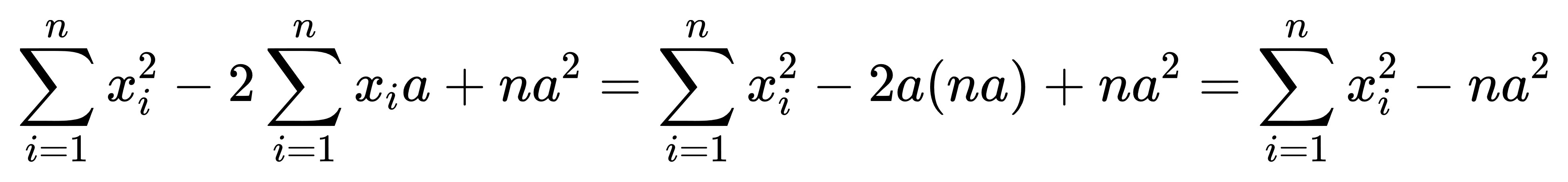
中間項,
因為平均數的定義是所有元素數值的總和去除以元素個數,
因此所有元素數值的求和自然等於平均數乘以元素個數,
因此最終我們能進一步化簡。
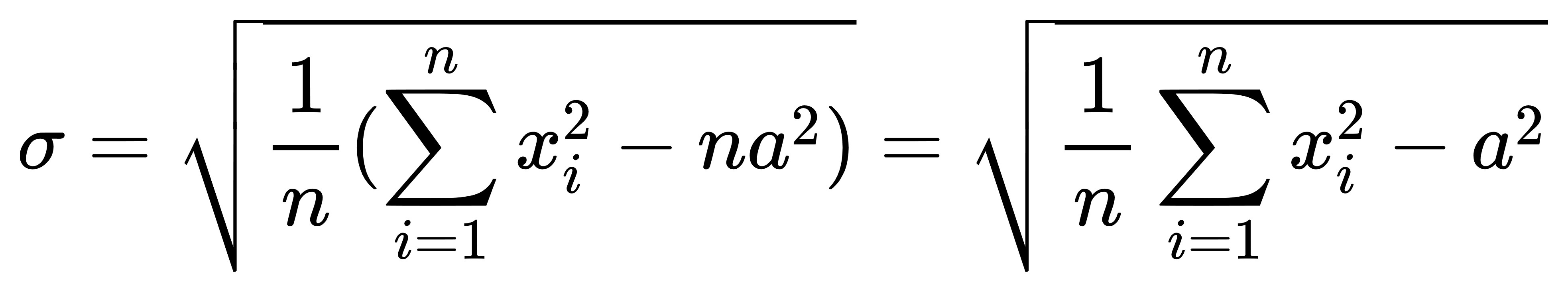
最後將結果帶回原定義,
可以得到最終簡化的結果。
我們來做一個代換:
定義一組新數據 y,
當中的每一項 yi 都是 xi-c ,
c 為相等的任意常數,
那麼我們就會得到這個公式:
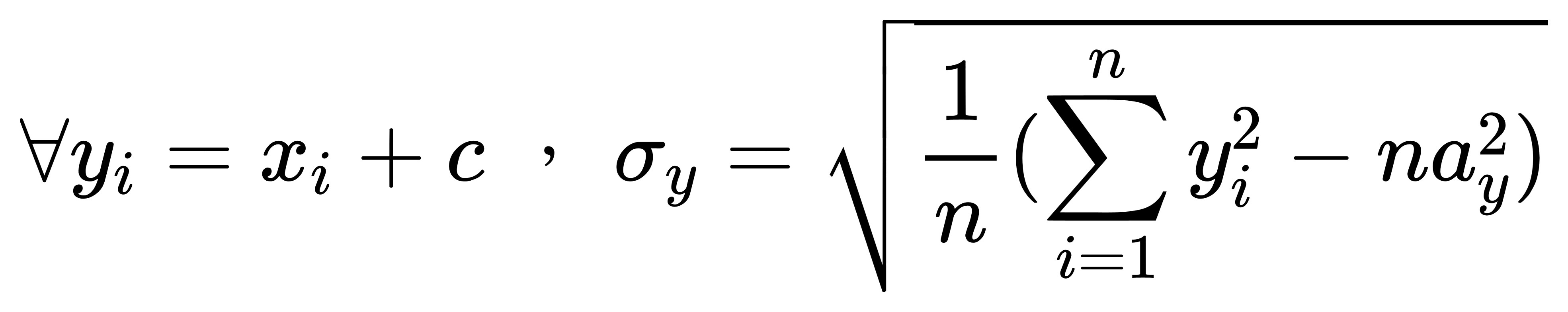
將 yi 用 xi+c 帶入:
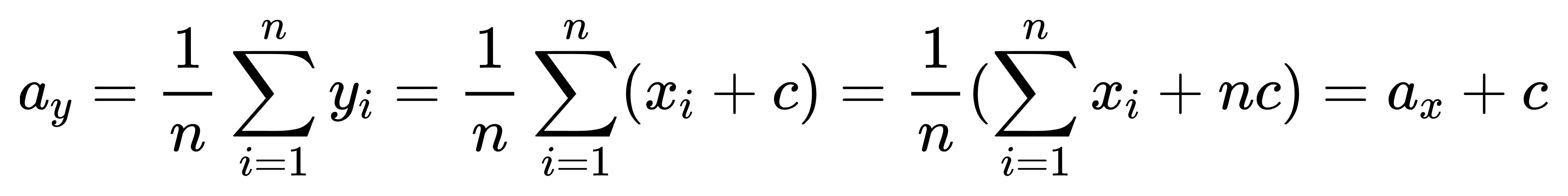
有了這些就能回頭求標準差:
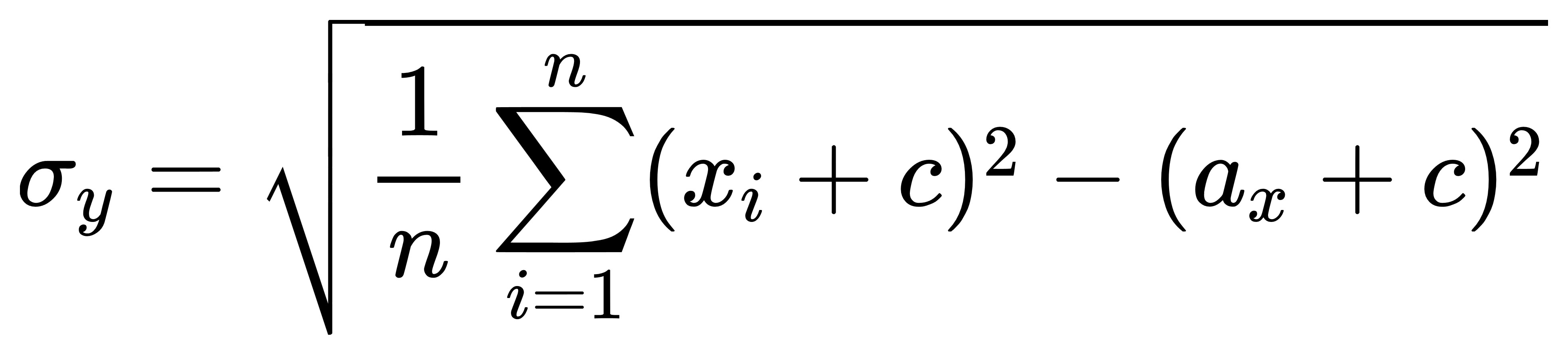
先求根號下面的東東: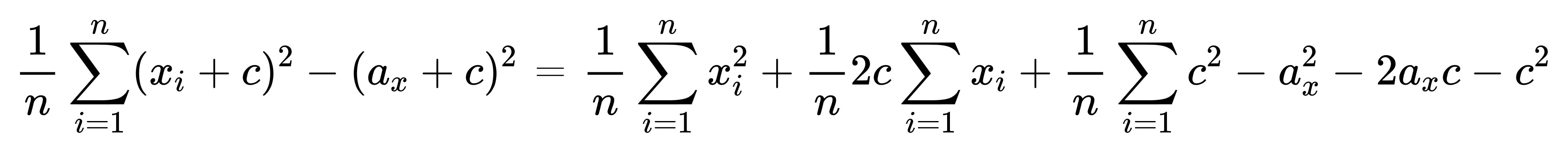
