這兩周閒暇時間都在為了Llama2做一個繁體中文的lora而砸小錢叫GPT3.5turbo幫我生一堆對話紀錄來讓我有資料練
先把成果貼上來:
Lora:huggingface連結(jié)
-------
text-generation-webui怎麼安裝,怎麼讀語言模型不再贅述,如需幫助請去看我在小屋的另一篇介紹文
那麼,這是webui中Training的頁籤,眼花撩亂,可不是嗎? 我會稍微介紹這些參數(shù)的功能
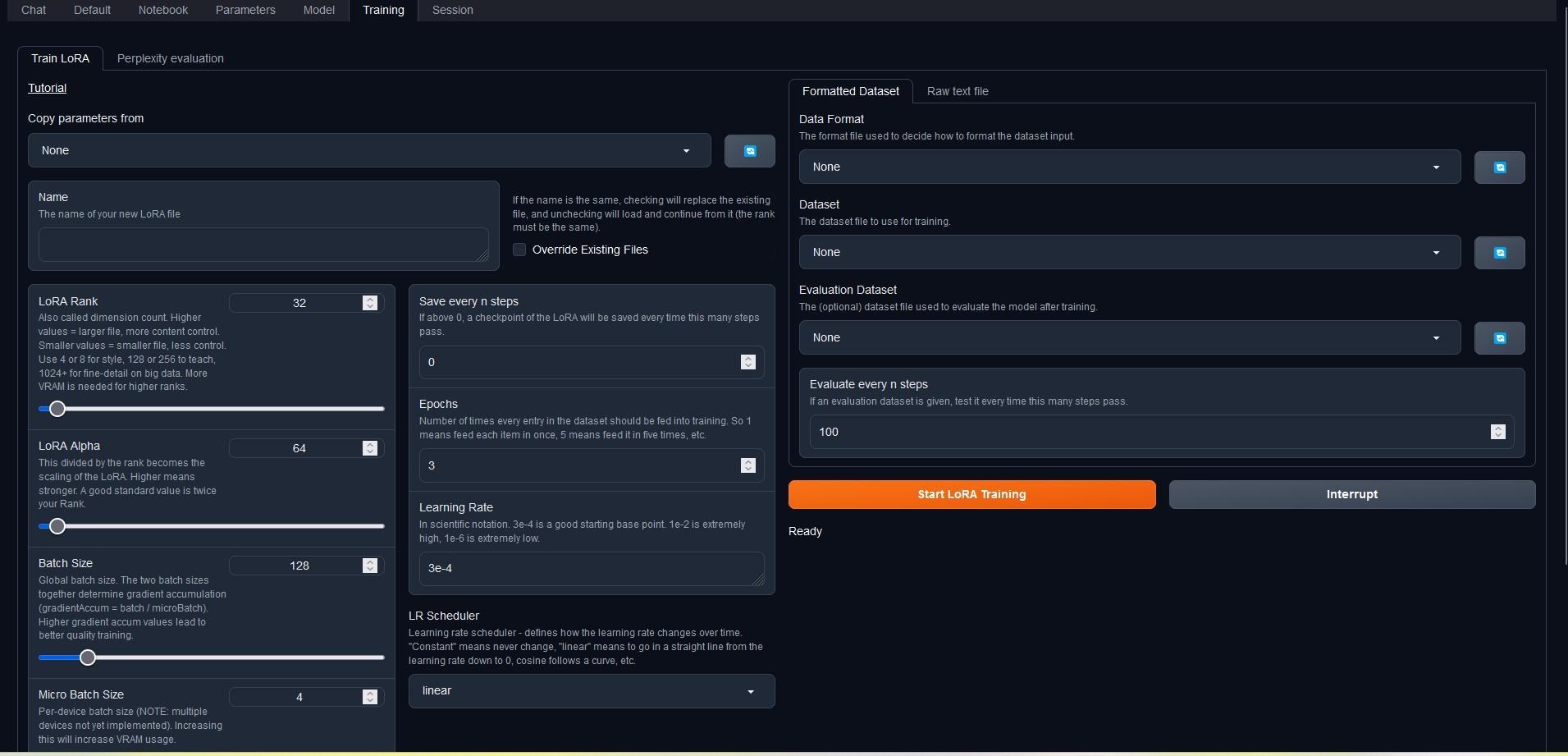
一?參數(shù)
LoRA Rank:也稱為維度計數(shù)。值越高,文件越大,內(nèi)容控制越多。值越低,文件越小,控制力越弱。使用 4 或 8 進行風(fēng)格,128 或 256 進行教學(xué),1024+ 用於大數(shù)據(jù)的細節(jié)處理。更高的值需要更多的 VRAM。 LoRA Alpha:這除以秩就變成了 LoRA 的縮放。值越高,縮放越強。一個好的標準值是你LoRA Rank值的兩倍。
Batch Size:全局批處理大小。這兩個批處理大小一起決定梯度累積(gradientAccum = batch / microBatch)。梯度累積值越高,訓(xùn)練質(zhì)量越好。 Micro Batch Size:每個設(shè)備的批處理大小(text-generation-webui尚未實現(xiàn)這個功能)。增加此值將增加 VRAM 使用量。
Cutoff Length:文本輸入的截斷長度。本質(zhì)上,這是一行文本的長度,一次輸入。較高的值需要極大地增加 VRAM。
看得頭暈了?我也是,所以我在訓(xùn)練是都用預(yù)設(shè)值,比較要自己動的東西是這些:
Save every n steps:此參數(shù)指定每隔多少步保存一次 LoRA 的檢查點。檢查點是模型在特定步驟的狀態(tài)的保存。如果發(fā)生意外,您可以從檢查點恢復(fù)訓(xùn)練,而不用整組重來。
Epochs:此參數(shù)指定將數(shù)據(jù)集輸入訓(xùn)練的次數(shù)。每個 epoch 模型都會讀整個數(shù)據(jù)集一次。
Learning Rate:此參數(shù)控制模型在訓(xùn)練過程中更新其參數(shù)的速度。較高的學(xué)習(xí)率意味著參數(shù)更新得更快,但也可能導(dǎo)致模型不穩(wěn)定。較低的學(xué)習(xí)率意味著參數(shù)更新得更慢,但也可能導(dǎo)致模型訓(xùn)練得更慢。
這裡的重點就是Epochs與Learning Rate,Epochs可以讓較短的資料及多學(xué)幾次,Learning Rate則是可讓模型以多高的效率學(xué)習(xí),但在這邊並不是越高越好
資料集,就把他想成考試的考古題;越高的Epochs(訓(xùn)練次數(shù))與Learning Rate(學(xué)習(xí)率)會把模型做得越擅長達考古題,但做到最後他將完全背起考古題,而一旦到了這個時候可能即使是考古題,稍微換幾個字他就直接暴死
我這幾天跌跌撞撞的經(jīng)驗是:資料集越少,用越高的Epochs讓他學(xué);越長的資料集,將Learrning Rate調(diào)低。不過每個資料集都長不一樣,都是練完之後才知道結(jié)果,人家說AI是盲盒可沒說錯呢!
Lora Rank與Lora alpha的那些參數(shù)如果有設(shè)備,就玩一玩吧!我的顯卡是不太夠啦...
