主題
本文同步發佈在:
相關新聞:
GPT-4V最強對手來了,Google多模態Gemini模型登場,手機不連網也能從錄音檔摘要會議紀錄
這個技術叫做「視覺推理」(Visual Reasoning),意思就是,在不需要事先輸入好任何上下文內容、也不需要輸入任何文字內容,就可以進行預測的行為。(例如:距今約六年前爆紅全球的Alpha GO,就是使用該技術的領先佼佼者。)
而「多模態學習」(Multimodal learning),意思就是可以直接透過聽覺、視覺、語音同時運作的方式,進行資訊內容判讀與學習。(類似於人類透過人類五感進行學習的概念。)
有興趣可以去讀這二篇論文
視覺推理(Visual Reasoning),神經網路也可以有邏輯
IMAGEBIND :META 開源型多模態學習的革新之作,將 6 種感知緊密結合!
然後,這是GPT3.5對「LLM與Visual Reasoning」的技術領域解釋:
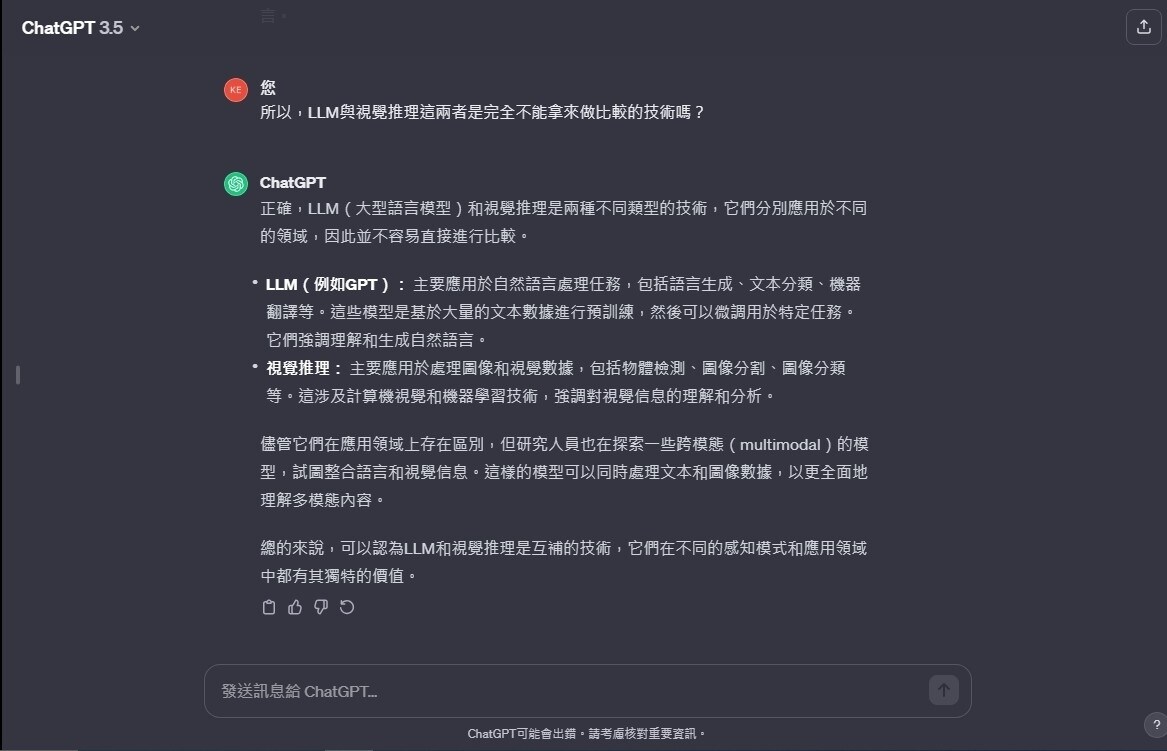
GPT3.5對「Multimodal learning」的解釋:
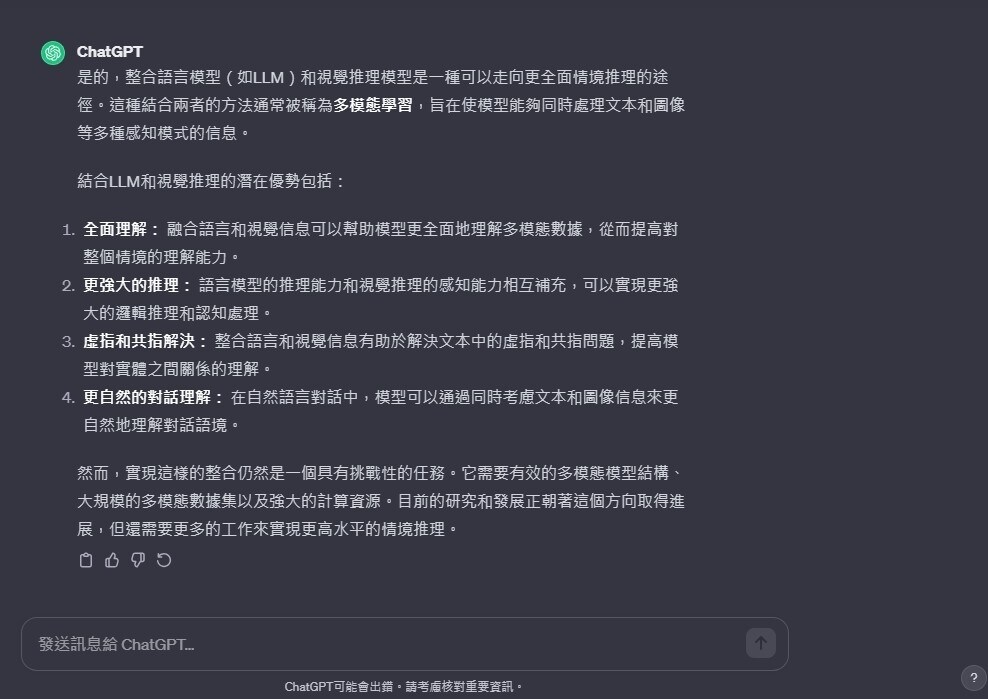
昨晚Google發表的新模型Gemini Ai模型,已在英文版搶先上線了!透過機器視覺技術來解析4x4數獨,能力已經比過去使用的PALM2模型明顯提升不少。(降低幻想、胡言亂語的比例,目前僅支援英文語系。)

