警告
此文章資訊過時,僅供參考。
可參考最新文章:
收集資料&前處理
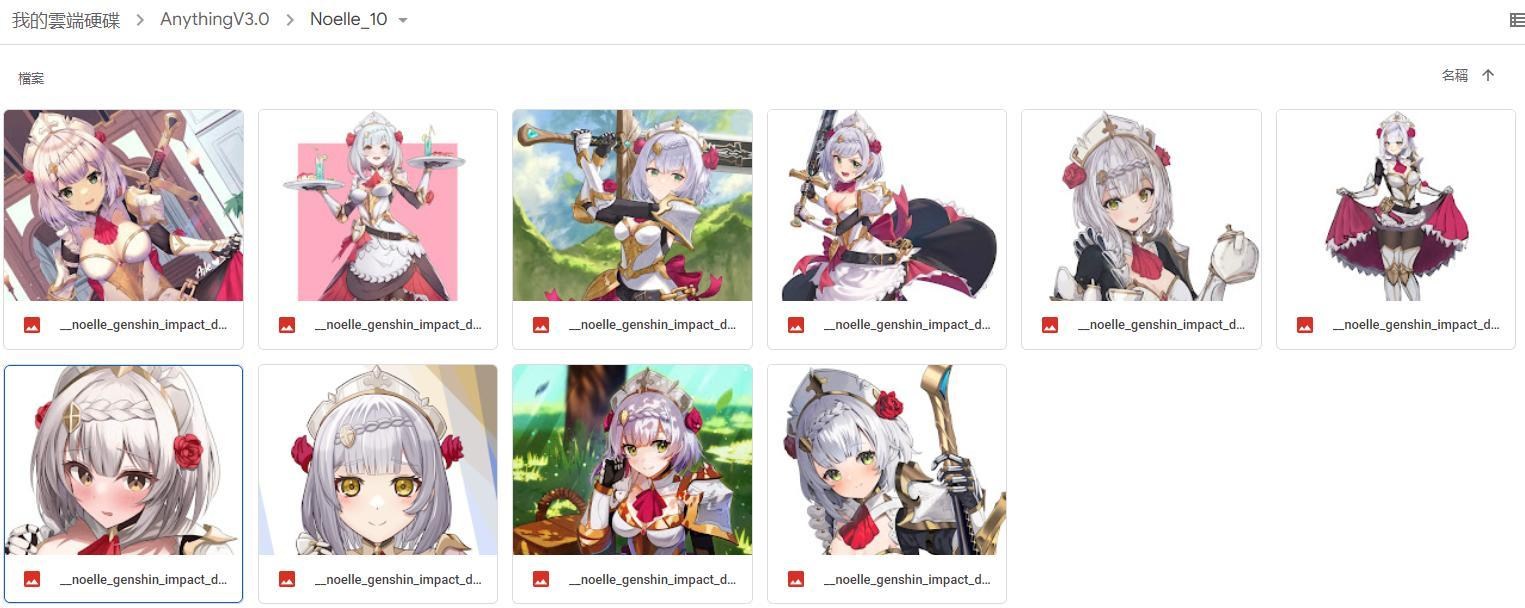
準備一個想要學習的概念的資料集,圖片的解析度都是512x512。
(註:其他比例也是可行的,以64為倍數,常用的像是512x768)
我是在Danbooru找圖,然後用Paint.NET做前處理。
需要注意的是LoRA訓練重質不重量,挑選品質好的圖片為優先。
以角色為例,服裝要一致,不能有多角色,否則會影響訓練結果。
接下來需要用到Webui,可以參考這篇文章。
