主題
萬眾矚目的Llama 3終於出來啦!下面開始從各種發佈的資料中抓一些重點資訊來介紹,並整理使用方式與API管道  。
。
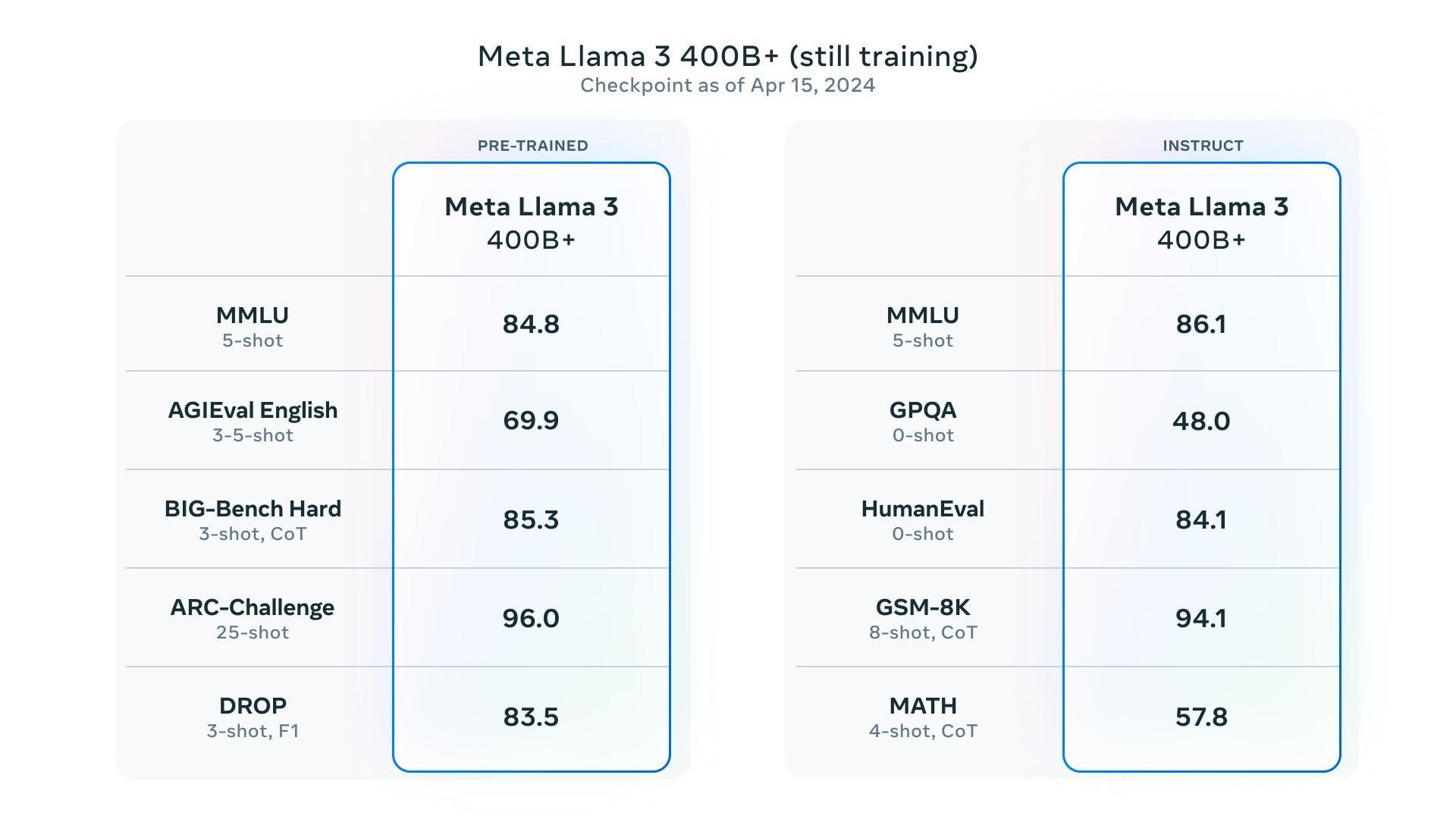
另外還有最大的400B(4千億)參數模型正在訓練當中,期待會是Dense還是MoE架構,另據網友比較與Claude Opus相當( 2024/7/23推出最大為4050億參數的Llama3.1模型 [2024/07/23 (二) 推出] )。
。?設計理念:
LLaMA 3採用了四個關鍵要素的設計理念,重點在於:
- 模型架構
- 預訓練資料
- 擴大預訓練
- 指令微調
 |
?模型型號介紹:
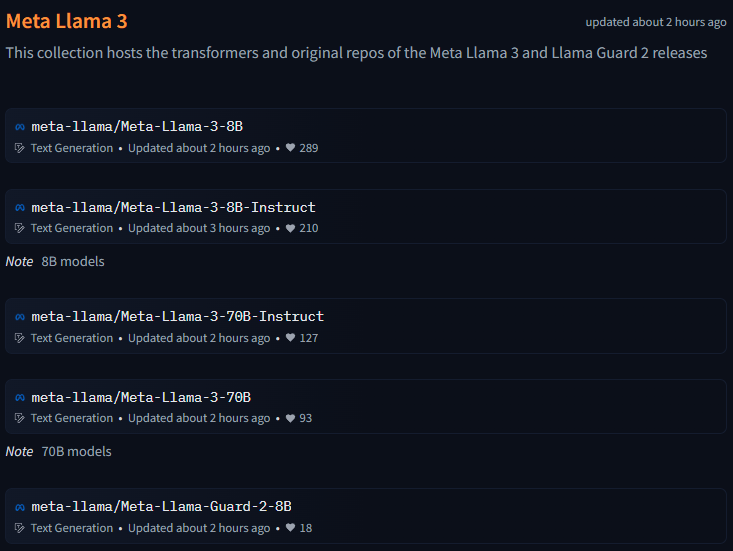
Meta目前釋出的8B與70B參數量的LLaMA 3模型,
8B的模型可用於消費級GPU上高效部署和開發,
70B的模型則專為大規模AI應用設計,
兩種型號都包含基礎和經過微調的模型,
除了以上4個模型之外,還推出了基於Llama 8B上微調後的Llama Guard 2(安全微調版本),可用於檢測、分類prompts和回應的內容危害程度。
 |
▲ Llama Guard 2
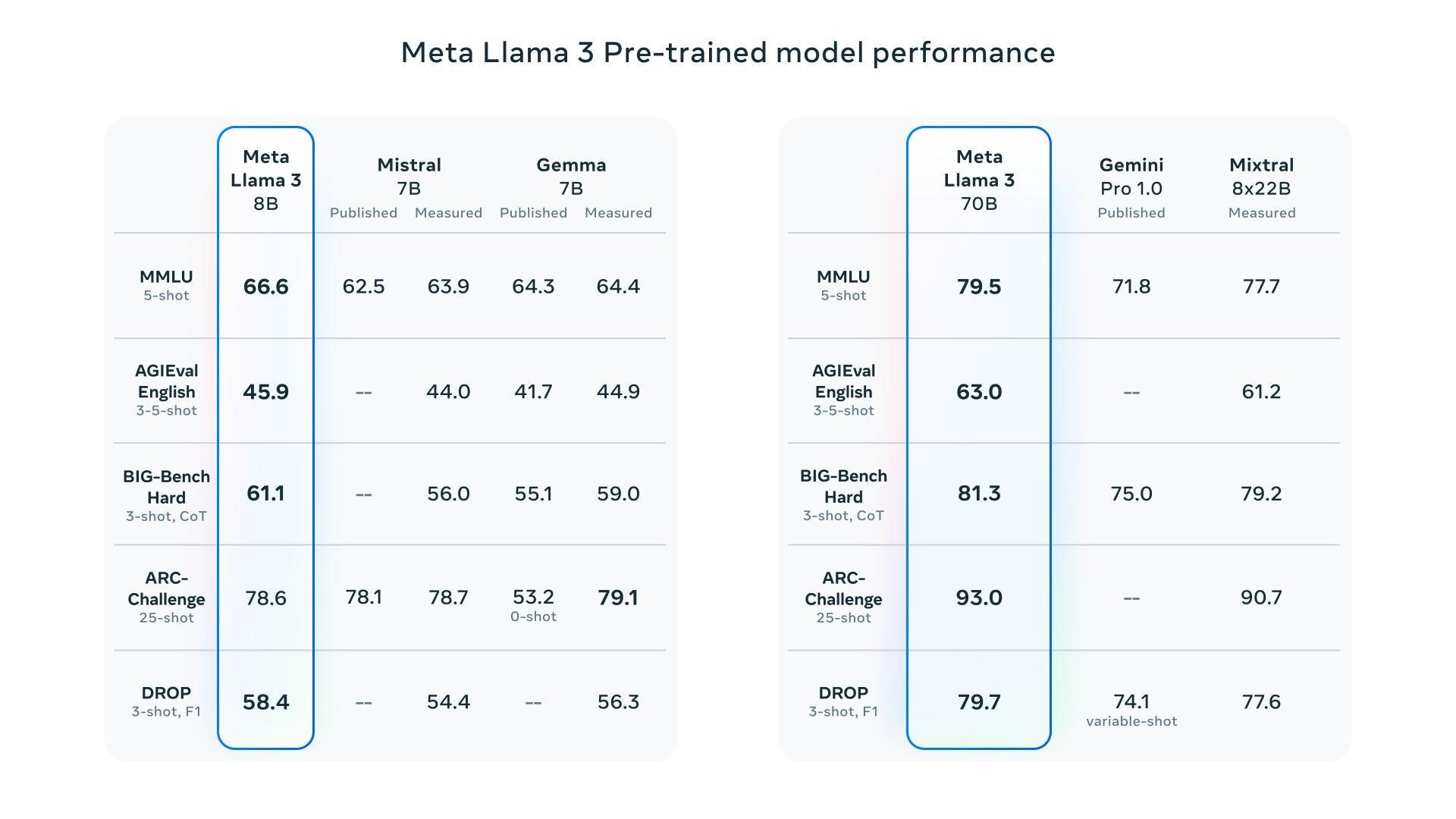
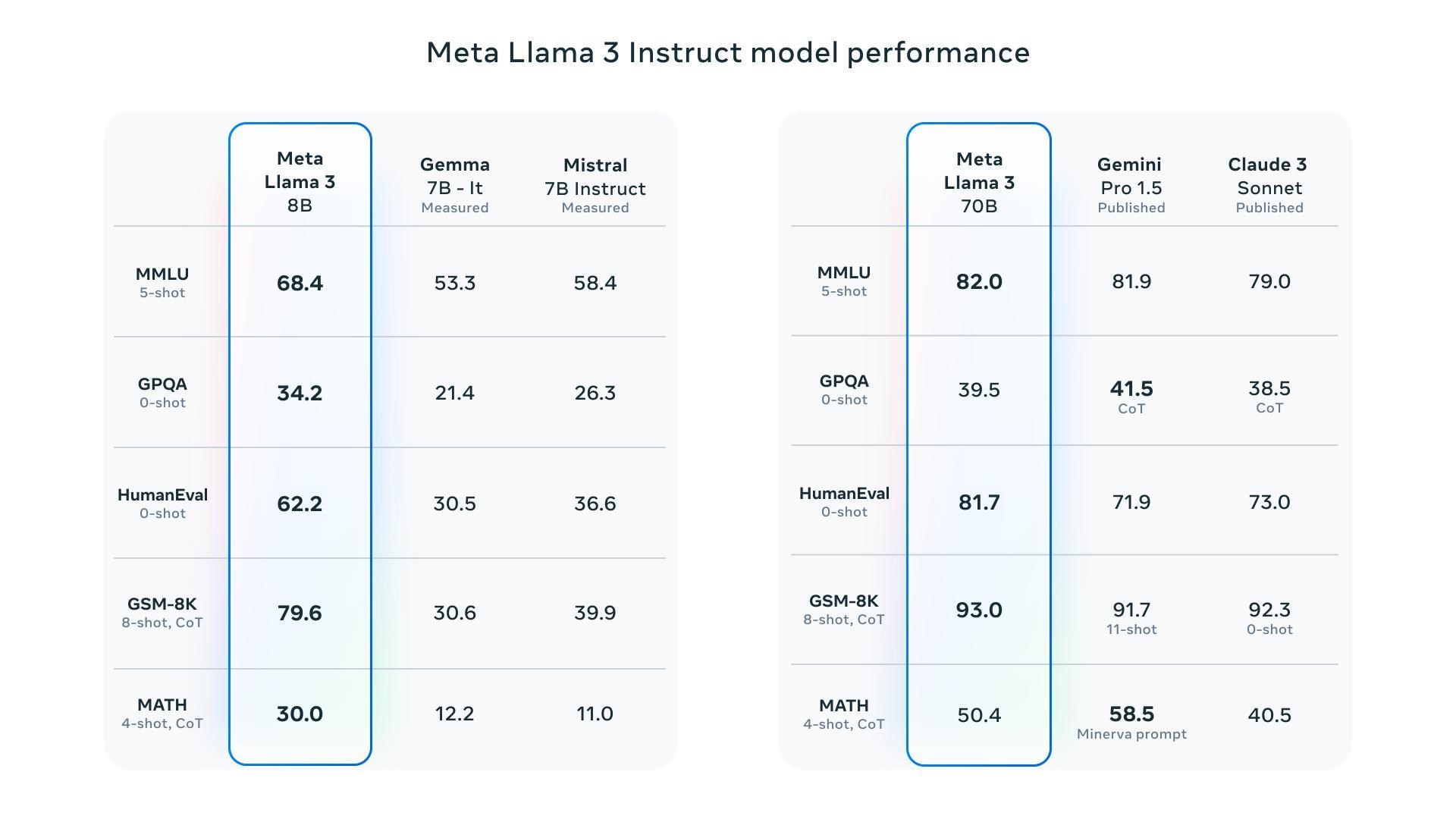