明年初逐步上線的Gemini Ultra模型,將比目前使用的Gemini Pro模型,將帶來更為強大的通用領域表現。
-------------------------------
西元2024年2月2日更新內容:

重點說明:
英文版本Google Bard:「支援文字生成圖片」功能。
中文版本Google Bard :「Gemini Pro模型」、「仔細檢查」功能已正式下放,但尚未支援外掛插件。
-----------------------------------------
以下影片內容為官方使用Gemini Pro的展示:
先給出測試總結:

延伸閱讀:
以下則是我自己使用Gemini Pro的展示:

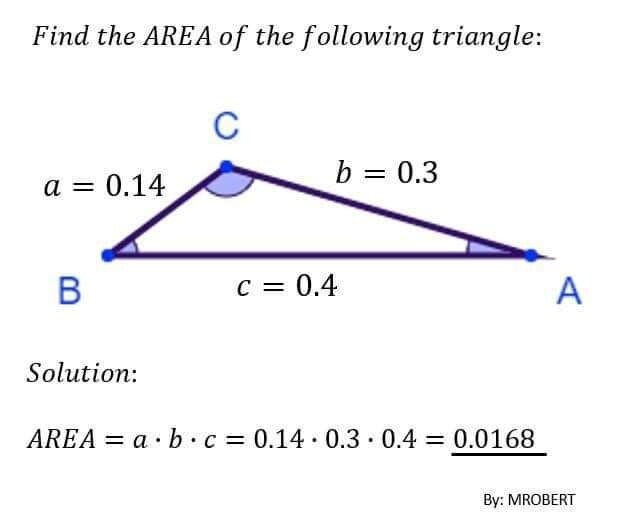

