Unity使用版本:2023.1.9f1
這半年手邊有個AVG遊戲專案,採用Naninovel進行製作。後來有一次上去Naninovel官網查詢文件的時候,意外發現他們更新了,新版的Naninovel全面使用TextMeshPro,移除舊版的Text(的樣子)
其實TextMeshPro這東西我從之前就有看到過,但是看見他的元件上設定多到爆,我一個逃避之下,至今都沒有好好面對過他。
既然連套件都決定捨棄舊版Text元件採用TextMeshPro,那看來面對它是不可避免的趨勢,於是我下定決心,跟他來個正面對決!馬上安裝TextMeshPro來玩玩。
──結果剛玩就出事。
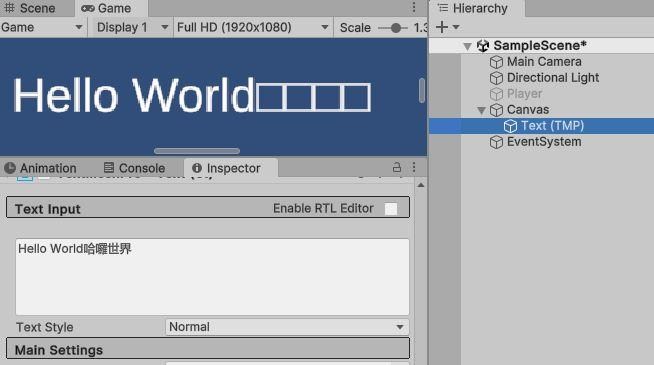
啊我的中文咧?是在哈囉?
會沒出現是因為Unity的字型資源設定中,並沒有設定中文字的字元碼。我們可以看看預設的字型中,有包含哪些字元。
點擊TextMeshPro套用的字型資源設定,導到字型資源設定的所在位置後,按Update Atlas Texture(我們還沒有要更新,只是先打開來看看設定而已)


打開以後可以在Font Asset Creator中看到,在Character Sequence (Hex)那個欄位中,有許多16進制的資料,這些就是用來定義可使用字元的資料(Unicode)。
TextMeshPro原本預設的內容如下:
| 20-7E,A0-FF,2000-200F,2012-2022,2026,202A-2030,2032-2034,2039-203A,203C,203E,2044,205E,206A-206F,20AC,2122,25A1 |
對應到的字元集如下:
| !"#$%&'()*+,-./0123456789:;<=>?@ABCDEFGHIJKLMNOPQRSTUVWXYZ[\]^_`abcdefghijklmnopqrstuvwxyz{|}~ ?¢£¤¥|§¨?a???ˉ°±23′μ?·?1o?????àá??????èéê?ìí??D?òó???×?ùú?üYT?àáa?????èéê?ìí??e?òó???÷?ùú?üyt???–—―‖?‘’??“”?????…‰′″???? ̄??€?□ |
為了要解決無法顯示中文的問題,我們就只要把中文的字元碼都加上去就好。
我這次使用Google Fonts 中的中文字體Noto Sans Traditional Chinese來做測試。從google fonts中下載字體下來後會得到一包有許多不同字重的字型,請依照自己的喜好與需求來使用,我這邊先使用Regular來說明。
將字體拉進Unity後,打開剛剛的Font Asset Creator視窗──如果已經關掉的話,可以從「Window → TextMeshPro → Font Asset Creator」打開 ──把Source Font File改成我們剛剛拉進專案的NotoSansTC-Regular字體。
然後把Character Set設定成「Unicode Range (Hex)」這樣Unity才知道待會我們是怎樣定義字元集的。
在下面Character Sequence (Hex)上方,有一個Select Font Asset,如果這邊不是None的話,請把他調成None,因為我們想建立一個新的字型資源設定,不要讓他和任何其他資源有瓜葛。
再來就可以在Character Sequence (Hex)設定我們要的字了!
──但這個網路上抓的字體支援甚麼字,我怎麼知道?!
──就算我知道支援甚麼字,但那些字的Unicode,我又怎麼知道?!