二.資料集
在開始前,你得先把資料集丟到text-generation-webui\training\datasets下:
餵資料的方式有兩種:指定格式與文字檔

指定格式就是很常見的幾種微調(diào)格式,我的資料集與多數(shù)資料集是alpaca-format,基本上他一個資料就是長這樣:
{
"instruction": "艾蜜莉是冒險者公會的一名魔法師,她有著天真活潑的個性,喜歡和人們分享關(guān)於魔法的趣事。",
"input": "聽說你曾經(jīng)在一次魔法實驗中把蝴蝶變大了,是真的嗎?",
"output": "那次只是一個小小的失敗。我本來想讓蝴蝶變得更顯眼,但結(jié)果變得太大了,差點把我給撞倒了呢。不過蝴蝶還是很開心地飛走了。*笑得合不攏嘴*"
}
"instruction": "艾蜜莉是冒險者公會的一名魔法師,她有著天真活潑的個性,喜歡和人們分享關(guān)於魔法的趣事。",
"input": "聽說你曾經(jīng)在一次魔法實驗中把蝴蝶變大了,是真的嗎?",
"output": "那次只是一個小小的失敗。我本來想讓蝴蝶變得更顯眼,但結(jié)果變得太大了,差點把我給撞倒了呢。不過蝴蝶還是很開心地飛走了。*笑得合不攏嘴*"
}
instruction是一個操作說明,簡單的說就是AI會收到的提示詞(prompt)
input是輸入,可以和instruction寫在一起也可以分開寫,在訓(xùn)練時是會組在一起的
output是預(yù)期輸出,AI會先照著前面兩項的prompt生一個自己的答案,然後跟output對照,並從中學(xué)習(xí)
另一種則是生呼呼的文字檔
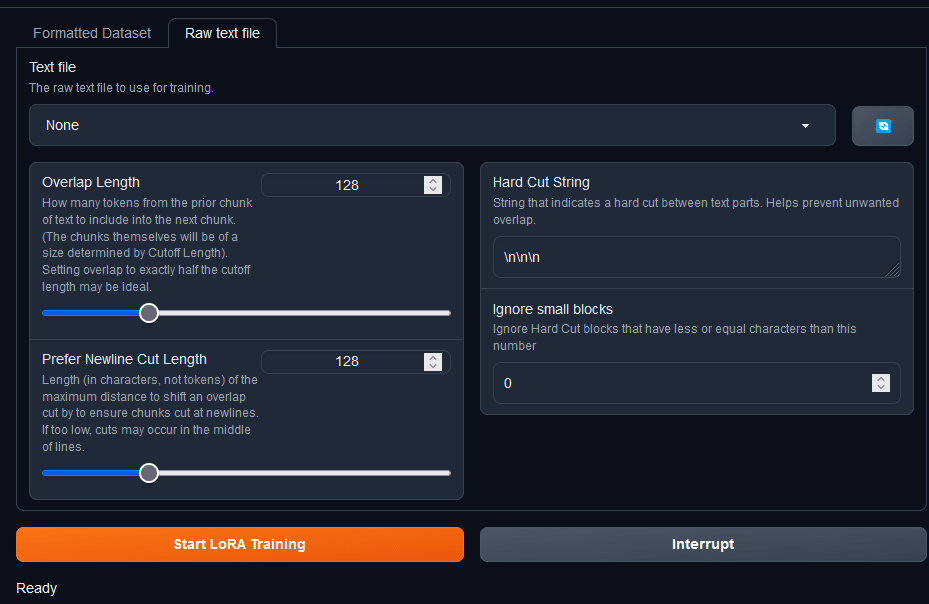
簡單的說你就是丟一個txt檔也可以,webui會開切文字檔
一些參數(shù)解說
Overlap Length:此參數(shù)指定從前一個文本塊中包含到下一個文本塊中的令牌數(shù)。令牌是文本中的一個單詞或短語。較高的重疊長度意味著每個區(qū)塊將包含更多來自前一個區(qū)塊的信息。這可以幫助模型保持上下文並生成更流暢的文本。但是,較高的重疊長度也意味著每個區(qū)塊將更大,這可能會導(dǎo)致顯存問題。