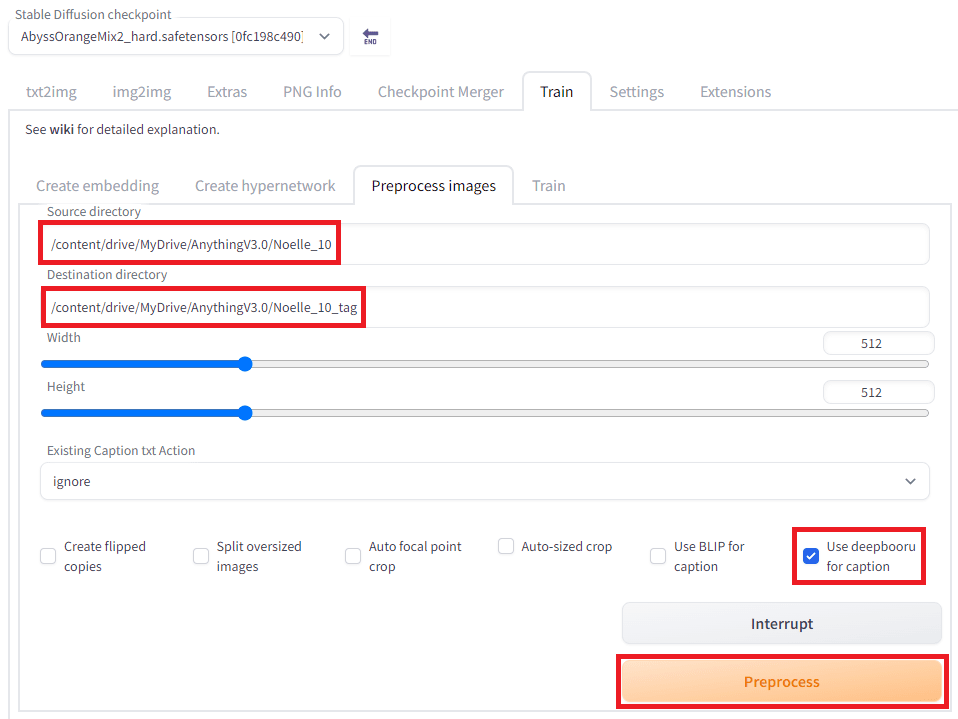
Train->Preprocess images
Source directory是原來的資料集位置
Destination directory是輸出的資料集位置
(註:如果圖片的解析度並非512x512,要記得設置Width和Height,不然圖會被裁掉)
設置完按下Preprocess
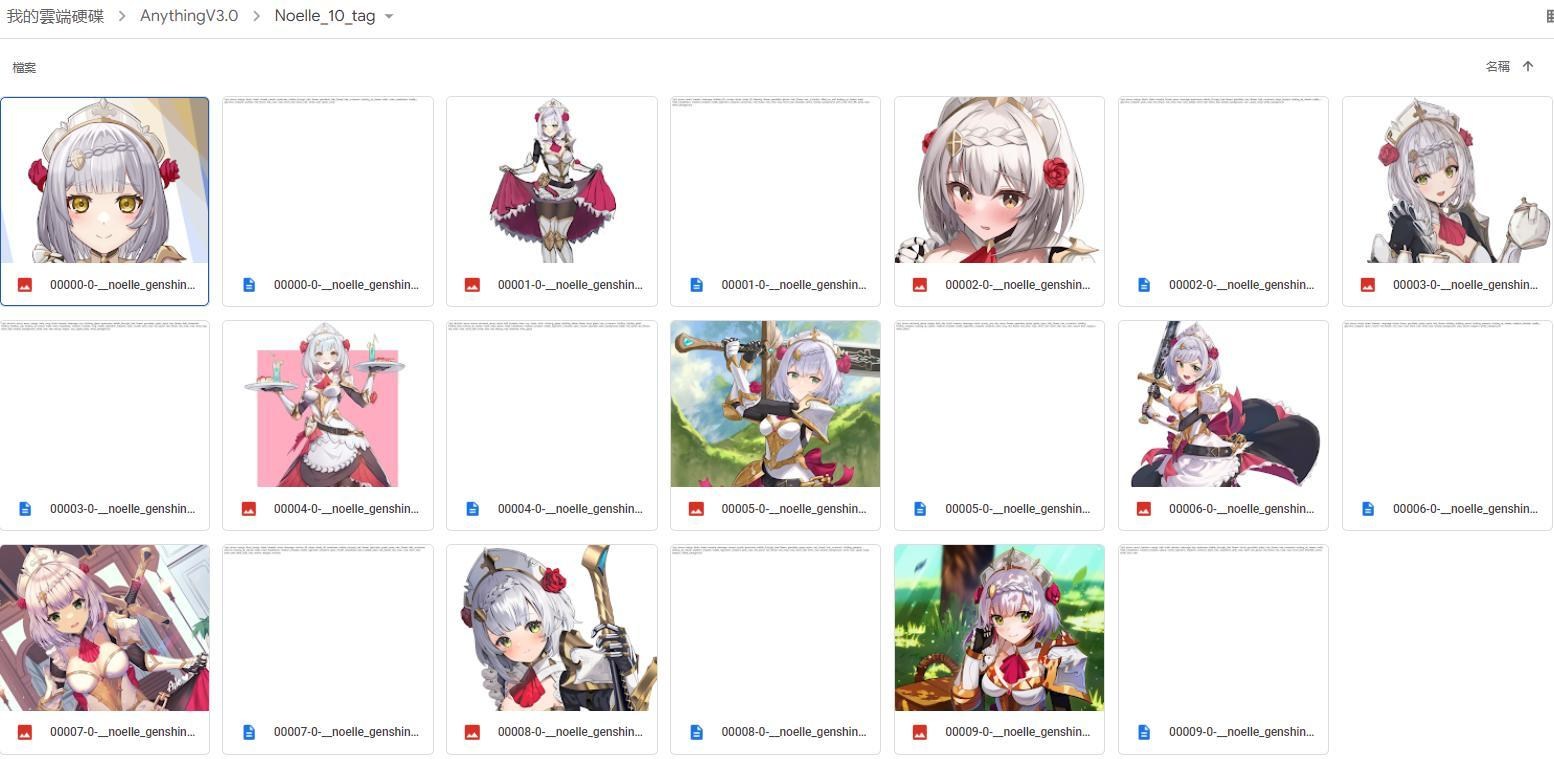
如此一來,包含Tag的資料集就完成了。