關於第一個問題,可以直接看Google Fonts頁面的說明:
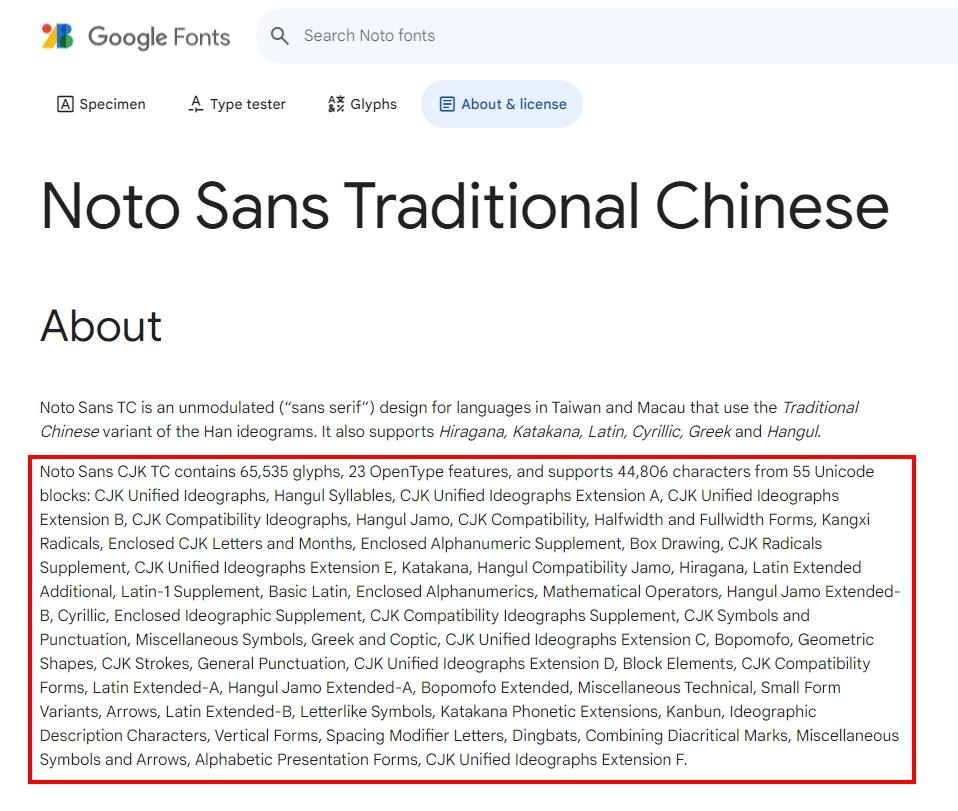
這裡告訴了我們所有有包含的字,而我們就可以從Google提供的這些資料去找每個字集的Unicode範圍了!例如直接找他提供的第一個字集CJK Unified Ideographs,馬上就可以知道他的Unicode範圍!

是不是很方便!!
好,並沒有。麻煩死了!這麼多欸。
雖然這真的很麻煩,但先預告一下,真正的夢靨不只這樣而已。
關於這個字體所有支援字的Unicode範圍,我貼在這裡:
| 20-7E,A0-FF,2000-200F,2012-2022,2026,202A-2030,2032-2034,2039-203A,203C,203E,2044,205E,206A-206F,20AC,2122,25A1,4E00-9FFF,3400-4DBF,20000-2A6DF,2A700-2B73F,2B740-2B81F,2B820-2CEAF,2CEB0-2EBEF,AC00-D7A3,F900-FAFF,1100-11FF,3300-33FF,FF00-FFEF,2E80-2FD5,3200-32FF,2E80-2EF3,30A0-30FF,3130-318F,3040-309F,D7B0-D7FF,1F200-1F2FF,2F800-2FA1F,3100-312F,31A0-31BF,31C0-31EF,A960-A97F,31F0-31FF,3190-319F,2FF0-2FFB,FE10-FE1F,1F100-1F1FF,2500-257F,1E00-1EFF,0080-00FF,0000-007F,2460-24FF,2200-22FF,0400-04FF,0500-052F,2DE0-2DFF,A640-A69F,1C80-1C8F,1E030-1E08F,3000-303F,2600-26FF,0370-03FF,25A0-25FF,2000-206F,2580-259F,FE30-FE4F,0100-017F,31A0-31BF,2300-23FF,FE50-FE6F,2190-21FF,0180-024F,2100-214F,02B0-02FF,2700-27BF,0300-036F,2B00-2BFF,FB00-FB4F |
有需要全部的朋友歡迎自取。不過,這邊會有延伸的另一個問題,但這個我們待會再提。
先把這串丟上去Character Sequence (Hex)之後,按下Generate Font Atlas,我們就可以得到一個可以顯示「中文」、「日文」、「韓文」、「英文」的字型資源設定檔了。(不過如果讓它生產全部的字體,這個過程可能會需要大約5~10分鐘)
生產完畢後,請記得Save as...將這個設定檔存起來,並將這個設定檔套到TextMeshPro 上,中文就能正常顯示啦!