Prefer Newline Cut Length:此參數(shù)指定在確保區(qū)塊在換行處切割時最大可將重疊切割移位的距離。較高的 Prefer Newline Cut Length 意味著模型更有可能在換行處切割區(qū)塊。這可以幫助模型生成更自然的文本,因為自然語言通常在換行處中斷。但是,較高的 Prefer Newline Cut Length 也意味著模型可能會錯過一些重要的信息,因為這些信息可能跨越了多個區(qū)塊。
Hard Cut String:強制切割文字,一旦出現(xiàn)裡面的文字則立刻切割,不管前面的參數(shù),預(yù)設(shè)值是三個換行符號,也就是兩個空白
Ignore small blocks:忽視一些較小的區(qū)塊,像是只有兩三個字的區(qū)塊
整題來說純文字檔也可以讓語言模型學(xué)習(xí),但這個部分學(xué)習(xí)成果就很未知,英語文件可以學(xué)得很好,但中文就很微妙
三.訓(xùn)練:
參數(shù)與資料及準備好後,還得選你要訓(xùn)練哪個模型,text-generation-webui目前只能練這四個LLaMA, OPT, GPT-J, 與GPT-NeoX
訓(xùn)練時會非常非常吃顯存(像我借用A100 40GB還不能練完整精度的llama),可以用較低精度的方式讀取語言模型來訓(xùn)練,像是4bits或8bits,雖然準度會降低,但只要資料集夠長還是練得出一個可用的Lora
訓(xùn)練時會非常非常吃顯存(像我借用A100 40GB還不能練完整精度的llama),可以用較低精度的方式讀取語言模型來訓(xùn)練,像是4bits或8bits,雖然準度會降低,但只要資料集夠長還是練得出一個可用的Lora
以4bits讀7B模型可以只在一張8GB VRAM的顯卡上訓(xùn)練
點下訓(xùn)練就是漫長的等待了,依據(jù)顯卡強度、資料集長度與訓(xùn)練次數(shù)而有所變化,像我的資料集在我的4060上訓(xùn)練是6小時,在訓(xùn)練時會有一些紀錄,可以觀察一下訓(xùn)練狀況
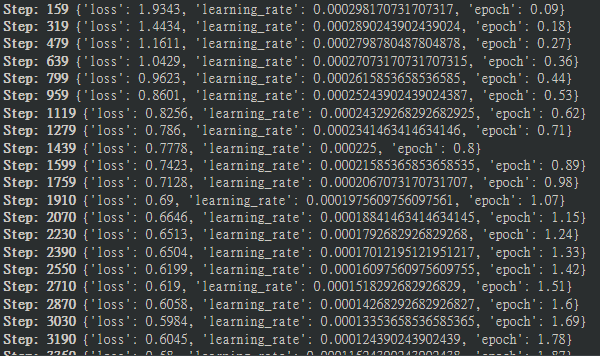
loss代表學(xué)習(xí)的狀況,這個值應(yīng)該要隨訓(xùn)練的過程逐漸降低,偶有波棟可能代表你的資料集有些不一致,讓模型學(xué)到了一些「新東西」
learning_rate就是前面提到的學(xué)習(xí)率,這個值本身會逐漸下降以防止過度擬合(還記得前面提到的考古題嗎?)
最後練完,Lora會被存在text-generation-webui\loras底下,你可以馬上來試試你的lora!
