主題
 達(dá)人專欄
達(dá)人專欄
前言:
除了之前學(xué)理論外,這次是我第一次實(shí)做GAN,感謝這個(gè)頻道帶我們實(shí)作論文中的程式:Aladdin Persson - YouTube
我這篇做些額外整理與補(bǔ)充。
目前星爆AI智商 (因?yàn)橛?xùn)練資料太少,下一步大概會(huì)做自動(dòng)星爆資料處理):

程式一樣在個(gè)人網(wǎng)站閱讀比較方便喔~








生成對(duì)抗網(wǎng)路 (Generative Adversarial Network)
就是現(xiàn)在最夯的繪圖AI基本網(wǎng)路,他是由Generator和Discriminator組成,訓(xùn)練階段也分成兩種:
- 固定Generator參數(shù)並持續(xù)產(chǎn)生圖片,參雜真實(shí)圖片給Discriminator看,Discriminator要去分辨誰(shuí)是生產(chǎn)的,誰(shuí)是真實(shí)的,以此訓(xùn)練Discriminator。
- 固定Discriminator的參數(shù),Generator要學(xué)著產(chǎn)生會(huì)讓Discriminator誤判的圖片(真假難辨的地步),也就是目標(biāo)讓Discriminator誤判最大化。
製作Module
以PyTorch來(lái)講,pytorch主要分成torch.nn , torch.optim , Dataset , and DataLoader四個(gè)部分。Module歸類在Container下,是所有NN的基本類別,NN內(nèi)的內(nèi)容皆須繼承自Module。且必須初始化父類別與前向傳播(forward)。
[官方範(fàn)例]
[範(fàn)例] 基本NN:將輸入的數(shù)值+1
產(chǎn)生文字圖片
以最入門(mén)的MNIST資料庫(kù)為例,使用GAN產(chǎn)生文字。
定義Disc和Gen:
*Gen通常會(huì)比Disc多一個(gè)雜訊參數(shù)。
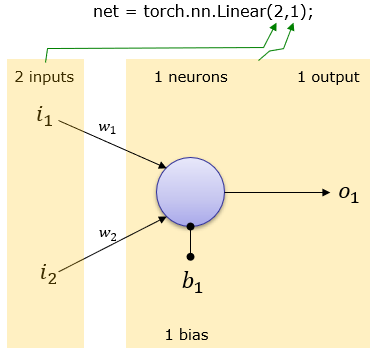
Linear層 (全連接層)
最基本的概念如同我們國(guó)小學(xué)的:y=ax+b , a是權(quán)重,b是位移。
torch.nn.Linear(in_features, out_features, bias=True, device=None, dtype=None)
[範(fàn)例]
需要注意的是他輸出的shape:
Weight和Bias
預(yù)設(shè)值 ,會(huì)在每次反向傳播時(shí)更新。
,會(huì)在每次反向傳播時(shí)更新。
,會(huì)在每次反向傳播時(shí)更新。也可以自己設(shè)定初始值[1]:
LeakyReLU
ReLU是將所有的負(fù)值都設(shè)為零,相反,Leaky ReLU是給所有負(fù)值賦予一個(gè)非零斜率。[2]
LeakyReLU — PyTorch 1.13 documentation



[範(fàn)例]
Sigmoid
有點(diǎn)老的激活函數(shù),後期之後就比較少人用(?),主要是他的曲線有點(diǎn)曖昧(且計(jì)算量比ReLu大)[4]。
[範(fàn)例]
Loss函數(shù)
Loss函數(shù)[6]定義了誤差距離,最簡(jiǎn)單的L1是取直線距離,L2取直線平方距離....到一些進(jìn)階的BCE取Log距離等等。 神經(jīng)網(wǎng)路追求的就是誤差(Loss)越小越好。
圖源










[範(fàn)例]
優(yōu)化器
優(yōu)化器幫助我們?nèi)ケ平繕?biāo)值,torch.optim有包含多種梯度下降演算法供使用。
目前的趨勢(shì)是會(huì)搭配動(dòng)能(momentum)來(lái)做梯度下降,就像下坡一樣,若動(dòng)能足夠的話就能幫助我們脫離Local Minima。
DataLoader
定義完處理模組後,就可以載入資料開(kāi)始訓(xùn)練。
- batch_size : 一次幾張。
- shuffle: 是否洗牌 (混著抽)。
[範(fàn)例]下載MNIST資料集並建立Loader物件。
反向傳播(Backpropagation)
當(dāng)跑完Batch後得出Loss值,便可根據(jù)Loss值對(duì)神經(jīng)元的權(quán)重做調(diào)整。
以前我只知道大概,現(xiàn)在實(shí)做讓我有個(gè)機(jī)會(huì)更進(jìn)階的思考實(shí)際是怎麼做到的。 別忘記神經(jīng)網(wǎng)路就是將input經(jīng)過(guò)一系列的函數(shù)處理,如上圖,如果將處理的過(guò)程以公式攤開(kāi)來(lái)看,會(huì)是一個(gè)包含大量變數(shù)的式子,我們可以依Loss去對(duì)每個(gè)變數(shù)做微調(diào),可以得到各變數(shù)導(dǎo)數(shù)對(duì)於輸出結(jié)果差的比例[7,8]。
[範(fàn)例] 最基本的訓(xùn)練週期:
Loss的反向傳播為何能修改model的參數(shù)?
不知道你有沒(méi)有發(fā)現(xiàn)這個(gè)問(wèn)題,當(dāng)跑完上面的code時(shí),NN的參數(shù)就會(huì)被更新,optimizer.step是怎麼知道要更新誰(shuí)的?
爬了幾個(gè)討論串[9]後得知,torch的tensor類別會(huì)記錄他來(lái)自哪裡,且?guī)rad參數(shù)(如果 requires_grad=True),autograd系統(tǒng)就會(huì)自動(dòng)記錄一參數(shù)的變化,並在反向傳播時(shí)計(jì)算梯度。 ( Backward propagation is kicked off when we call .backward() on the error tensor. Autograd then calculates and stores the gradients for each model parameter in the parameter’s .grad attribute.[10])
做一次backward可以理解成對(duì)所有參數(shù)做一階偏微分,再做一次就是二階偏微分。
[實(shí)做]
定義參數(shù)
在上面我們宣告了Disc和Gen,這裡將他們實(shí)例化。
跑訓(xùn)練
跑25個(gè)Epoch:
參考文獻(xiàn)或建議閱讀:
- python - How can I fix the weights of 'torch.nn.Linear'? - Stack Overflow
- 啟動(dòng)函數(shù)ReLU、Leaky ReLU、PReLU和RReLU_qq_23304241的博客-CSDN博客_leakyrelu
- Day 16 Activation function之群雄亂舞 - iT 邦幫忙::一起幫忙解決難題,拯救 IT 人的一天 (ithome.com.tw)
- ReLu vs Sigmoid
- PyTorch學(xué)習(xí)之6種優(yōu)化方法介紹 - 知乎 (zhihu.com)
- PyTorch Loss Functions: The Ultimate Guide - neptune.ai
- 圖解反向傳播 Backpropagation. 圖解反向傳播 | by Chenyu Tsai | UXAI | Medium
- Backpropagation calculus | Chapter 4, Deep learning - YouTube
- Loss.backward() for two different nets - PyTorch Forums
- A Gentle Introduction to torch.autograd — PyTorch Tutorials 1.13.0+cu117 documentation