訓練LoRA
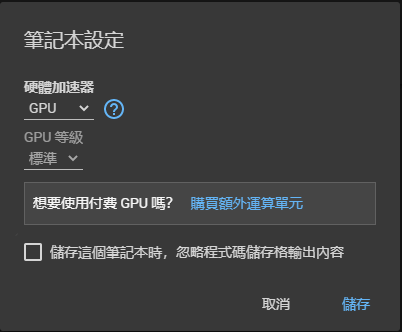
執行階段->變更執行階段類型->硬體加速器選擇GPU
掛接雲端硬碟

將資料集放在/content/drive/MyDrive/LoRA_training/datasets
資料集的名稱要跟專案名稱相同
在資料集內可以放若干個「概念資料夾」
資料夾名稱分成兩個部分
底線前是一個Epoch圖片重複訓練的次數
我的經驗是重複訓練數x最大訓練Epochs約等於200效果會比較好
底線後是「概念名稱」
訓練完LoRA之後就是用這個「概念名稱」觸發
資料夾的關係可以參考下圖

接下來就把前處理的資料丟到概念資料夾
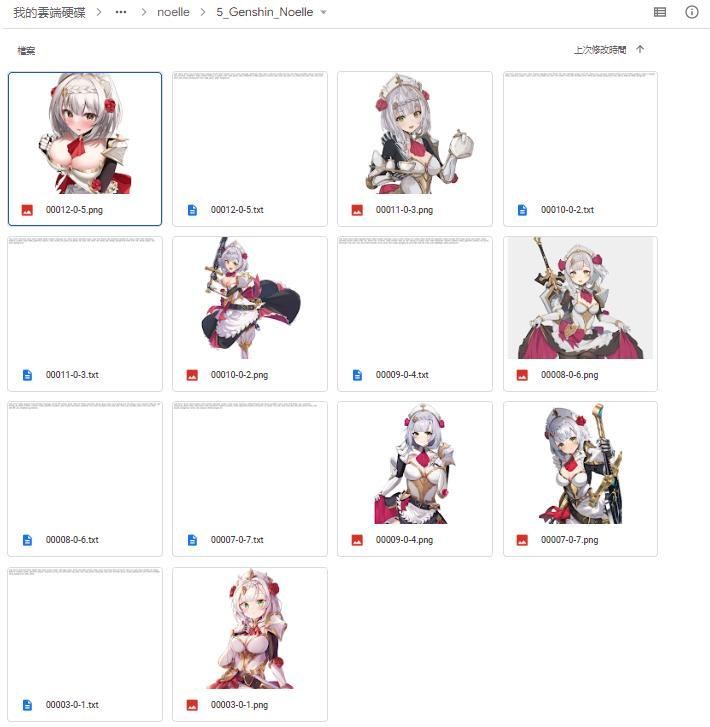
建立環境

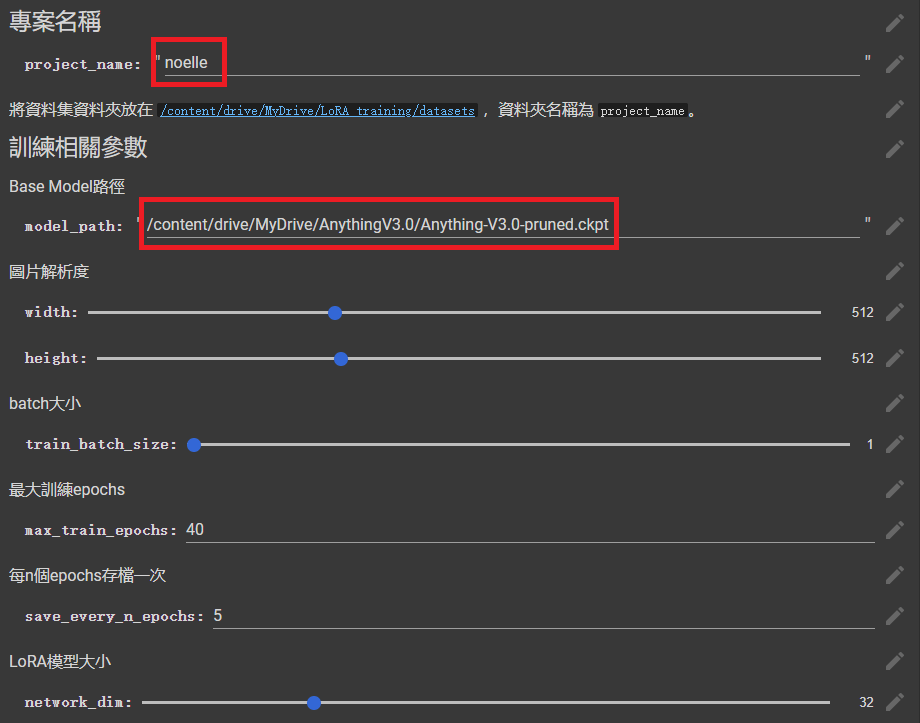
訓練參數設置
這裡主要改兩項
專案名稱和基底模型的路徑
如果特徵沒學好的話可以考慮增加最大訓練Epochs
(註:如果圖片的解析度並非512x512,要記得設置Width和Height)
改完參數後要記得執行
接下來就正式開始訓練LoRA了!
