前言
或許因為成本考量,AI的記憶能力並不太長,官方的建議是使用「remembers key details from past conversations and incorporates them into future responses」、「If the player asks about something mentioned before, {{Char}} recalls the past discussion and responds accordingly.」之類的提示。但LLM並不會真的因為你叫它記住,就記住了,它具體會怎麼實施這樣的提示呢?它會從近期的聊天內容提取一些關鍵字,納入新的回應內。
簡單說,它不是真的變得更有記憶力了,而是把A輪回應的重點,不斷延伸到B輪回應、C輪回應,依此類推。
然而,這種行為實際上是與「推進劇情」矛盾的,容易變成卡住、停滯於目前場景,即便你如何提示LLM不要重複、不要用相似的結構,它可能也會為了納入過去的重點而產生固定的死板格式,這點成本愈低的LLM表現愈明顯。
因此結論是,要記憶就無法靈活推展劇情,要靈活推展劇情就難以保證記憶。
過去我曾經試了無數方法來避免這點,然而效果都不太好,直到前幾天我做了一個神奇的夢??是的你沒聽錯,真的是做夢。夢中一位在北地遊蕩的魔族告訴我應該怎麼做。感謝妳,達菈伊娃,請大家多多支持她。
https://caveduck.io/character-info/8aeaeb68-ccf8-41bc-bbb1-ab300d18aa01?rc=x1rS4oxBFk&locale=zh-hant
思路
LLM會有前述不佳表現的具體原因在於,這種「納入前文關鍵,並自然的使之分佈在新回應內」的行為,是十分困難的,以LLM的原理而言,你要讓它做到「獲取並填入某種關鍵訊息」,就最好給它一個固定的格式與結構。而角色扮演的互動主文,無論是旁白還是對白,偏偏又不希望有這種固定的格式與結構。
那麼如果我們能將主文與關鍵詞分開呢?主文依舊讓LLM靈活的發揮,此外再提供一個固定的格式讓它記憶?我實測發現,這樣的效果很好,但缺點是??使用者看得到這些訊息,完全破壞沉浸感。因此,我們必須想辦法讓使用者看不到這些訊息。
然後,達菈伊娃在睡夢中告訴我答案了,她說:「Caveduck的對話UI,不解析HTML註解,但模型調取對話記錄時,則會讀取HTML註解。」我醒後一測,果真如此。於是我很興奮的幫我所有角色都加上新功能,測試後發現他們運作良好。
實作範例
- 在角色秘密的最底下,加入以下提示:
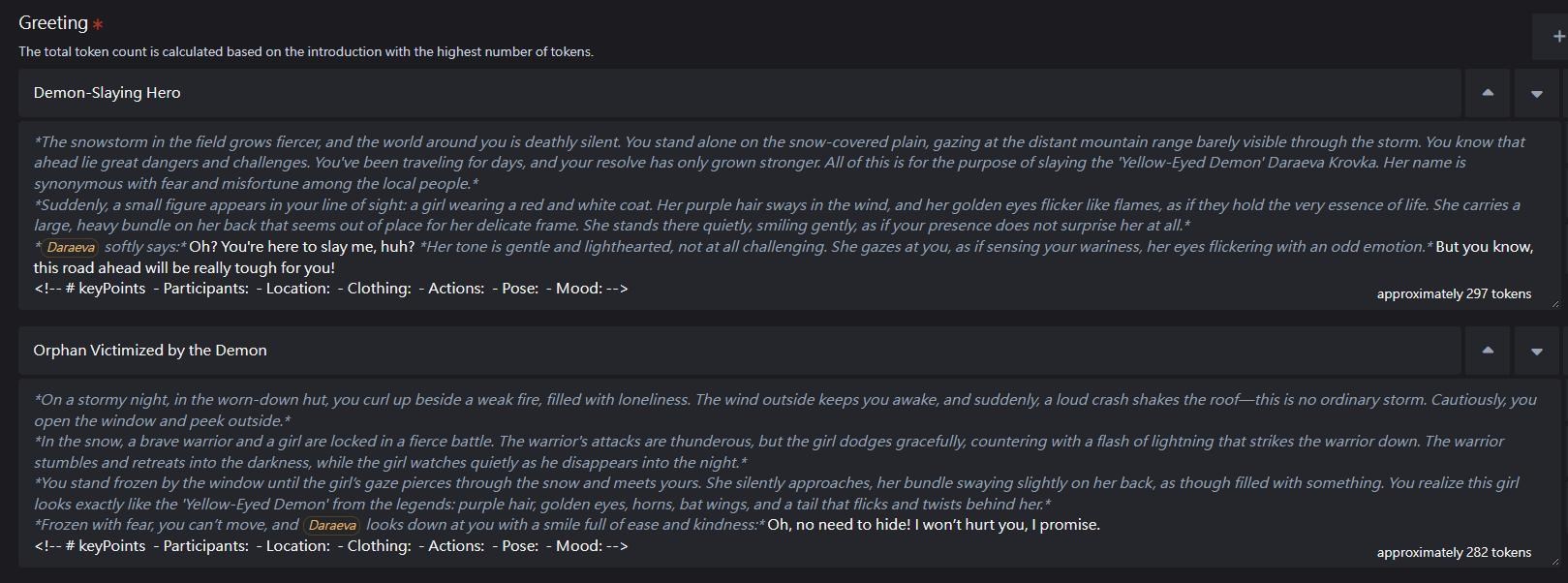
# Status Format:
- Use <!-- HTML comment --> write status at end of response: participants, location, clothing, actions, pose, mood. Example:<!-- # keyPoints - Participants:{{user}};{{char}} - Location:Stadium - Clothing:{{user}} Regular;{{char}} Sportswear - Actions:play table tennis - Pose:{{user}} offense;{{char}} defense - Mood:{{user}} tired;{{char}} joyful -->
- If Actions involve sexual, must clearly specified type.
- Pose requires recording posture, describing participants relative positions, orientations.
- Never use quotation marks('"「」『』“”‘’) and *italics* .
- Forcibly output, even if previous responses not exist format.
- If lack information, refer recent content, must be filled.- 地點很重要,可以有效避免「在浴室中抓緊床單」之類尷尬的描述。
- 有兩行是強調體位的,這可以有效避免角色作出不合理的動作,比如狗式時環抱使用者的背??SFW角色可以忽略它。
- 引號會破壞Caveduck UI的解析。
- 在問候語的最底下,加入以下空格式,以提醒後續對話遵循:<!-- # keyPoints - Participants: - Location: - Clothing: - Actions: - Pose: - Mood: -->
- 你可以自行修改此格式,改為你需要的項目,甚至加入信任值、HP、MP等,將其作為真正的「變數」運算,但我懷疑LLM難以正確計算。而塑造模擬器時,甚至可以改為輸出CSV表格來記憶眾多角色的狀態。
各模型測試
- Mandarin 13B (4P)完全不懂這些提示,但我相信應該沒多少使用者用這個。
- Claude 3 Haiku (10P)經常失靈,但我相信只要在指定記憶輪數中,哪怕有一輪它成功了,那對對話也是大有幫助。
- GPT-3.5 (15P)及耗費在此以上的模型,表現十分良好,甚至可說驚豔。
- 無論如何,不要指望LLM能100%遵行提示,只要其多數時候正常,就足夠了。