UnslothAI是一個主打超高速微調語言模型服務的AI公司,而他們提供開源的函示庫本身足夠用較低的顯存與相較快速的速度微調語言模型
這是他們的Git頁面,
本筆記主要記錄我使用他們提供的Google colab筆記本微調Meta-Llama-3-8B-Instruct
使用的是Alpaca + Llama-3 8b Unsloth 2x faster finetuning.ipynb,並使用之前製作的資料集於訓練
UnslothAI筆記本比較像是一種程式的示範,照著順序點點點也能完成一個模型的微調,但如果用了資料集與自己無關的話,那麼練出來的模型嚴格上來說也不屬於自己,因此我在這裡會些許修改他們提供的筆記本,拿著我的資料集以他們的函式庫進行微調
修改使用模型:
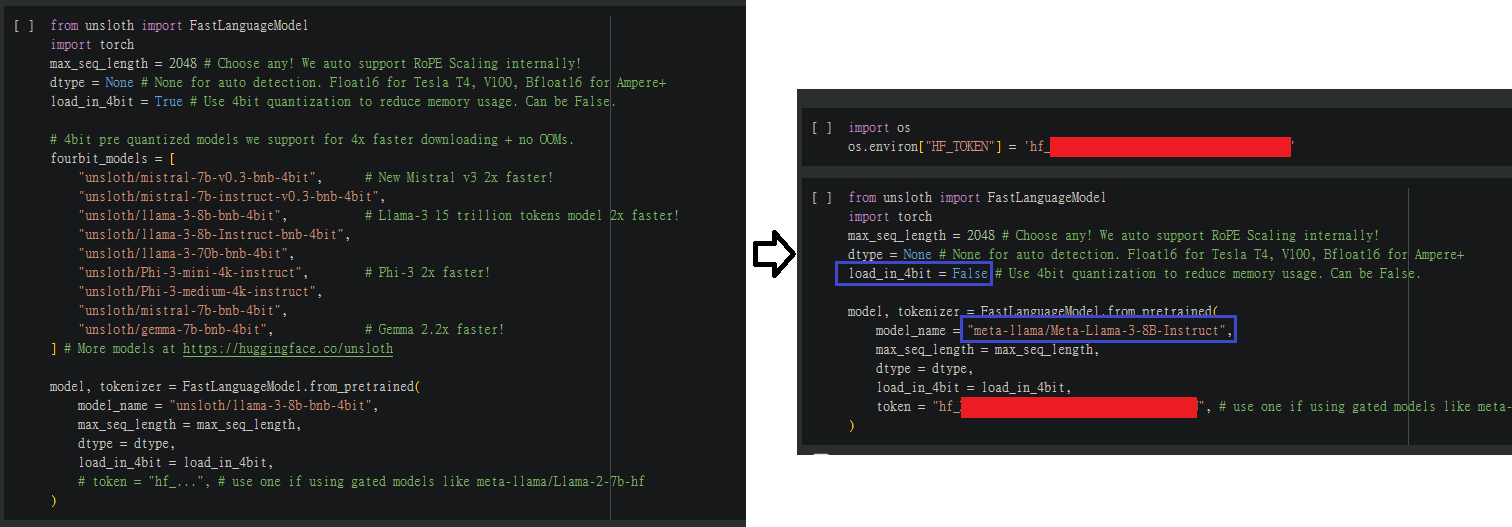