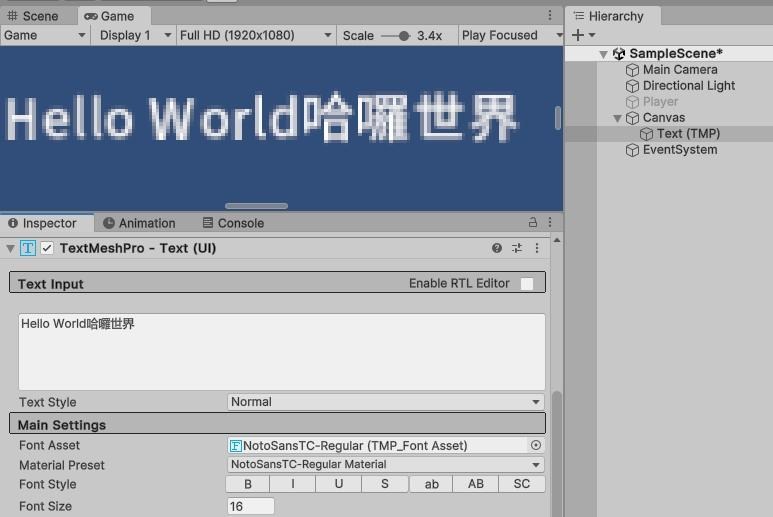
如果在需求中,需要動態的設定某些字詞的粗細,那麼我們可能就會需要把同樣的步驟套用在其他如Thin、Black的字體,讓Unity幫我們產生不同字重的資源設定檔。然後選擇預設的字重(Regular),分別把其他的字重套用到各個對應的數值中。
以這次使用的字體為例,下載整包字體檔以後,除了Regulat以外,還有其他如Black、Bold、ExtraBold、ExtraLight、Medium、SeimiBold、Thin等字體。
我們將這些字體放進專案後,重複上述的步驟,分別產出資源設定檔後,點選Regular並查看Inspector,稍微往下拉可以看到這個區塊。
這個區塊可以設定不同的字重下,需要套用哪一個資源檔。對照著Google提供給我們的名稱,把對應的檔案放到對應的字重上。(名稱可能會有些許差異)
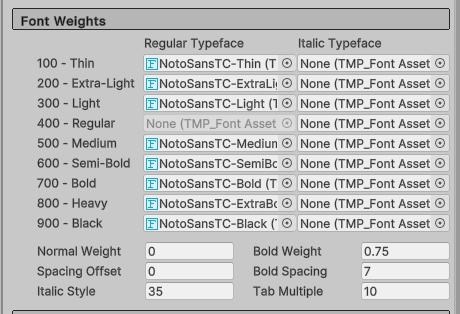
這樣我們在TextMeshPro套用這個字型設定檔後,就可以用RichText的語法動態的給某段文字特定的粗細啦!
其實到這個地方,TextMeshPro無法輸入中文的部分應該算是解決了,只是還有一個問題是關於專案包體的部分。
如果我們要把原字體有支援的字全部都放到設定檔裡的話,那這個設定檔的檔案大小會很大!一個字重的字體就大約有50M左右,如果有動態設定字體粗細的需求,八個字重加起來就會高達400M。
甚麼!我遊戲都還沒開始做,光字體就要0.5G嗎?