四.驗證成果
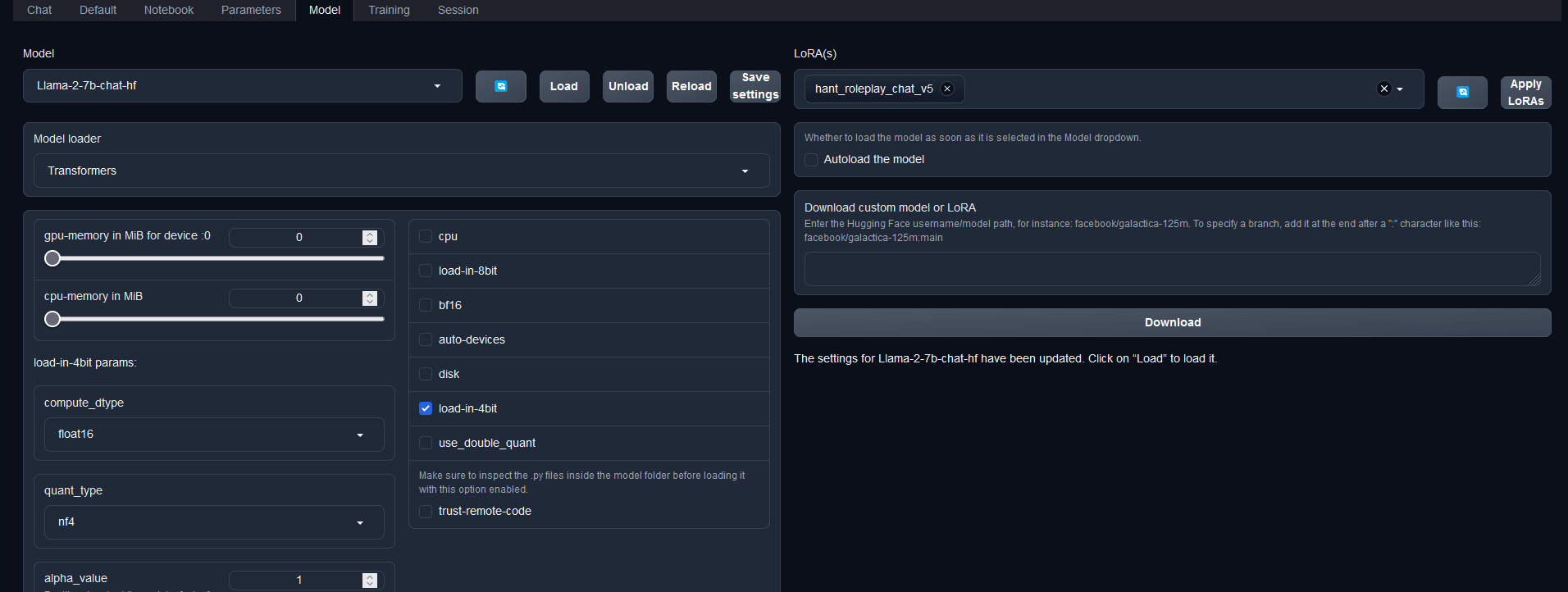
回到Model頁,你需要先重新讀取擬的語言模型,接著你就可以在右邊的LoRA(s)中找到你剛才訓(xùn)練出的Lora,選他然後點Apply LoRAs,接著你就可以觀察成果了!
有點怪怪的,不過也算有個樣子了

常見問題
1.我怎麼訓(xùn)練出來的東西爛爛的?
訓(xùn)練和你的輸入有關(guān),輸入不夠或是毫無規(guī)律,那麼他就會學(xué)得爛爛的
2.我要去哪裡弄資料集?
huggingface上有很多開源的資料集,像我也有把我的資料集放在上面,不過問題是你希望你練出來的AI要幹甚麼?
想要聊天?餵他一堆對話紀錄,你沒有對話紀錄就要自己寫
想做成客服?那你就要準備許多Q&A
想要他算數(shù)學(xué)?其實你不該叫語言模型做數(shù)學(xué)
3.我可以在別人的基礎(chǔ)上再訓(xùn)練嗎?
這要看你的「別人」授予的權(quán)限,雖說開源是開放給大家使用,但也是有分用途的,若要商用可要多留意
4.我可以在CPU模式下進行訓(xùn)練嗎?
當然可以,只要你願意忍受超久的訓(xùn)練時間
5.有甚麼免費的資源可以訓(xùn)練Lora?
所有免費的資源都不夠用於訓(xùn)練一個Lora,要有成效的訓(xùn)練基本上都不能免費讓你練成,Colab免費仔借到的T4 GPU訓(xùn)練速度比我手上的這塊4060還要慢
一如既往,歡迎提問













