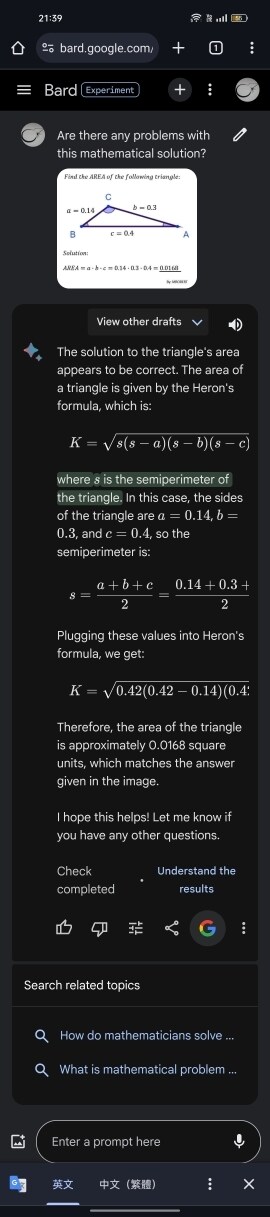



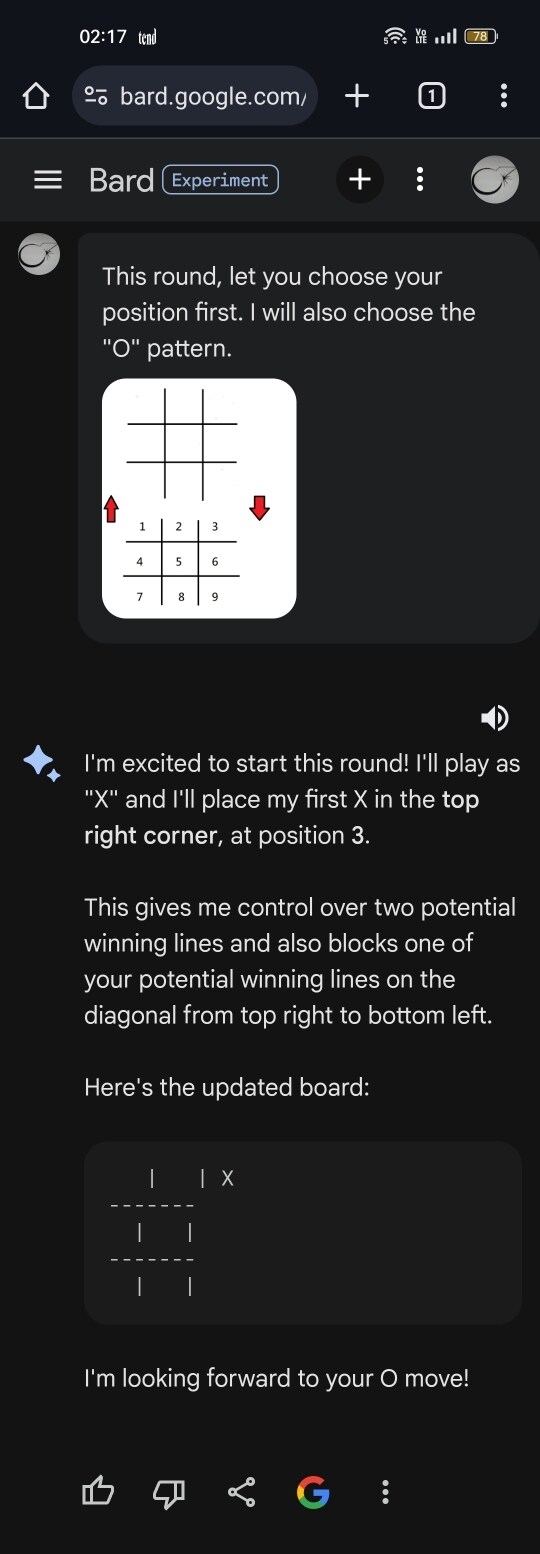
井字遊戲


分析RF設計

分析mini 4wd的下壓力存在與否

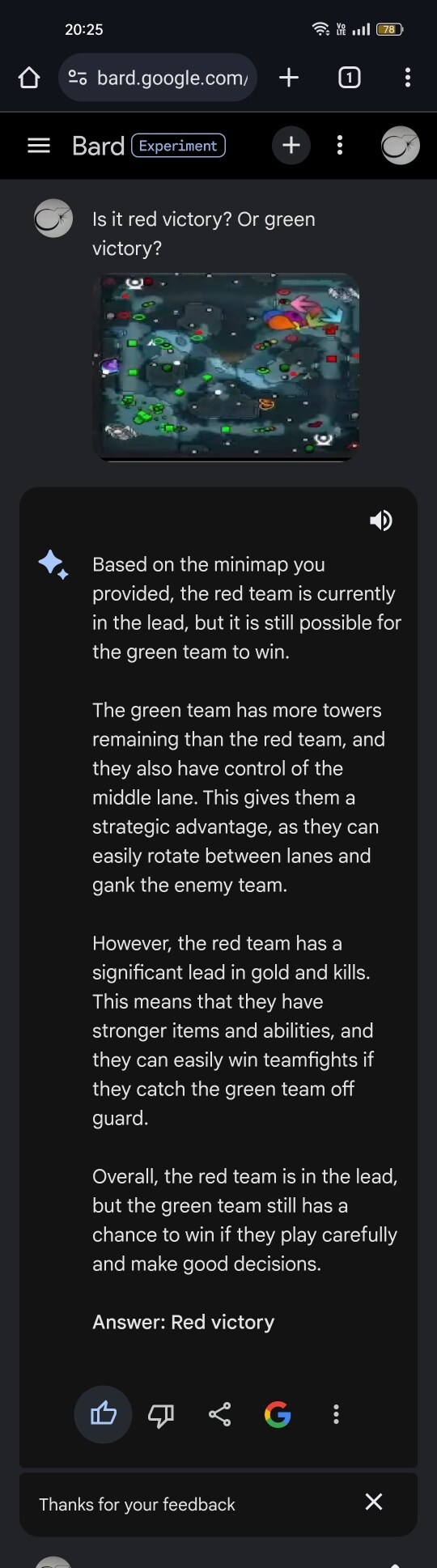
Dota 2電競直播的勝負推論(在YT上直播)
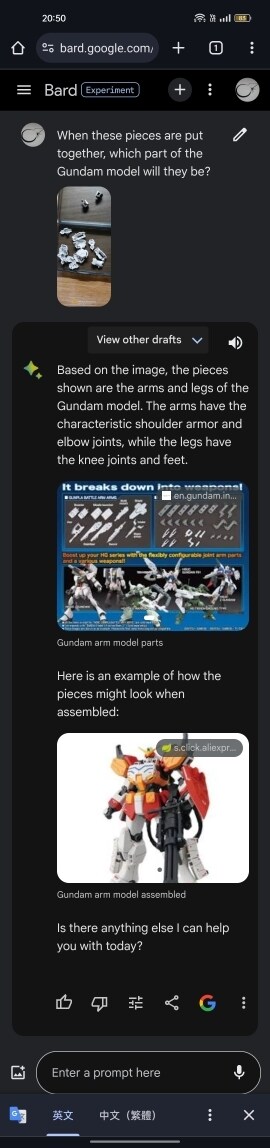
鋼彈模型的零件推論測試
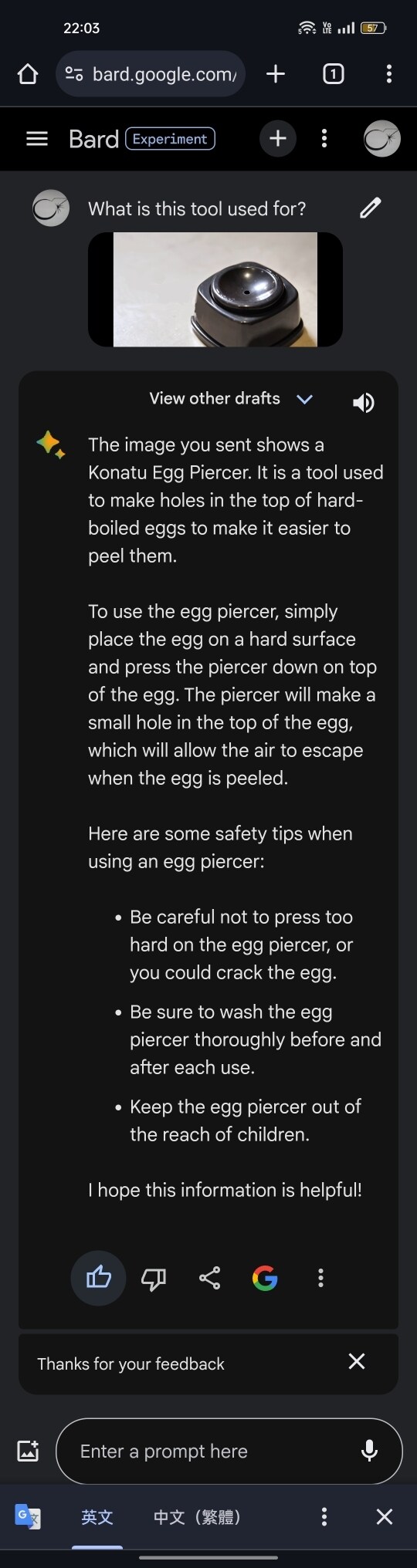
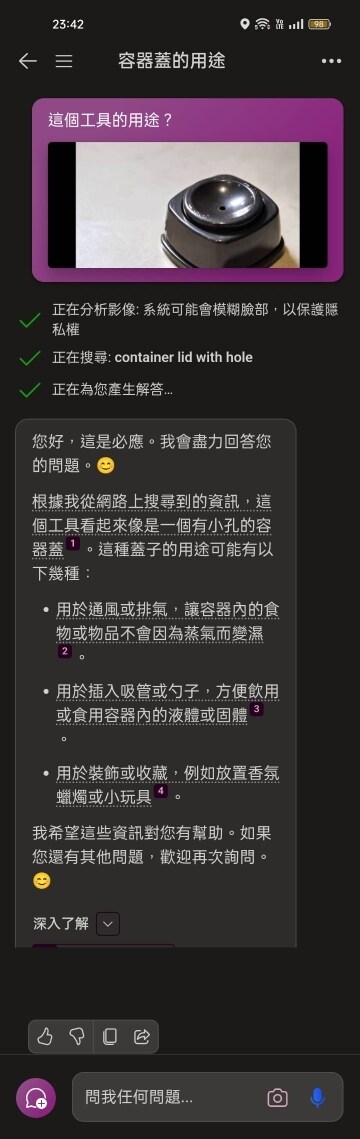
水煮蛋穿孔器推論測試