如果說預期遊戲中甚麼字元都可能會用到,為了要能夠顯示各式各樣的文字,那樣的話,這樣的包體大小應該是無法避免的,但如果只是為了應對一些UI、劇情文字顯示,我想應該可以只挑幾個會用到的就可以
關於這部分,可能就真的要好好的去查前面說到各個字集了,看看那個字集是不是真的是自己需要的。
若不確定查到的Unicode範圍是不是真的有自己要的字元,可以寫一段簡單的程式來驗證就行,這部分可以滑到最下方參考附件
這個字體有支援的所有字加總起來,根據Google Fonts的描述,有六萬五千多字,如果很極限的把自己想要的字挑出來,我想應該可以少個2/3的大小吧。
不過就我自己而言,在出事之前我可能暫時不會去改這塊,除非專案到後來真的大到不合理,不然我可能就會直接像這樣讓所有的字都涵蓋進來了。
等到之後有需要來整理這些字的時候,或許我會再做一次筆記XD
最後,也附上這個Google字體各個字元集的Unicode範圍表。
| 名稱 | Unicode |
| CJK Unified Ideographs | 4E00–9FFF |
| CJK Unified Ideographs Extension A | 3400–4DBF |
| CJK Unified Ideographs Extension B | 20000–2A6DF |
| CJK Unified Ideographs Extension C | 2A700–2B73F |
| CJK Unified Ideographs Extension D | 2B740–2B81F |
| CJK Unified Ideographs Extension E | 2B820–2CEAF |
| CJK Unified Ideographs Extension F | 2CEB0–2EBEF |
| Hangul Syllables | AC00-D7A3 |
| CJK Compatibility Ideographs | F900–FAFF |
| Hangul Jamo | 1100-11FF |
| CJK Compatibility | 3300-33FF |
| Halfwidth and Fullwidth Forms | FF00-FFEF |
| Kangxi Radicals | 2E80-2FD5 |
| Enclosed CJK Letters and Months | 3200-32FF |
| CJK Radicals Supplement | 2E80-2EF3 |
| Katakana | 30A0-30FF |
| Hangul Compatibility Jamo | 3130-318F |
| Hiragana | 3040-309F |
| Hangul Jamo Extended-B | D7B0-D7FF |
| Enclosed Ideographic Supplement | 1F200-1F2FF |
| CJK Compatibility Ideographs Supplement | 2F800–2FA1F |
| Bopomofo | 3100–312F,31A0–31BF |
| CJK Strokes | 31C0-31EF |
| Hangul Jamo Extended-A | A960-A97F |
| Katakana Phonetic Extensions | 31F0-31FF |
| Kanbun | 3190-319F |
| Ideographic Description Characters | 2FF0-2FFB |
| Vertical Forms | FE10-FE1F |
| Enclosed Alphanumeric Supplement | 1F100-1F1FF |
| Box Drawing | 2500-257F |
| Latin Extended Additional | 1E00-1EFF |
| Latin-1 Supplement | 0080-00FF |
| Basic Latin | 0000-007F |
| Enclosed Alphanumerics | 2460-24FF |
| Mathematical Operators | 2200-22FF |
| Cyrillic | 0400–04FF,0500–052F,2DE0–2DFF,A640–A69F,1C80–1C8F,1E030–1E08F |
| CJK Symbols and Punctuation | 3000-303F |
| Miscellaneous Symbols | 2600-26FF |
| Greek and Coptic | 0370-03FF |
| Geometric Shapes | 25A0-25FF |
| General Punctuation | 2000-206F |
| Block Elements | 2580-259F |
| CJK Compatibility Forms | FE30-FE4F |
| Latin Extended-A | 0100-017F |
| Bopomofo Extended | 31A0-31BF |
| Miscellaneous Technical | 2300-23FF |
| Small Form Variants | FE50-FE6F |
| Arrows | 2190-21FF |
| Latin Extended-B | 0180-024F |
| Letterlike Symbols | 2100-214F |
| Spacing Modifier Letters | 02B0-02FF |
| Dingbats | 2700-27BF |
| Combining Diacritical Marks | 0300-036F |
| Miscellaneous Symbols and Arrows | 2B00-2BFF |
| Alphabetic Presentation Forms | FB00-FB4F |
附件
列舉Unicode範圍的字元
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
function PutResult(dec) { if (!result.includes(String.fromCharCode(dec))) { result.push(String.fromCharCode(dec)); } } let result = []; function GetAllChar(ranges) { result = []; ranges.split(",").forEach((range) => { if (range.includes("-")) { const min = parseInt(range.split("-")[0], 16); const max = parseInt(range.split("-")[1], 16); for (let i = min; i <= max; i++) { PutResult(i); } } else { PutResult(parseInt(range, 16)); } }); console.log(result.join("")); } GetAllChar("41-5A,61,66,70-7A") |
最下面那行 GetAllChar("41-5A,61,66,70-7A") 可以傳入Unicode範圍,以範例來看會輸出以下字串:ABCDEFGHIJKLMNOPQRSTUVWXYZafpqrstuvwxyz
有需要的人可以稍微使用這串來看看這範圍是不是有包含自己要的字,如果是用PC的話,可以直接開F12貼在Console上,我測試過應該是可以運作的。

這是使用時整理的,若有誤,歡迎告訴我!