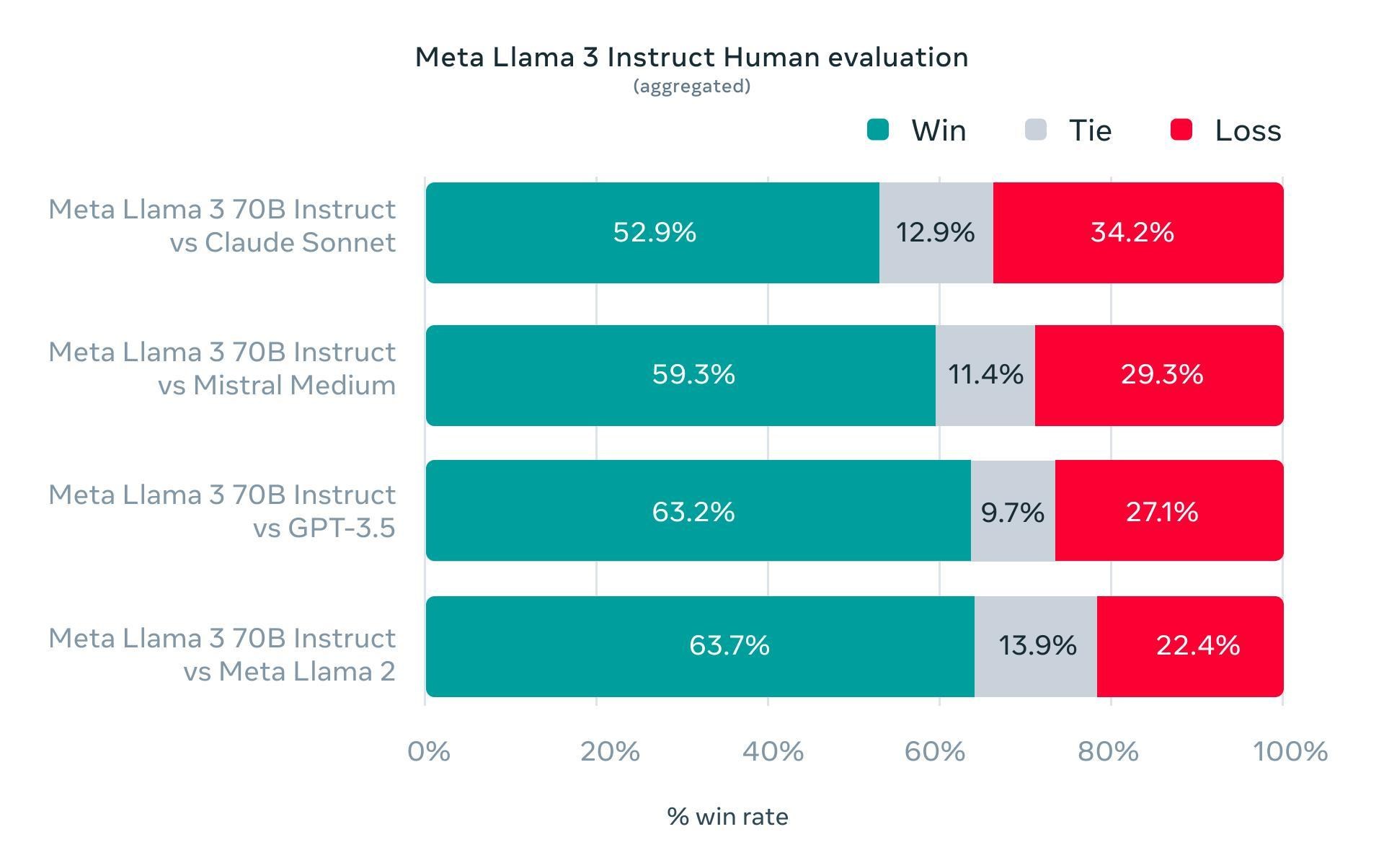
?模型評估/基準測試:
 |
 |
 |
 |
?模型架構介紹:
模型的架構上採用了相對標準僅decoder的transformer,且上下文的長度是Llama 2的2倍,與Llama 2相比最大的變化的地方是使用了新的tokenizer,將Vocabulary的大小拓展至128K(128,256)tokens(先前的僅32K),從而更有效的對語言進行編碼,產生更強的多語言能力,提高了模型的性能,另外Llama 3 70B的錯誤拒絕率不到Llama 2 70B的1/3。
?模型訓練/訓練資料集/微調:
Llama 3使用超過15T tokens的預訓練資料,全部收集自公開的資料,並且所訓練的資料集比Llama 2多了7倍之多,包含4倍以上的程式碼,超過5%的預訓練資料集由30多種非英語資料組成,但是預計不會有與英語一樣的水準。
除了使用高品質的資料訓練之外,另外開發了一系列資料過濾管道(data-filtering pipelines)用來預測資料品質:heuristic、NSFW、semantic、semantic deduplication approaches、text classifiers。
Llama 3的許多改進使訓練效率比Llama 2約高出了3倍。
此外也已針對Llama 3 Instruct模型的對話應用進行了優化,並採用來自1千萬個人工註釋資料的訓練,並結合了監督微調(SFT)、拒絕採樣微調(RSFT)、近端策略優化(PPO)、直接偏好優化(DPO)來進行訓練。
?Llama 3 建構開發:
除了引入新的工具至安全評測工具項目Purple Llama之外,也引入至最近PyTorch所推出用於模組化完整微調的torchtune函式庫,藉由torchtune來對Llama 3進行Full-finetune,此Library也與Hugging Face、Weights & Biases、EleutherAI 等熱門平臺集成,甚至支援Executorch,以便運行在各種移動、邊緣裝置上進行高效推理,詳情請參考文檔,例如與LangChain結合使用等...