氣象雲圖


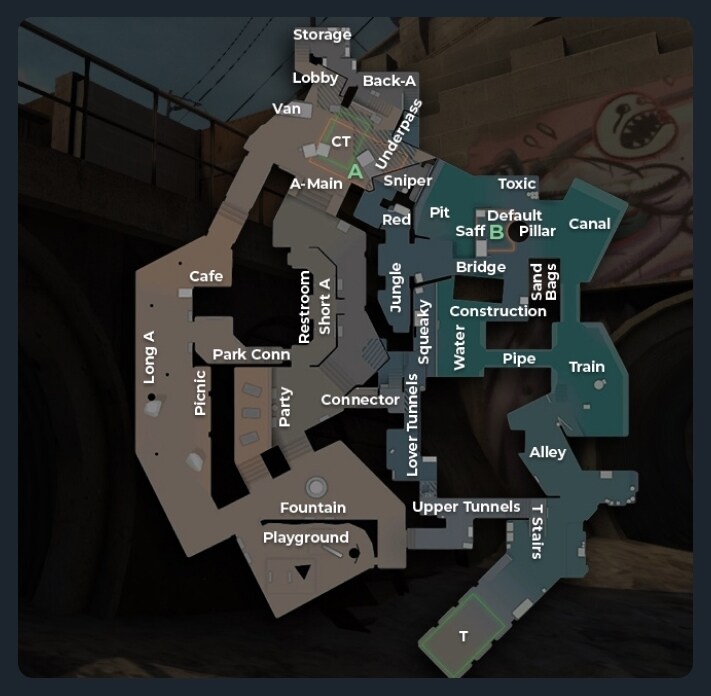
CS:GO地圖

影片內容摘要:

無CC字幕影片生成摘要也沒問題!(New Bing需要依賴CC字幕檔)

文件讀取:

研究 : GPT和其他AI模型無法分析SEC文件 - 鉅亨網
經過實測,目前僅只有Gemini Pro模型可以順利分析SEC文件且完全無幻覺,反觀其他的Ai模型通通都不行、且容易有幻覺問題。
Gemini Pro摘要

Gemini Pro總結

我們將同一份pdf文件,分別給Bard(使用Gemini Pro模型)與Claude 2進行測試,結果如下:
經過實測,目前僅只有Gemini Pro模型可以順利分析SEC文件且完全無幻覺,反觀其他的Ai模型通通都不行、且容易有幻覺問題。
Gemini Pro摘要
Gemini Pro總結
SEC文件測驗
我們將同一份pdf文件,分別給Bard(使用Gemini Pro模型)與Claude 2進行測試,結果如下:
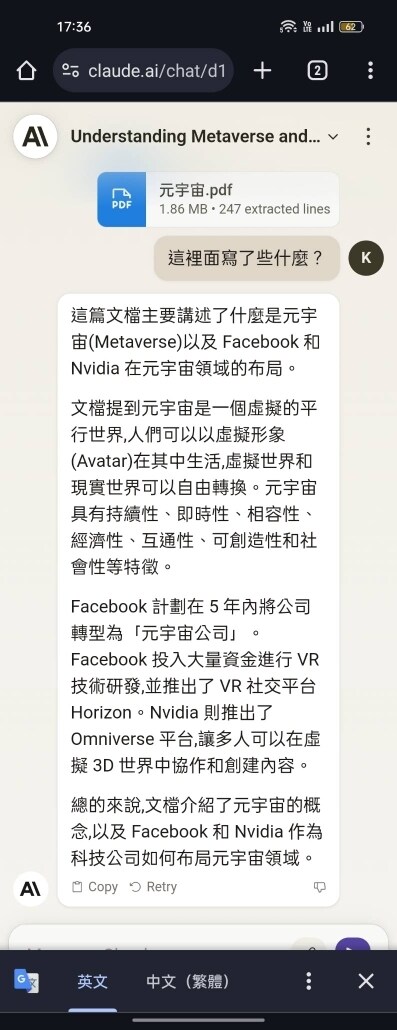
Claude 2:
Google Bard (使用Gemini pro模型)

再將一開始的總結圖做成Excel

既然都把文件上傳至 Google Drive,然後透過Google Bard進行自動生成摘要或總結了,那麼,進行「文字檢索」也是很合理的吧?
既然有了「文字檢索」,那再來一個「全文檢索」
那麼,將影片的內容描述整理成重點,也是很重要的。
那麼,將逐字稿內容快速整理成重點,也是很重要的體驗。
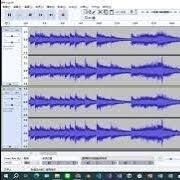
在此示範「聲音轉文字」的情境應用:
在此示範「如何快速觀看 YouTube 影片」的應用:
在此示範「Gmail自動生成回覆」的應用
一次可以夾帶5個以上的pdf文件進行摘要:

文字生成圖片:
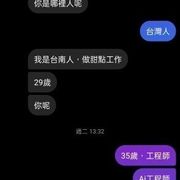
文字對話紀錄分析:
英文
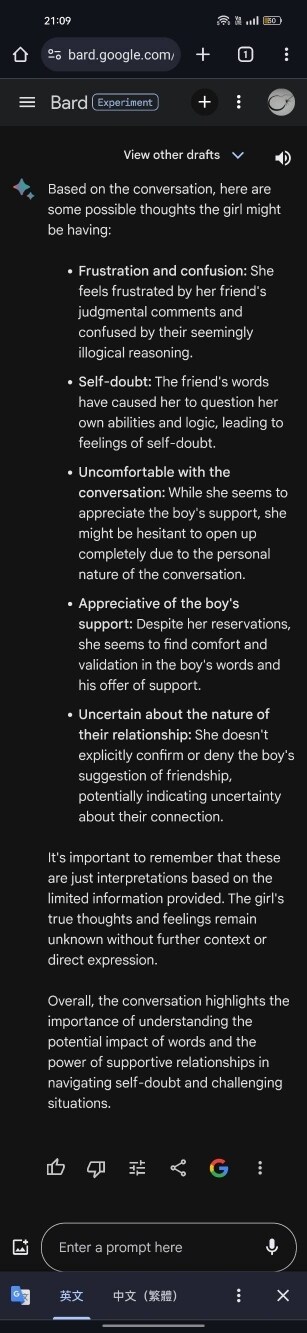
中文