在預設的設定下,如果load_in4bit設為True,則程式會使用UnslothAI壓縮為4bit的模型
我在這裡加了一個設定環境變數的程式去設定huggingface的Token,因為meta底下的LLAMA3是需要有授權才能下載的
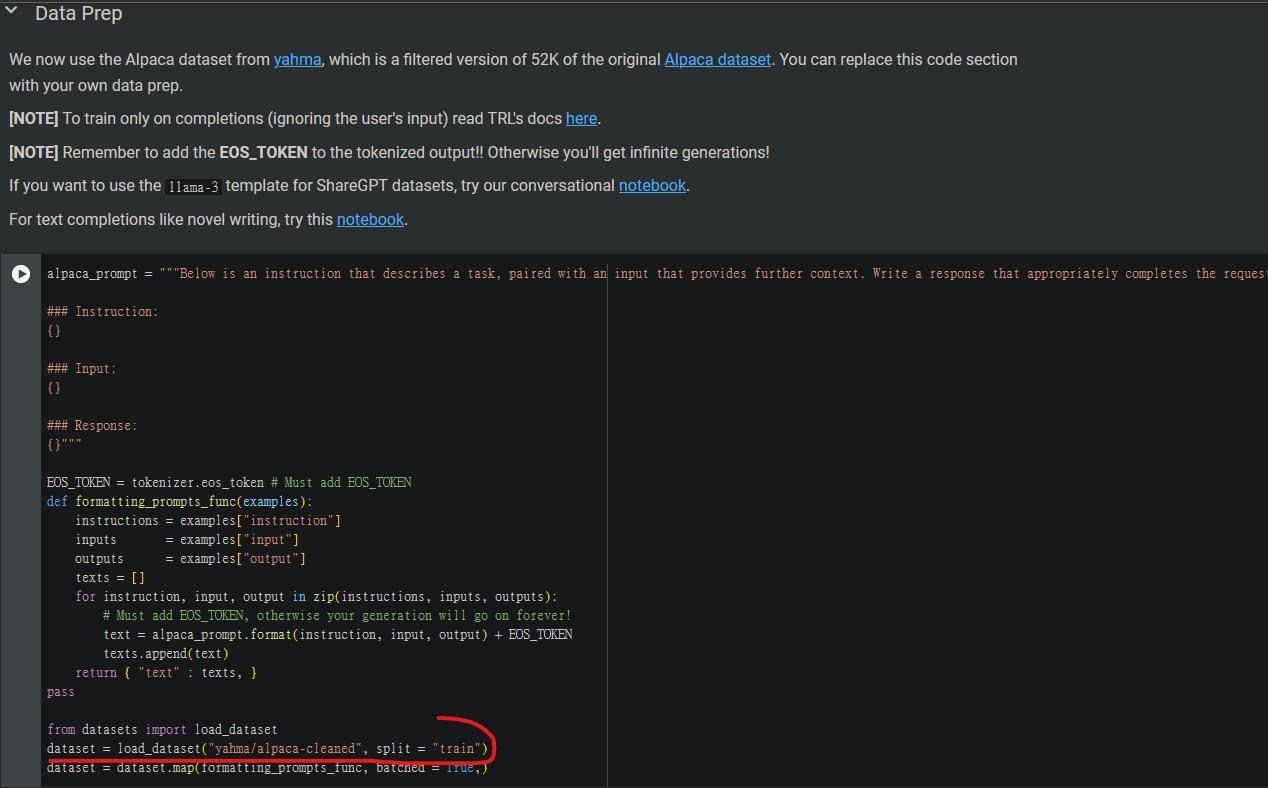
讀取資料集:
這個筆記本使用的是Alpaca-format,原本的範例使用的是由yahma製作的資料集,如果使用的資料集有上傳至Huggingface上的話,直接把紅線部分修改就好
不過像我的資料集在原本的資料集上還塞了一些東西,我在這裡小小修改了一下,簡單的說就是將json檔處裡為訓練用的dataset資料格式
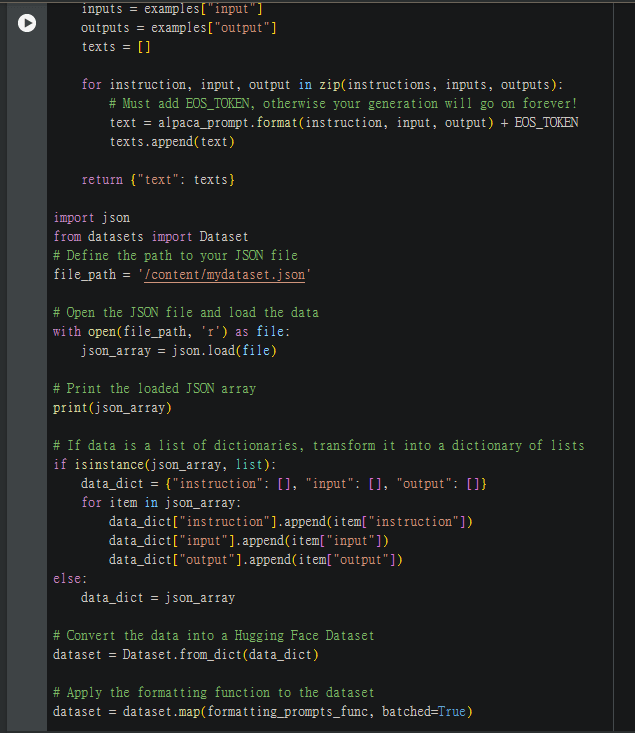
修改訓練參數:
預設的訓練參數在設定最高訓練步數是60步,而這個步數只要稍微大一點點的資料集是完全不足的,不過有趣的是我用步數60~120條一下就能夠讓LLAMA3-8B講中文,因此我將max_steps=60,改為num_train_epochs = 1
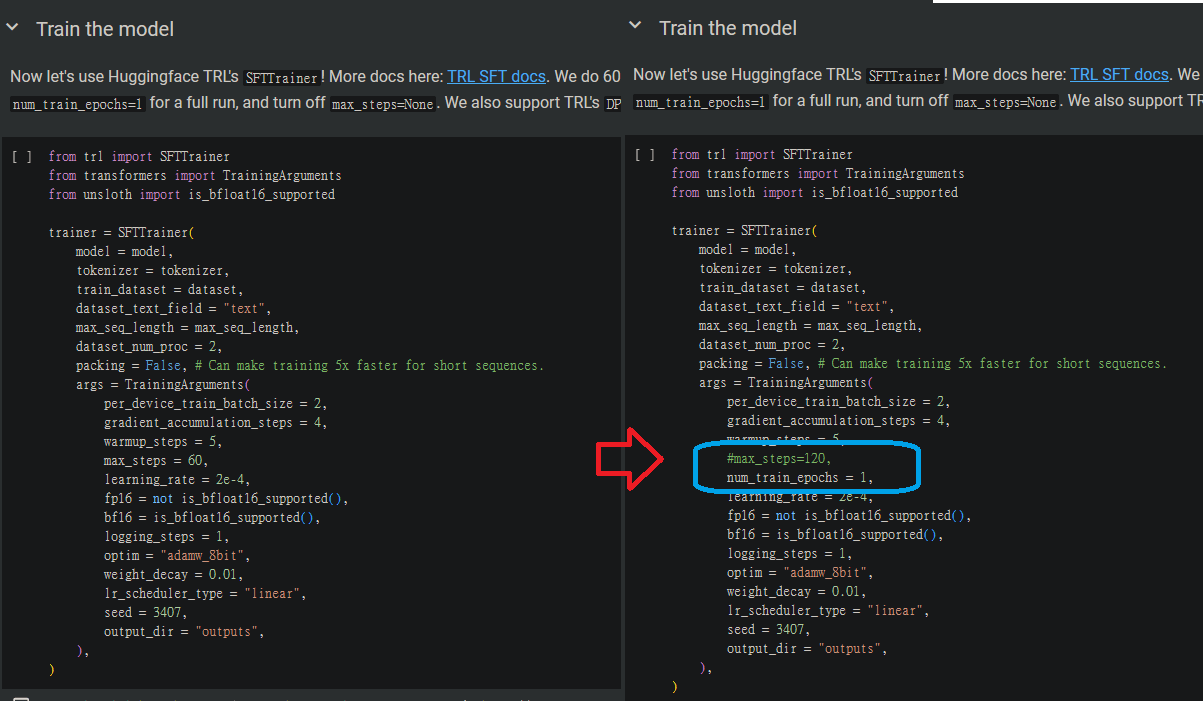
我有修改的部分就這三個部分,前面這些東西改好並一個一個點執行後,最後點下這個trainer的區塊時就會真的開始訓練
llama3-8B-4bit使用的VRAM最多7GB,可以在免費的T4上訓練
即使是使用完整的模型,使用的VRAM也就17GB,剛好在L4上訓練(1小時吃大概5運算單元)
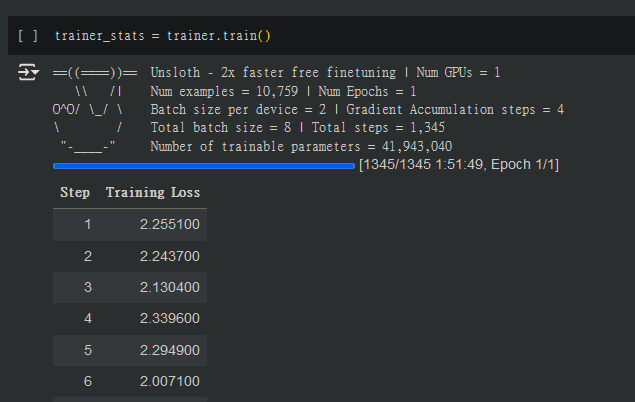
練完可以在下面的Interface試用練成的模型
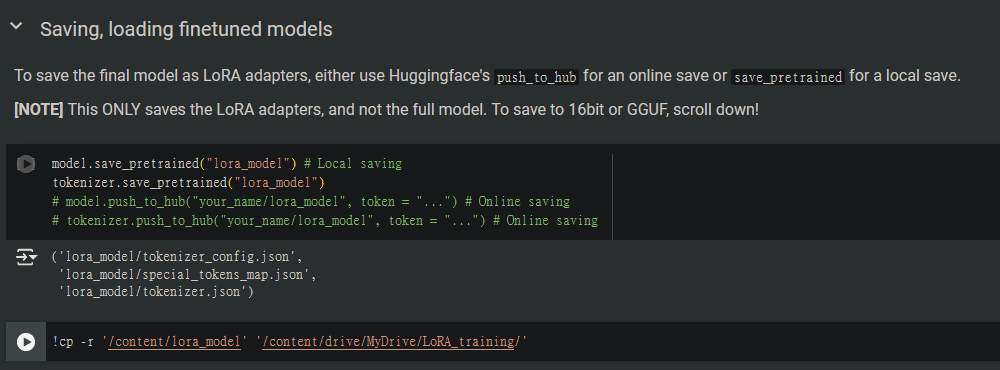