?模型支援的平臺:
AWS、Databricks、Google Cloud、Hugging Face、Kaggle、IBM WatsonX、Microsoft Azure、NVIDIA NIM 和 Snowflake,並獲得 AMD、AWS、Dell、Intel、NVIDIA 提供的硬體平臺支援。
?Llama 3 模型使用/API:
- Hugging Face:
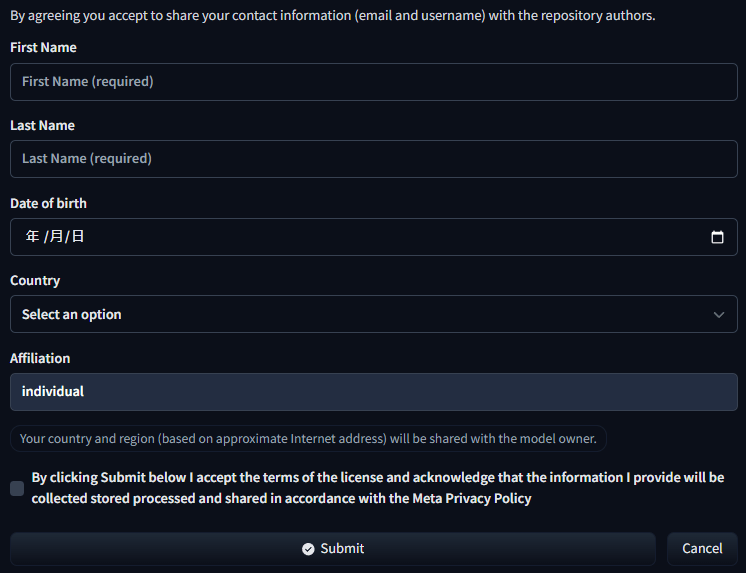
- 使用前須先填寫資料來申請訪問權限,如果是個人用Affiliation欄位可寫individual即可:
- Meta Llama 3 模型總覽 (Collections)
- Meta Llama 3.1模型總覽 (Collections) [2024/07/23 (二) 推出]
- Meta-Llama-3-8B
- Meta-Llama-3-8B-Instruct
- Meta-Llama-3-70B
- Meta-Llama-3-70B-Instruct
- 針對安全性的模型:
- Meta-Llama-Guard-2-8B:可針對prompt和回應進行分類,判斷內容安全的程度等。
- Kaggle:
- Replicate:
- Azure AI Studio:
- NVIDIA NIM (NVIDIA 推論微服務):
- ai.nvidia.com (zh-tw)
- IBM Watsonx:
- Google Cloud Vertex AI Model Garden:
- Databricks (即將推出)
- Snowflake Cortex (即將推出)
?相關連結:
- Llama 3
- Blog
- Blog (HuggngFace)
- 認識你的新助手:Meta AI,用 Llama 3 構建
- Docs
- Github
- 模型使用/Demo:
- Meta.ai (去年9月所推出的AI助理,已改採Llama 3模型,可以在 Facebook、Instagram、WhatsApp 和 Messenger 上使用)
- Llama-3-70B-Instruct模型已整合至Hugging Chat
- 待新增...
- 相關公告/新聞:
- Meta釋出最新的開源大型語言模型Meta Llama 3 (iThome)
- Meta AI聊天機器人改用Llama 3,開始涉足全球市場 (iThome)
- Introducing Meta Llama 3 Models on Azure AI Model Catalog
- Meta Llama 3 Available Today on Google Cloud Vertex AI
- Building Enterprise GenAI Apps with Meta Llama 3 on Databricks
- ???????? Llama 3 is now available in watsonx.ai!
- Wide Open: NVIDIA Accelerates Inference on Meta Llama 3
- Snowflake on LinkedIn: Introducing Meta Llama 3
最後的最後