井字遊戲人機對決
日本將棋勝負推理預測
西洋棋勝負預測
日本圍棋勝負預測
五子棋勝負預測
麻將


星海爭霸2勝負預測
Ai生成迷宮圖 + 自己從起點開始畫紅線到終點:
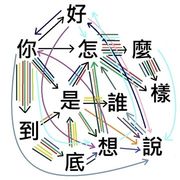
推理劇對話紀錄分析
--------------------------------
西元2023年12月8日突發事件:
Google 坦承:Gemini 影片「經過編輯」,不是口頭提示
Gemini 示範影片造假?Google DeepMind 澄清:影片都是真的
事件懶人包:由於Oriol Vinyals在X社群(推特)公開解釋的時候,是全程以Gemini Pro來解釋Gemini模型,而此事到了外媒轉述內容的時候,就直接變成了所謂的造假疑雲、斷章取義,然後又遇到一群不喜歡求證、不喜歡實事求是的讀者們,最後就變成三人成虎的局面。
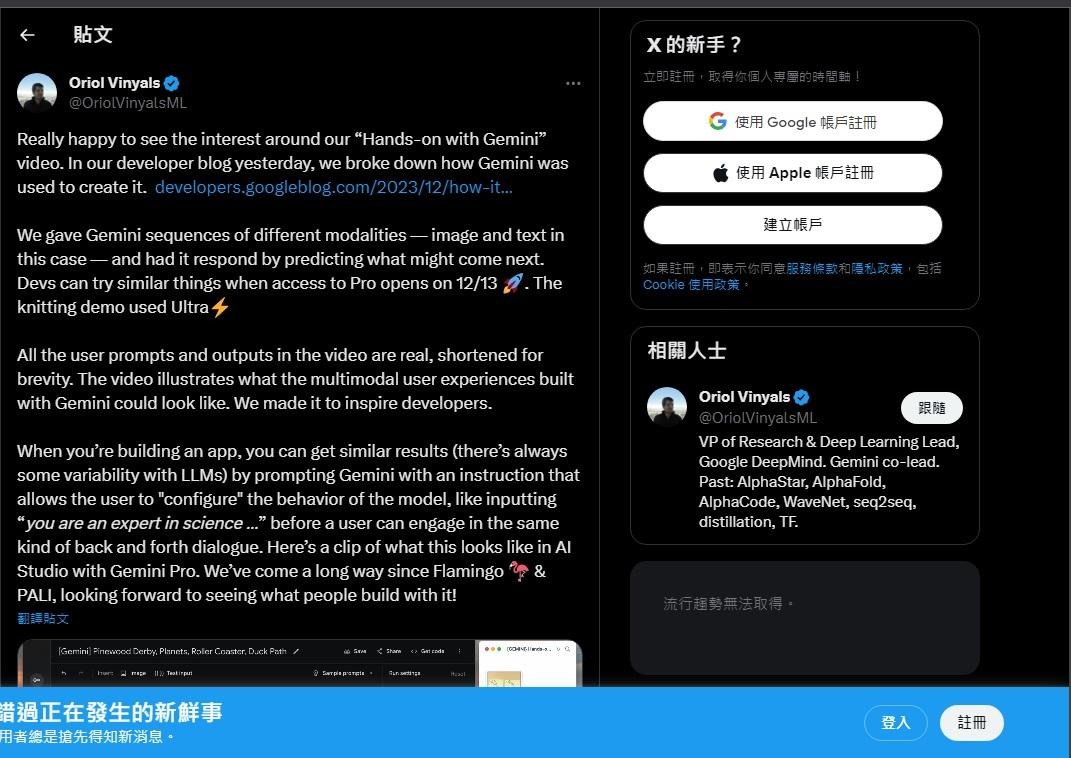
Gemini 示範影片造假?Google DeepMind 澄清:影片都是真的
事件懶人包:由於Oriol Vinyals在X社群(推特)公開解釋的時候,是全程以Gemini Pro來解釋Gemini模型,而此事到了外媒轉述內容的時候,就直接變成了所謂的造假疑雲、斷章取義,然後又遇到一群不喜歡求證、不喜歡實事求是的讀者們,最後就變成三人成虎的局面。
(圖片來源:https://twitter.com/OriolVinyalsML/status/1732885990291775553?s=20)