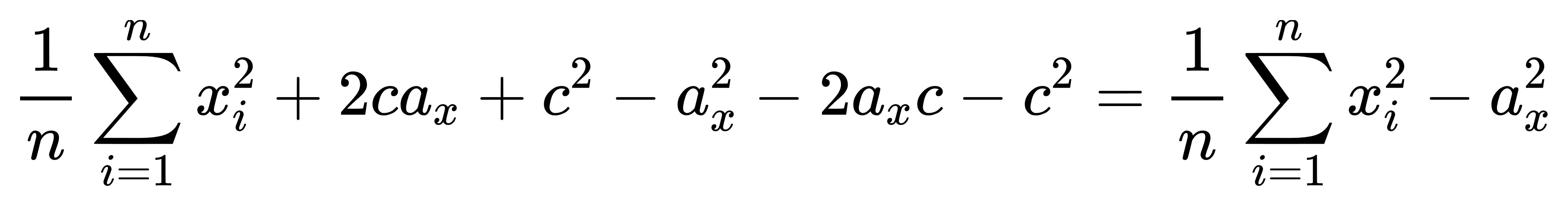
有沒有注意到,
根號裡面的東西,
化簡後那個 c 會不見。
於是:
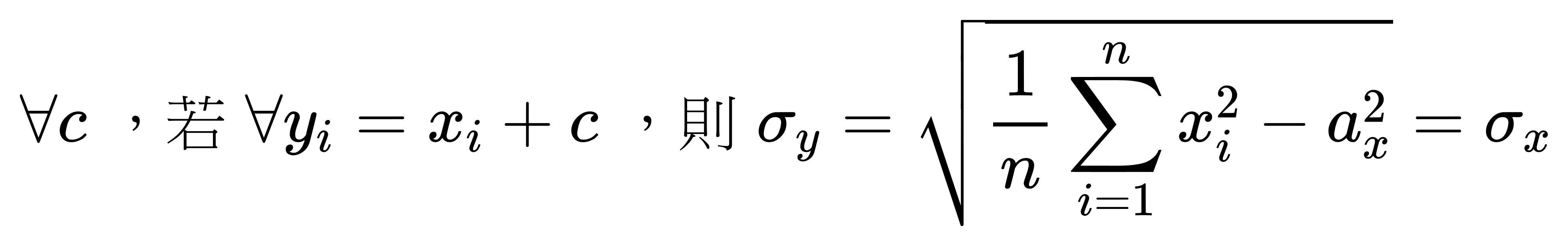
由此可知,
如果我們對樣本裡的每一個數據都共同加減一個常數的話,
其標準差是不變的。
接著我們做另一個代換,
如果定義一組新數據 zi=mxi,
則:
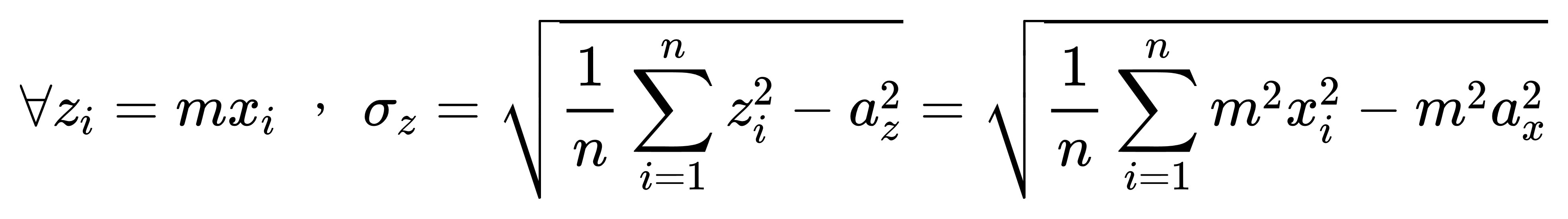
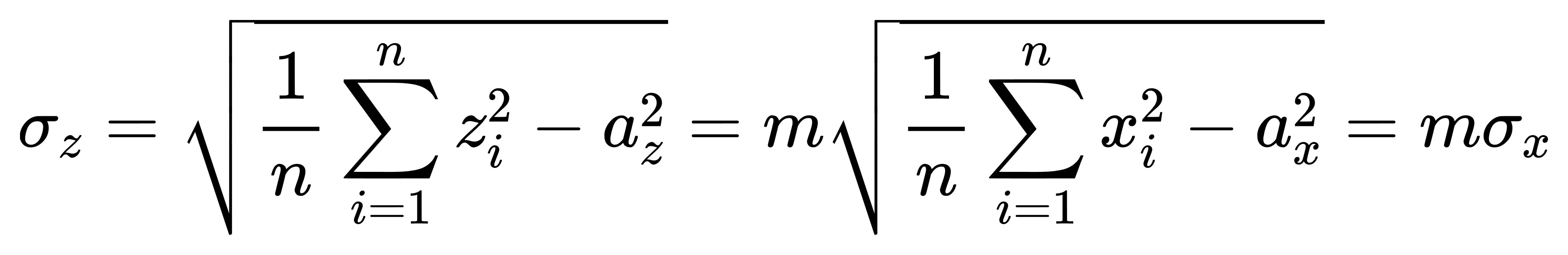
換句話說,
把數據乘以 m 倍,
標準差也會等比例放大 m 倍。
綜合以上兩個代換,
我們發現,
不論你的原始數據為何,
對原始數據做等量運算的結果,
我們可以將原始數據轉變為標準常態機率分佈的形式。
利用這一點,
如果假設臺灣人身高標準差為 5 公分,