滿意結果的話,就在下面把Lora存起來,不過如果你存的地方是Local,記得將這個Lora下載下來,或是先把Google drive跟colab接起來後把檔案丟過去
程式區註解的部分是直接將Lora丟上Huggingface,只要你有在huggingface上開倉庫,寫倉庫名跟huggingface token就能推上去
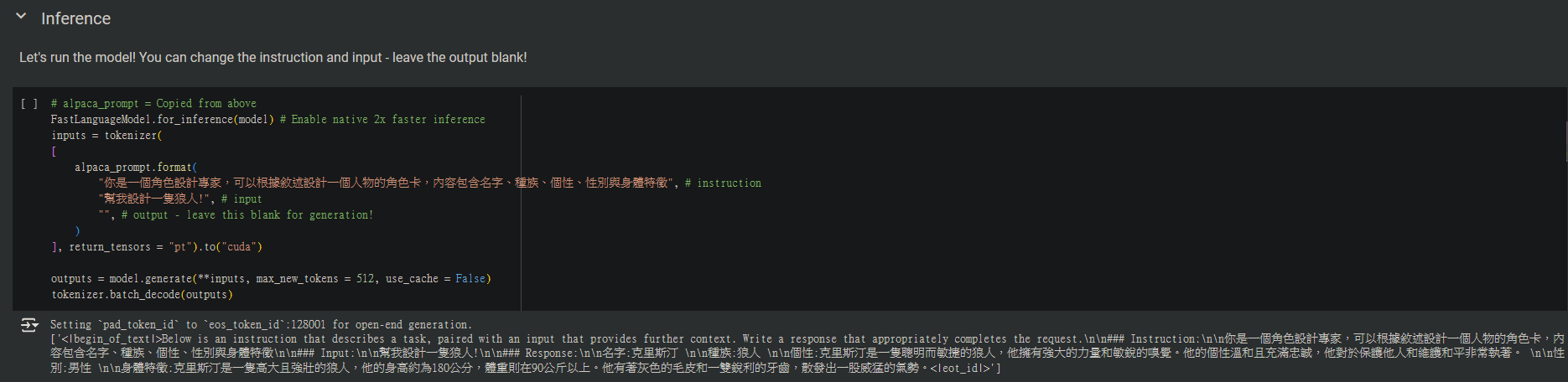
想存成模型?在這個區塊將想要存檔的形式,將False改為True
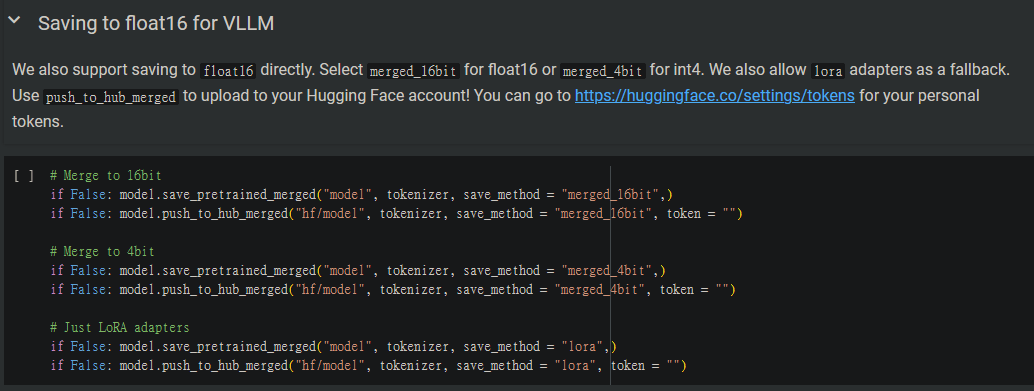
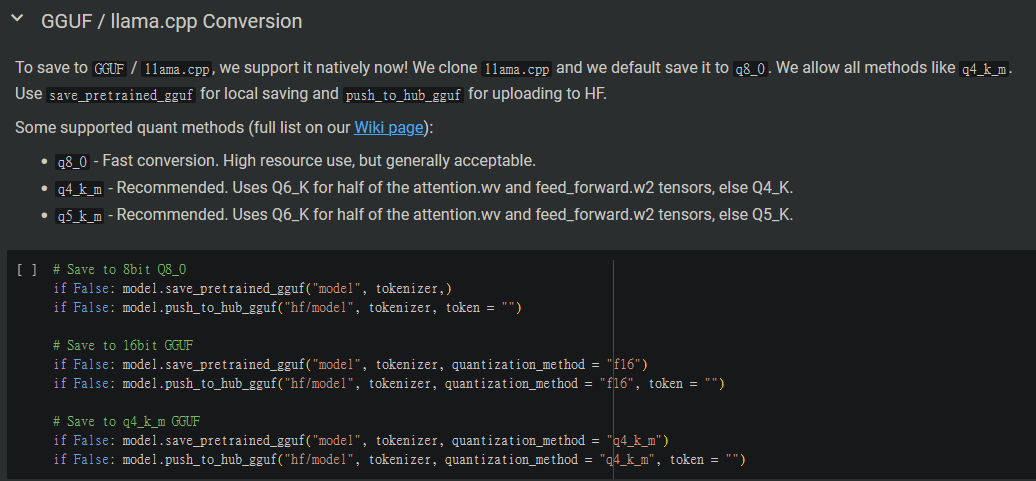
而下半部也有能訓練成果轉存為GGUF格式,一樣將自己所需的部分將False轉為True
大概是這樣,希望這篇可以幫到也想微調模型但資源同為拮據的人
題外話,Unsloth有提供高速微調的服務,如果資料集的體量很大,可以考慮一下
QA:
1.我可以在自己電腦上用Sloth訓練嗎?
當然可以,筆記本上的程式摳下來或是裝Jupyter 都可以在自己電腦上跑
2.max_steps=60到底夠不夠?
根據上面的說法,設為60只是為了讓筆記本可以用更快的速度跑完,但訓練成果就不一定,所以我最後還是將epoch設為1
3.我把lora放到oogaboga web ui為什麼不能讀?
adapter_config.json中多了layer_replication,use_dora,這兩個是PEFT較新版本才有的設定,web ui的peft庫舊了一點點,不過把這兩個從設定中拿掉就可以正常讀取了
一如既往,歡迎提問,我盡量回答




































