繼上一篇介紹了 stable diffusion 介面中 txt2img的功能後,這次來測試 img2img 的介面,順便試試用自己先前繪製 20周年的夏娜電繪作為原型,能用這個功能把圖片優化到什麼程度





其中,img2img 的介面如下
其中大部分的功能都和 txt2img差不多
不過在左側介面的部分─多了一個可以放置對比圖片的欄位與下方選擇圖片比例調整的模式(just resize/調整尺寸, crop and resize/裁剪與調整尺寸, resize and fill/調整尺寸與填充)~~ 雖然看起來好像只是調整圖片尺寸的選項,但測試下來意外會影響到最後輸出的結果 簡單來說,就是圖片尺寸調整的方式會影響到程式後續採樣與運算
簡單來說,就是圖片尺寸調整的方式會影響到程式後續採樣與運算
簡單來說,就是圖片尺寸調整的方式會影響到程式後續採樣與運算然後,不同的地方還有 CFG 下方的 Denoising strength,這邊調整的是跟參考圖的一致性,數值越低,調整的地方越少(與原圖一致性越高);反之,數值越高,則出來的結果與原圖關係差越遠~ 這點從下方的測試表格中可以很明顯看出來
雖然從上面的表格對比圖會覺得 img2img好像很厲害,一下子就抓到原圖的重點去做風格與圖片優化..........但,事實是─上方的展示圖已經是我調整好 prompt與 negative後的產物,如果都不去設定限制詞,出來的結果會是─
啊,我逐漸理解一切了(o?ω?o)
另外,只做negative prompt 會是這樣(我在用的negative prompt 可以參考上一篇)
( `Д′) 欸,不是─0.7 的時候已經是不同的作品了吧
然後 0.9是什麼呀~~ 我不明白呀(:з」∠)
總之,從上面的例子就可以知道調整 AI 繪圖的 prompt 真的有夠花時間,基本上如果是想要畫出特定的效果與構圖的話,是真的沒有自己手繪來的快啦~ 
於是,中間就是漫長的測試過程,其中關鍵字是"Shakugan no Shana (灼眼的夏娜_羅馬拼音)"─這個應該很直覺啦 以及一些對於服裝、表情、特定用色的prompt,畢竟動作已經有原圖可以作為參考........雖然動作會一直跑掉就是(我是用原本預設的0.75去跑,主要是限制得太死,基本上優化空間有限)
以及一些對於服裝、表情、特定用色的prompt,畢竟動作已經有原圖可以作為參考........雖然動作會一直跑掉就是(我是用原本預設的0.75去跑,主要是限制得太死,基本上優化空間有限)
以及一些對於服裝、表情、特定用色的prompt,畢竟動作已經有原圖可以作為參考........雖然動作會一直跑掉就是(我是用原本預設的0.75去跑,主要是限制得太死,基本上優化空間有限)以下就是一系列測試過程的存檔,其中主要是要找到合適的 seed(就是成是採樣的初始值,詳細內容可以見上一篇),再從seed中去進一步優化 prompt 中用字與權重