那麼我們把所有人的身高都先減去 175 公分後再除以 5 公分,
我們就會得到一個平均數為 0 公分且標準差為 1 的數據。
這個數據剛好就可以套進標準常態機率分佈裡面,
機率分佈告訴我們有 99.7% 的機率位於 ±3 個標準差的範圍內,
換句話說,
身高小於 -3 或者大於 3 的人平均每 1000 人當中只有 3 人。
身高小於 -3 是什麼概念?
別忘了我們這組數據是先減去 175 公分後再除以 5 公分,
因此我們要反著做回去。
先乘以 5 公分再加上 175 公分,
換句話說,
身高小於 -3,
意思就是身高低於 -3×5+175=160 公分,
換句話說,
每 2000 個成年男性只有 3 個人身高低於 160 公分的意思。
標準差的平移與縮放,
其目的單純就是為了與標準常態分佈去做匹配而已。
雖然背後有一套嚴謹的數學證明,
但是為什麼能這麼做,
不要去管什麼數學了,
咱用邏輯去想就好:
如果是一組完全相同的數據,
那麼標準差一定也是相同的,
這應該不會有異議吧?
那麼我們就給你一組數據,
人體的體溫平均值是攝氏 37 度,
標準差是攝氏 1 度的話,
那麼同一組樣本,
如果改用「絕對溫標」或「華氏溫標」,
理論上標準差也應該同樣都是「攝氏 1 度」對吧?
那麼「攝氏 1 度」是絕對幾度?
答案是「1 開爾文」。
而「攝氏 1 度」是華氏幾度?
答案是「華氏 1.8 度」。
我們來看數據,
攝氏溫標轉絕對溫標,
直接把攝氏度的讀數 +273 就好,
因此這組體溫數據,
相當於把裡面的所有元素的數字加上 273。
這不就恰巧表明了,
當一組數據裡面的所有數字都加減了一個常數,
其標準差不會改變嗎?
同樣的,
攝氏溫標轉華氏溫標,
做法是把攝氏溫標的讀數 ×1.8 後再 +32,
因此這組體溫數據相當於要先放大 1.8 倍。
由於攝氏 1 度等於華氏 1.8 度,
所以標準差從攝氏 1 度變成華氏 1.8 度,
這不就恰巧表明了,
當一組數據裡面的所有數字都等比例乘上一個係數時,
標準差也會等比例乘上一個係數嗎?
