主題
 達人專欄
達人專欄
製作動機
學校現(xiàn)有的課表查詢系統(tǒng)為教務處的教務資訊系統(tǒng),其有幾個缺點:
- 無法正確回傳使用者所設定的區(qū)間的資料(例如使用者僅查詢第 7、8 節(jié)的課,系統(tǒng)卻會回傳 5~8 節(jié)的課)
- 無法合併查詢(例如使用者不能同時查詢五專部與四技部的課程)。
因此本專案特別針對該問題進行改善,架設查詢網(wǎng)站,除了提供使用者更好的搜尋外,也額外開放 API 與檔案存取,將校務資訊作成開放資料以方便未來開發(fā)者。
備註:原本是爬蟲課堂作業(yè),後來想說乾脆延伸做個完整查詢介面
成品展示網(wǎng)頁:https://lontoone.github.io/Nutc_Cls/
網(wǎng)頁API:https://lontoone.github.io/Nutc_Cls/#/api/?&(串接查詢參數(shù))
程式一樣可以在個人網(wǎng)站摳
網(wǎng)站外觀

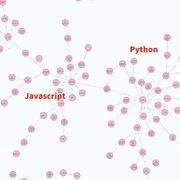
架構
下圖為本專案系統(tǒng)架構,包含基於React框架之前端介面、API網(wǎng)址查詢、Python爬蟲腳本、與彙整後的資料庫SQLite。csv檔可有可無,保留輸出與輸入csv的功能是為了(1.)方便查看爬蟲結果、(2)若csv檔案存在則優(yōu)先從csv匯入資料至SQLite,就不需要進行爬蟲、(3)給老師檢查用。
((使用SQLite而非真正的DB是因為我懶得架後端(x

下圖為本專案執(zhí)行流程,為了方便做到一鍵更新資料,我在RunUpdate.py寫了cmd指令,使其自動執(zhí)行爬蟲與更新至線上網(wǎng)站資料,若要手動爬蟲可單獨執(zhí)行scrap.py。

關於自動執(zhí)行程式與上傳github的指令我以前的網(wǎng)站用過一樣的方式,這次加點os語法讓路徑不會那麼死。

Python 爬蟲
以往我會直接從網(wǎng)頁傳輸(Network Log)中尋找該網(wǎng)頁回傳純資料的API call,但經(jīng)過嘗試後仍無法理解學校教務系統(tǒng)所回傳的資料格式,因此只好使用URL Query。

(回傳的資料找不太到規(guī)律。)
以這串查詢網(wǎng)址為例:
參數(shù)說明如下:
l sem表學期,例如1111為第111學年上學期;1112為下學期。
l sch_type表學制,0=全部、1=五專、3=二技、4=四技、8=碩班。
l weekday表星期,1~7分別表星期一到星期日。
l start_section表開始節(jié)。
l end_section表結束節(jié)。
l _p表頁數(shù)。
網(wǎng)頁資料架構

除了第一排tr是表頭外,其餘tr內的td所代表之資料順序如下:

該資料有兩個問題點:(1.) 部分資料被合併顯示成一筆資料:例如 星期一第1~3節(jié) (3708) 、(2.) 數(shù)字有的為全形:例如 3 / 3。分別需使用Regex拆資料與將全形轉半形。

取得最大頁數(shù)
為了知道爬蟲範圍,需要取得最大頁數(shù),而教務處網(wǎng)站的最大頁數(shù)藏在「>>」符號的url最後一個參數(shù)中。

先透過BeautifulSoup找出頁碼最後一個元素,再用Regex得到_p參數(shù)值。

爬蟲主邏輯

寫入CSV
為了方便,我統(tǒng)一在物件內寫好回傳欄位屬性與值的方法:

就能直接讀取keys()或values()作為欄位與值。

寫入SQLite


初步預覽:

Web前端與SQLite
使用Sql.js套件讀取Sqlite檔案。由於前端讀取檔案需要引入fs插件,但React v5以後禁止引入node.js的fs,因此本專案前端使用React v4版開發(fā)。
使用React V5會出現(xiàn)這個ERROR:
BREAKING CHANGE: webpack < 5 used to include polyfills for node.js core modules by default.初步設定SQL.js
安裝

引入sql.js wasm
在上一篇Unity文章中,我們探討Assembly的使用,而Wasm(WebAssembly)概念類似,可以想像成給瀏覽器的Assembly檔案。
從官網(wǎng)下載wasm檔,並引入。

查詢與回傳方法
基於安全,瀏覽器禁止js程式直接讀取路徑上的資料,因此這邊使用HttpRequest,將資料以二進位的方式讀入,在瀏覽器端重建資料庫。

由於在前端重建資料庫是相當大的工程,而React一個沒設計好又會觸發(fā)頁面刷新,導致網(wǎng)頁崩潰,因此要盡量避免useState的使用。
React Memo
紀錄函數(shù)結果,若指定的參數(shù)一樣時就直接回傳結果,不用再執(zhí)行一次複雜的函數(shù)。
語法

當dependencies 有更動時就會重新執(zhí)行YourFunc函式。
Memo的機制適用於函數(shù)複雜、不常更動的元件,由於Memo使用淺比較(shallow comparison)、占用記憶體,執(zhí)行上會比使用React基本刷新機制複雜。因此需先衡量各自的優(yōu)劣喔。
範例:我用Memo紀錄下GetDb查詢結果,只有當sql改變時才會重新執(zhí)行查詢。

因為GetDb是異步程式,所以這邊傳入一個函數(shù)去接查詢結果。

UseRef
用一個變數(shù)記錄著所指定的元件。 和useState差別在於useRef不會造成頁面刷新。
一些React基礎教學可能會像下面這樣,直接在value觸發(fā)useState,這實際上會造成很大的效能問題。假設一字一字的在這個input box打了5000字,就代表這個頁面至少被刷新了5000次,每次刷新所造成的垃圾足以讓網(wǎng)頁crash掉。

useRef使用方式

Craco
全名是Create React App Configuration Override,顧名思義就是讓我們能覆寫webpack config檔的套件。
(webpack協(xié)助我們整合與打包專案。)
為了讓專案能載入wasm檔案,在config檔案下增加:

HashRouter
大概是React改版了,原本的<Switch>被改成<BrowserRouter>,但因為Github page不支援BrowserRouter,因此改用HashRouter。
我猜是因為BrowserRouter的url會發(fā)送request給後端,但github page不支援後端才會被擋。
範例用法:

HashRouter網(wǎng)址前面須加#字號,且不會發(fā)送request,例如http://localhost:3000/#/api
最後我將sql查詢做成接口,使用者可透過在網(wǎng)址輸入?yún)?shù)做查詢,範例網(wǎng)址如下:
(不知道是不是React在搞,?後要先接一個&,不然第一個參數(shù)會被吃掉。)
也因為HashRouter的網(wǎng)址多了#字號,導致解析網(wǎng)址參數(shù)的函式URLSearchParams失效,需要多一步處理。

雜談:
Unity資料驅動下篇再...再等一下( ̄┰ ̄*),期中考,きもち問題。