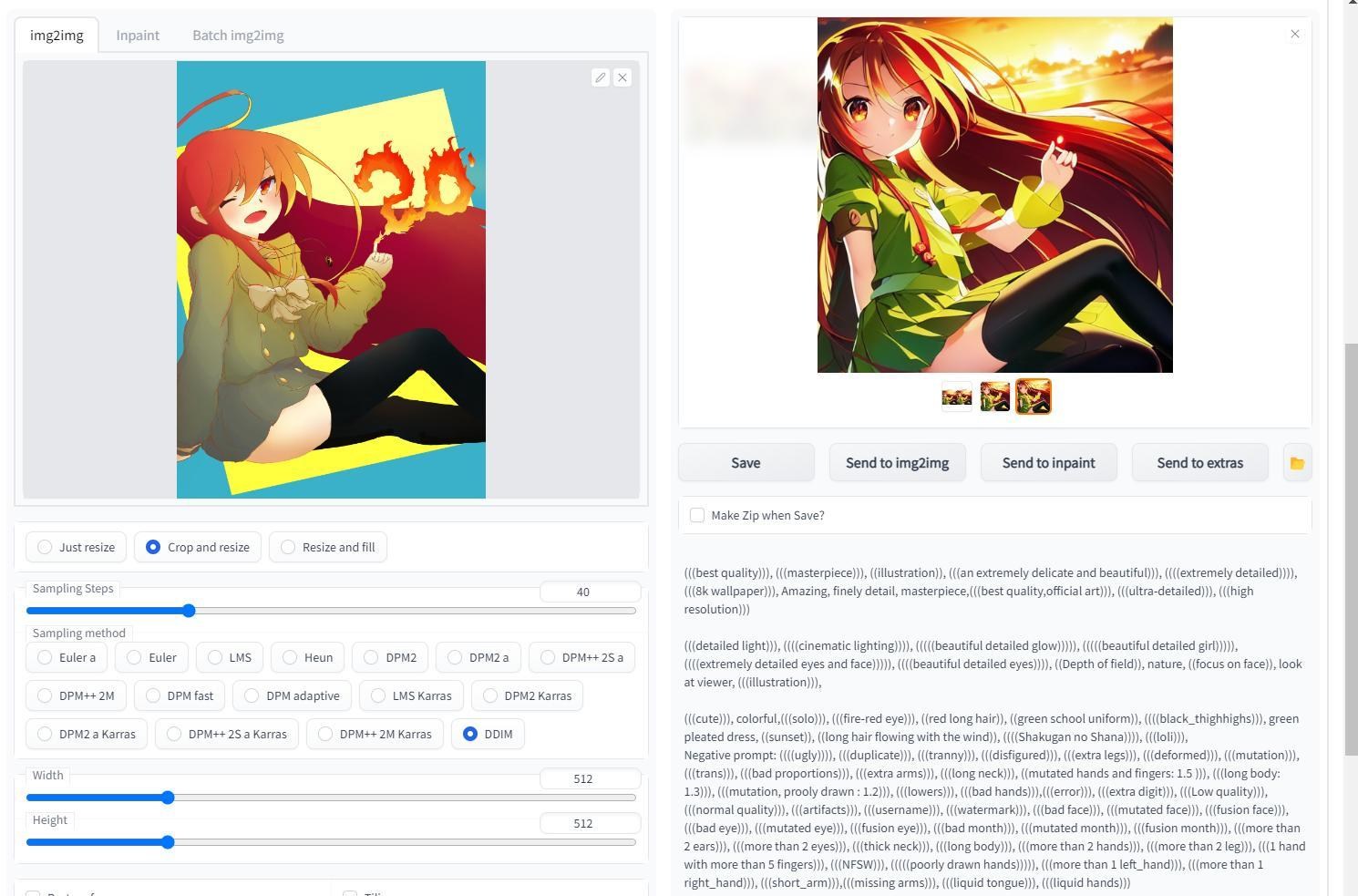
最後,出來的 prompt 如下,這是建立在seed: 3173218100之上
(((bestquality))), (((masterpiece))), ((illustration)), (((an extremely delicate andbeautiful))), ((((extremely detailed)))), (((8k wallpaper))), Amazing, finelydetail, masterpiece,(((best quality,official art))), (((ultra-detailed))),(((high resolution)))
(((detailedlight))), ((((cinematic lighting)))), (((((beautiful detailed glow))))),(((((beautiful detailed girl))))), ((((extremely detailed eyes and face))))),((((beautiful detailed eyes)))), ((Depth of field)), nature, ((focus on face)),look at viewer, (((illustration))),
(((cute))),colorful,(((solo))), (((fire-red eye))),((red long hair)), ((green school uniform)), ((((black_thighhighs))), greenpleated dress, ((sunset)), ((long hair flowing with the wind)), ((((Shakugan no Shana)))), (((loli))), ((smile))
出來的結果為下
最終覺得 smile 的版本比較貼近原本輕小說的風格,所以會選擇這張做為一個結束點.....不過,制服的樣式、手指的數量(4根手指)、天壤劫火的項鍊、手指上的火焰等都還有調整的空間,基本上可以當成是完全不同的圖就是了
但好不好看,那是真的好看呀 (?′﹃`?).........至少我應該是畫不出來(:з」∠)
最後,放個對比圖來自虐 然後結束這篇悲傷的文章
然後結束這篇悲傷的文章

















