至於後面那個 +32 當然也是壓根就不會影響標準差。
不過與標準差類似的,
還有另一個指標叫做變異係數。
先說定義,
變異係數的公式為:

之前說過,
標準差的單位與數據相同,
平均數也是,
因此變異係數正如其名,
它是一個無因次的純係數。
由於變異係數受到平均數的制約,
所以會有所限制:
很顯然的,
平均數不能是零。
如果平均數是零,
那分母為零,
變異係數就會失去定義。
除此之外,
就算平均數不為零,
趨近於零的情況下也會令變異係數趨近於無窮大,
同樣失去意義。
因為這個制約,
所以變異係數在對於「有正有負」的數據統計上相對不具意義,
例如選手的得失分(得分為正、失分為負的話)等。
然而一個工具被發明出來必然有其用處,
事實上從定義去看就不難發現,
變異係數的定義,
實際上就是「標準差對平均數的占比」的意思。
前面提到,
對數據進行平移不會改變標準差,
但是對數據進行平移卻會改變平均數,
因此變異係數「無法平移」。
以體溫來說,
同樣標準差為 1 攝氏度,
如果用平均數為攝氏 37 度來做,
那麼變異係數是 37 分之 1,
大約是 0.027;
用絕對溫標來做,
那麼變異係數是 310 分之 1,
大約是 0.003;
而使用華氏溫標來做的話,
變異係數是 986 分之 18,
大約是 0.018。
明明是同樣一組數據,
變異係數卻不相同,
因為變異係數是無因次的純係數單位,
因此必須嚴格定義原始數據才能得到有用的值。
事實上,
變異係數因其特性的關係,
他只能用來統計「等比尺度」的統計量。
所謂「等比尺度」的意思是指「原點為零的統計量」,
絕大多數的物理量都是等比尺度,
但上面的例子,
因為「攝氏溫標」與「華氏溫標」的零點都不是原點,
不符合等比尺度的定義,
所以使用變異係數來統計就會出問題。
相反,
絕對溫標就是等比尺度,
因此使用絕對溫標來表示體溫數據的話,
這個變異係數才會有其意義存在。
那麼變異係數有什麼活用的地方呢?
因為變異係數無因次的特性,
這也意味著他不會受到單位的影響。
因此當你要比較不同單位數據的優劣時,
使用變異係數就能作為一個相對的參考項目。
例如,
成年男性平均身高 175 公分、標準差 5 公分;
成年男性平均體重 70 公斤、標準差 3 公斤,
問你成年男性的身高跟體重哪一個的離散程度比較大?
這兩筆數據使用不同的單位,
你不管使用平均數、中位數、標準差、變異數、全距還是四分位距等等指標,
都會因為單位不同而陷入無法比較的情況,
因此在這裡就只能使用變異係數來分析。
這題,
身高的變異係數為 35 分之 1,
約為 0.029;
體重的變異係數為 70 分之 3,
約為 0.043。
換句話說,
體重的離散程度是比較高的。
變異係數提供了一個指標,
用來判斷數據的「相對變化性」。
即使是同樣的單位,
這個相對變化性根據切入問題的角度不同,
也許也會有截然不同的結果。
例如,
某個人因為要根據當月的工作狀況支薪,
平均的月薪只有 20000 元,
標準差 5000 元,
這意味著這個人的收入很不穩定。
他最好的情況可以收入到 35000,
但最差的情況可能只有 5000,
是非常不穩定的狀態;
同樣的,
一個非常有錢的人,
他每個月平均可以領到 200 萬,
只是有時候可以多拿一點獎金,
有時候少拿一點獎金,
標準差一樣是 5000 元,
那麼,
對這個人來說,
領 201 萬跟領 199 萬有很明顯的差別嗎?
因此同樣的標準差,
對這個人來說卻反而是非常穩定的狀態。
這兩人的收入穩定程度,
我們無法單從平均數或標準差裡看出來,
但卻能從變異係數裡找到端倪。
這些案例表現出,
變異係數與標準差有不一樣的統計意義,
因此必須依照統計目的來決定要使用的統計指標,
並沒有說哪一個指標就一定比較好。

封面圖片:AI生成的粗因米菇
本篇使用的方程式編輯素材來自:LaTeX公式編輯器


















