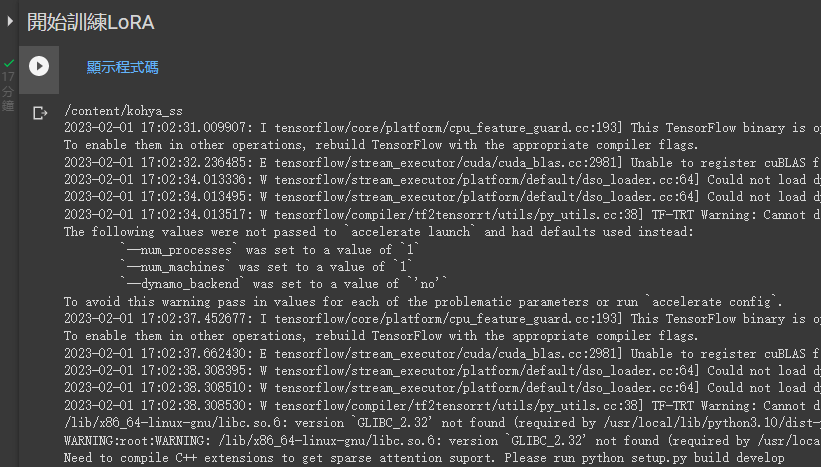
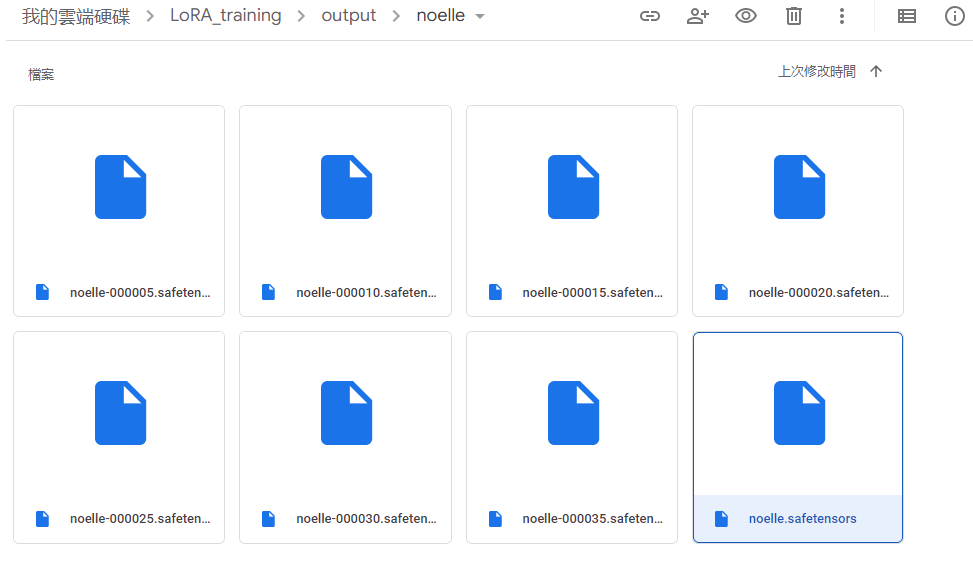
LoRA檔會放在/content/drive/MyDrive/LoRA_training/output
使用LoRA
接下來需要用到Webui,可以參考這篇文章。
Colab下載完stable-diffusion-webui
更改/content/stable-diffusion-webui/modules/ui_extensions.py
這樣之後Extension下載才不會被擋住


Extensions->Available
按下Load from

找到LoRA按下Install

中斷執行Webui
將LoRA檔複製到/content/stable-diffusion-webui/extensions/sd-webui-additional-networks/models/lora/