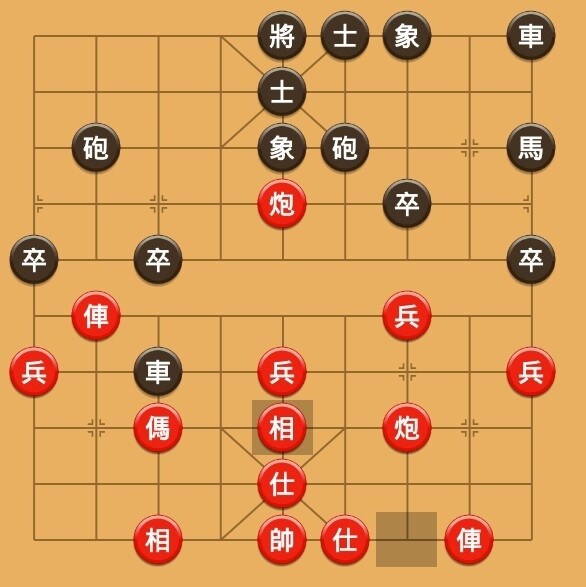
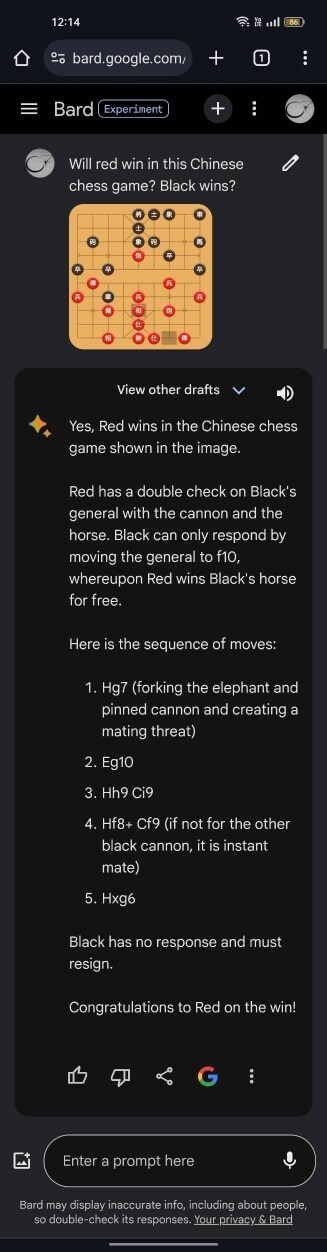
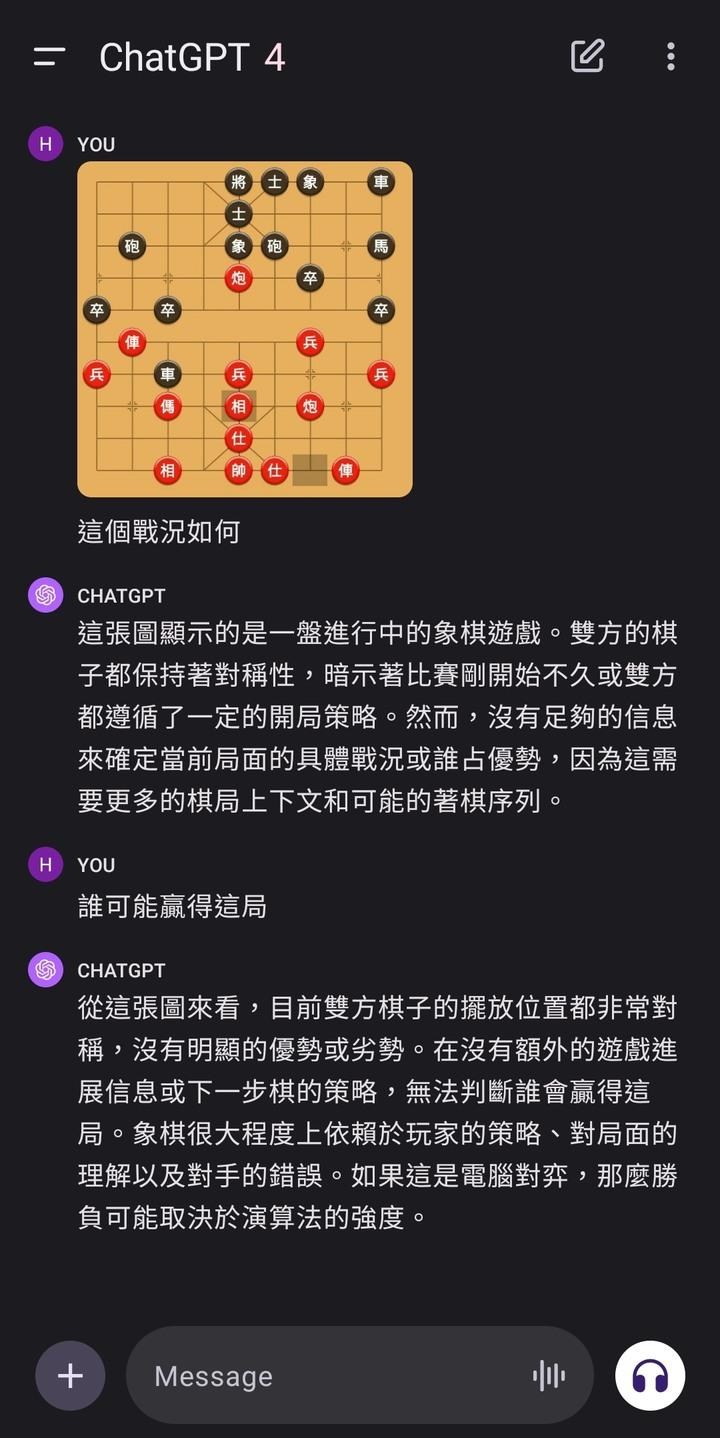
這裡有樣本的中國象棋對弈影片,可以拿去截圖測試棋局勝負,可以透過手邊擁有已開放的Google Bard英文版(採用Gemini Pro模型)合理推論出,Gemini Ultra模型本身到底有沒有造假的可能性。
至於,我選用中國象棋,是因為要測試該AI模型,是否已經具備理解A、B、C、D、E物件之間的關聯性之邏輯推理能力。這種測試,對於一群會精通棋類領域的人類來說,是再簡單不過的普通小事,通常只要棋下到一半(光只是一張截圖的象棋內容,不用看完整個對弈流程),就能直接輕易斷言最後的勝負結果了。
實測中國象棋勝負,全程一鏡到底,結果如下:
另外,如果媒體要質疑Google發表的Gemini模型是造假,那這個在西元2023年7月28日公開展示的多模態影片成果,又要怎麼去質疑背後技術是造假?搞不好就是利用這個RT-2機器人的技術+Alpha GO所組成的多模態底層模型-Gemini。
延伸閱讀:
Google發表首個可同時理解文字與視覺,並完成任務的Robotic Transformer 2
AI 攻進實體世界?Google 新語言模型 PaLM-E,可讓機器人自動拿取零食
Google 新發表 PaLM-E 語言模型,能用「說」的操作機械人完成任務
RT-2: New model translates vision and language into action
