碩士差不多快畢業(yè)了 想說來紀錄一下順便分享一下自己的碩士研究
主題:以Deep Reinforcement Learning 訓練 Graph Neural Network 並應用在 Flexible Job Shop Scheduling Problem
前言:
JSP 問題其實是一個再多一點限制的 TSP,然而 TSP 已經(jīng)有很多很強的方法了(LKH 之類的),JSP 也是有許多用 Genetic Algorithm (GA)、Tabu Search (TS) 或直接數(shù)學方法 (e.g. Mixed Integer Linear Programming, MILP) 求 exactly 解。但用 RL 來做 (F)JSP 算是一個滿新的(?)題目,去年末某一篇一樣做 GNN-DRL-FJSP 的研究 (DAN) 也只拿了一篇說是S.O.T.A. 的2022發(fā)表的方法作為比較對象,從這點就可以看出這類方法的研究是多麼稀少了。
問題簡述:
JSP
你有一些 Job 跟 Machine,每個 Job 都各有好幾個 operation 要按順序做,每個 operation 各自可以在某一臺指定好的機器上執(zhí)行,你要適當?shù)嘏?operation 到 machine 上。
Flexible JSP
Flexible的部分則是 operation 可以有多個機臺的選擇
方法:
那麼這類研究目前要做的事有哪些呢?
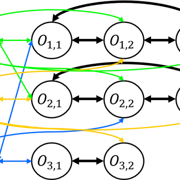
1. 如何將(F)JSP 轉(zhuǎn)成 Graph G=(V,E) 的形式,包含了你要怎麼設計 node,edge 要怎麼連
2. Node feature 的設計
3. GNN 的架構
4. Action probability 的計算
5. Training 方法
前四項就是在想辦法設計一個不錯的 graph extractor,不確定有沒有理論可以去證明怎樣的設計是最好的 (但我想應該是沒有(?)),其實都有點 try & error, 算是把自己對於問題+環(huán)境機制理解透徹之後試著表達出自己對於 JSP/FJSP 的看法,另外也都可以從實驗中慢慢找到一些端倪。
至於訓練方式的話其實蠻難搞的==,因為你實在不知道是 graph extractor 弄太爛還是訓練方式不對,所以這邊是先借用其他研究的訓練方式來確保 graph extractor 沒問題後當作一個 baseline,再來想自己的訓練方式。
至於 Residual scheduling 的核心究竟是什麼呢?
就是在1. 的時候把已經(jīng)被排到機器上的 operation 從我們的問題中移除。
對,聽起來就是一個很直覺的想法而也真的是一個很簡單的想法…… 但從 L2D (2024) 到我們 RS (2024) 發(fā)表前沒看到類似的研究這樣做 (或是有但我沒 survey 到),而這一個簡單的想法讓我們模型表現(xiàn)有一個還不錯的提升 (優(yōu)於上述提到的 2022 年的 S.O.T.A.) & 運算上更快 & 對等等要講的未來展望還蠻有用的
(*其他方法大多是在2. 的時候把該 operation node 的 feature中標為‘已排程’ 之類的)
剩下的就是 node feature 的設計,想一想如果自己手動要排的話會想知道那些資訊;以及神經(jīng)網(wǎng)路的架構 (GNN、Action probability network),也想一下經(jīng)過 GNN 吐出來的那些 feature 究竟代表了甚麼來去調(diào)整 架構。
結果:
目前的結果是這篇 Residual scheduling。 在 JSP 和 FJSP 上表現(xiàn)都還不錯,都優(yōu)於同類的研究方法。
有投過NIPS ,reviewer 也都給到至少 board line accept ,但可惜最後被刷掉,其實比想像還要好 XD
原本想說會直接被 reviewer 評 reject。後來轉(zhuǎn)投 IEEE-access 還是成功有發(fā)表出去~
附錄:
這類方法被稱為 construction heuristic 也就是一個一個做選擇並且不會回頭去調(diào)整已經(jīng)排好的部分,另外 GA、TS 這種用不斷把排程優(yōu)化的方式稱為 improvement heuristic,JSP 上目前有一個 GNN DRL + improvement heuristic 叫做 L2S ,一群專攻這類問題的學者,滿猛的。
這類方法被稱為 construction heuristic 也就是一個一個做選擇並且不會回頭去調(diào)整已經(jīng)排好的部分,另外 GA、TS 這種用不斷把排程優(yōu)化的方式稱為 improvement heuristic,JSP 上目前有一個 GNN DRL + improvement heuristic 叫做 L2S ,一群專攻這類問題的學者,滿猛的。
未來展望
其實 RS 的概念很簡單,就是看現(xiàn)在到底還有哪些 operation 沒排,把他們留在 graph 上。所以其實延伸到 Dynamic FJSP 上我們也預期 RS 應該要能 work (目前做起來覺得是可以,但還沒公開研究內(nèi)容)。
何謂 Dynamic FJSP?
real-world 其實更貼近 Dynamic FJSP,排程過程總會遇到一些突發(fā)狀況,如:
1. 新的 job 進來了
1. 新的 job 進來了
2. machine 遇到故障
3. 這個 operation 需要再多一點點時間給他
4. 這單 job 被取消啦
.
.
之類的非常多種不同的狀況,目前研究中的是 1, 2 算是很常遇到的狀況。
Dynamic FJSP 這邊研究會遇到一個問題是: "沒有公開測試 datasets",畢竟大家設計的突發(fā)狀況非常多樣化,所以幾乎都各自做各自的,頂多提供自己如何模擬產(chǎn)生突發(fā)狀況。
於是自己要想辦法模擬產(chǎn)生突發(fā)狀況,這邊又有一個問題: "自己這樣模擬產(chǎn)生的方法,會讓問題足夠困難嗎?",也就是說,長期持續(xù)性的模擬環(huán)境會不會讓你機器的數(shù)量跟工作的數(shù)量的比例會不會過多或過少 (新 job 來的速度 v.s. 你機器消耗 job 的速度) ,太多太少都是不行的,所以這邊要處理的問題實在是比想像的還要多QQ。不過這個問題我目前也是直接去用期望值算一下如何去設置模擬環(huán)境,還算是有得到不錯的結果,如果之後有要發(fā)表的話可能也會特別拉出來講說該如何設置一個難度剛好的環(huán)境。