或是存在雲端硬碟用cp指令複製
這樣以後就不用每次都要上傳LoRA檔了

執行Webui
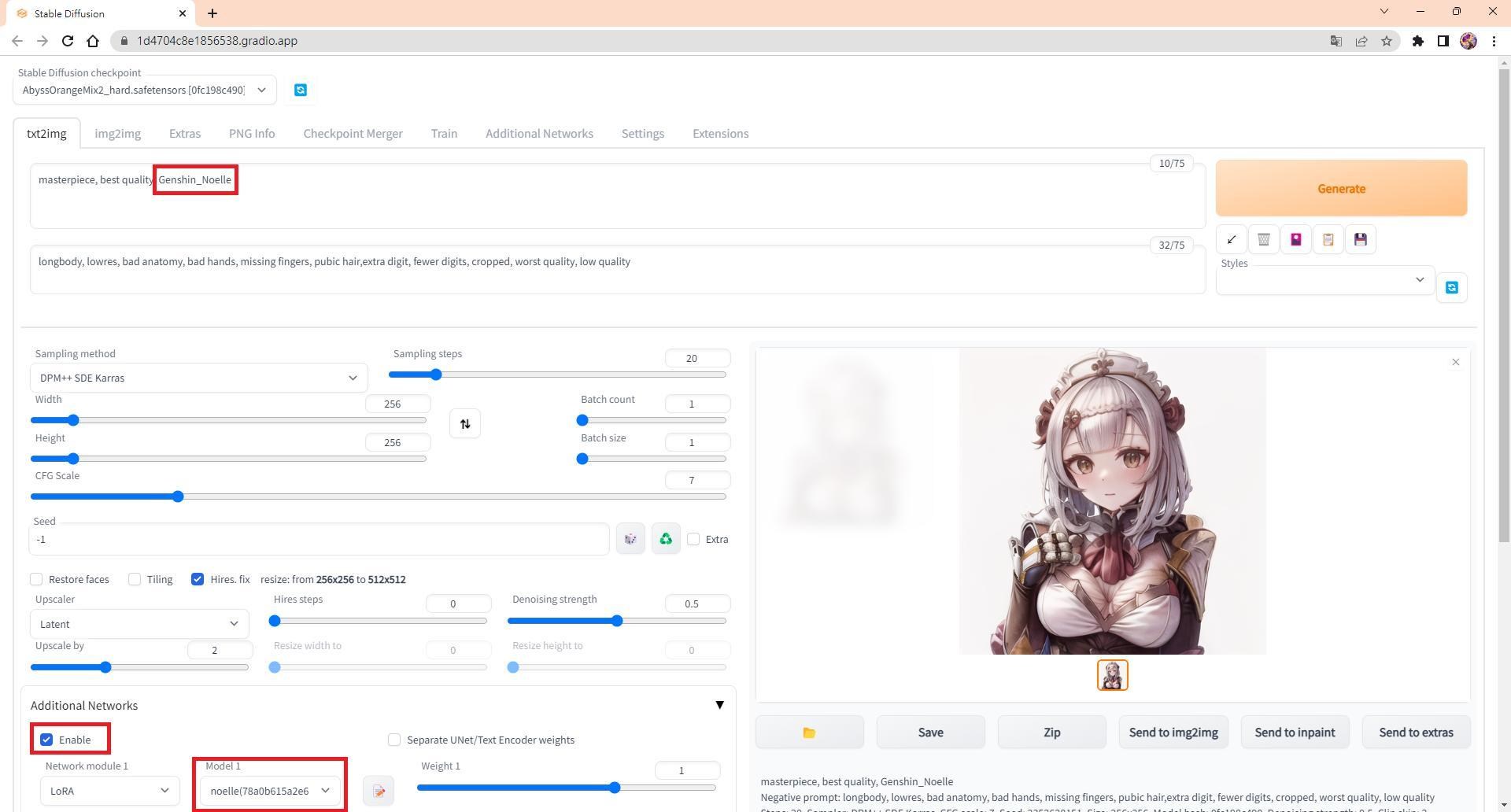
多了Additional Networks
勾選Enable和Model 1
Prompt輸入之前的「概念名稱」
Weight越高特徵越不容易跑掉
但自由度不高
Weight越低特徵越容易跑掉
需要其他Tag輔助(可以參考前處理時生成的Tag)
自由度較高
後記
後來我才知道資料集的背景都白色的話
會被當成是概念的一部分
所以背景可能還是要盡量多元
更新
2023/2/9 Colab新增use_shuffle_caption的選項
2023/2/10 Colab修正下拉式選單的bug
2023/2/11 Colab排除repo更新導致無法訓練的問題
參考資料
LoRA資源




























