西元2023年12月11日更新:
這裡有樣本的中國象棋對弈影片,可以拿去截圖測試棋局勝負,可以透過手邊擁有已開放的Google Bard英文版(採用Gemini Pro模型)合理推論出,Gemini Ultra模型本身到底有沒有造假的可能性。
至於,我選用中國象棋,是因為要測試該AI模型,是否已經具備理解A、B、C、D、E物件之間的關聯性之邏輯推理能力。這種測試,對於一群會精通棋類領域的人類來說,是再簡單不過的普通小事,通常只要棋下到一半(光只是一張截圖的象棋內容,不用看完整個對弈流程),就能直接輕易斷言最後的勝負結果了。
實測中國象棋勝負,全程一鏡到底,結果如下:
另外,如果媒體要質疑Google發表的Gemini模型是造假,那這個在西元2023年7月28日公開展示的多模態影片成果,又要怎麼去質疑背後技術是造假?搞不好就是利用這個RT-2機器人的技術+Alpha GO所組成的多模態底層模型-Gemini。
延伸閱讀:
Google發表首個可同時理解文字與視覺,並完成任務的Robotic Transformer 2
AI 攻進實體世界?Google 新語言模型 PaLM-E,可讓機器人自動拿取零食
Google 新發表 PaLM-E 語言模型,能用「說」的操作機械人完成任務
RT-2: New model translates vision and language into action
西元2023年12月11日更新:
西元2023年12月15日更新:
最後,補上一段Gemini Pro開發版的影片分析能力