1. 安裝Homebrew
適用於 macOS 系統的套件管理工具
在terminal輸入
| /bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)" |
2. 去github 載 llama.cpp
Mac用這個才能跑

| git clone https://github.com/ggerganov/llama.cpp.git |
3. 下載 7B LLaMA model
裡面是 model weights 和 tokenizer,其他size應該跑不動,
這個模型要有 license 才能用,到 meta 網站申請:https://llama.meta.com/llama-downloads/
超快,瞬間收到信,裡面會有等等要用的URL 。
| git clone https://github.com/meta-llama/llama.git |
其實只要下載 model文件 和 tokenizer 就好,我這邊就全部載下來,
要注意接下來建環境要用第2步驟的檔案去跑。
下載 md5sha1sum
| brew install md5sum |
不知道幹嘛用的,meta 說要載。
下載模型
| ./download.sh |
如果 terminal 找不到,就看一下檔案待在哪裡,直接 cd 到該資料夾給他絕對路徑再執行他。
成功的話,他會問你:
1. URL : 就貼上 email 收到的連結。
2. 選要下載的 model,就打 7B-chat (看你要下載哪個)。
開始下載
等待
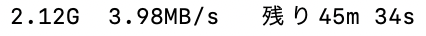
我是用Mac M1 剩下45分鐘 (電腦預設日文)
4. 建虛擬環境
a. 安裝 Anaconda
這個用來管理你的 virtual environment,
因為下載別人的 project 時,每個人的 project 用的 python 版本可能都不同,所以要建不同環境給不同版本,才不會彼此打架。
b. 先確保你在步驟2的資料夾,或直接 cd 過去
| make |
c. 新增虛擬環境
| conda create --name llama2 |
虛擬環境的名稱自己取,我這裡是 llama2 。
d. 建好之後打開他
| conda activate llama2 |
e. 看一下python版本,如果很舊,就安裝一下
| conda install python=3.11 |
5. 下載要用到的套件們(這些都會在虛擬環境裡面)
| python3 -m pip install -r requirements.txt |
6. 把模型轉換成可以執行的格式
把 consolidated.00.pth 轉成 ggml-model-f16.bin
| python3 convert.py --outfile models/7B/ggml-model-f16.bin --outtype f16 ../../llama2/llama.cpp/meta_models/llama-2-7b-chat |
output file 在 models 資料夾的 7B ,這時會發現 models 資料夾沒有東西,就手動新增資料夾,命名 7B 。
後半段寫到模型的位置,就自己找一下模型存去哪後修改即可。
轉換完發現模型有 13.48GB 好大。
7. 把模型變小(量化)
| ./quantize ./models/7B/ggml-model-f16.bin ./models/7B/ggml-model-q4_0.bin q4_0 |
前半段是剛才轉換完的模型,後半段是縮小後的模型,會變成 3.83GB ,存的位置相同。
8. 前置作業完成,終於要執行 LLM
| ./main -m ./models/7B/ggml-model-q4_0.bin -n 1024 |
-n 指定模型要輸出的 token 數量(最大長度),這裡是 1024 ,你可以自己決定。
9. 用例子來試
| ./main -m ./models/7B/ggml-model-q4_0.bin -n 1024 --repeat_penalty 1.0 --color -i -r "User:" -f ./prompts/chat-with-bob.txt |
-color 指定對話過程的文字顏色
-r 引導你要回覆 prompt 的地方
-f 指定要用的例子(在檔案夾 prompts 中)
總之結果長這樣:

done
參考:
完全參照:
虛擬環境怎麼建看這裡:https://zhuanlan.zhihu.com/p/677576672