類神經網路 Artificial NeuralNetwork (ANN)
神經元模型
w(權重)1x(訊號)1+w2x2+...+b(偏權值) -> 門檻判斷 -> wixi
啟動函數
感知器
Sigmoid
Tanh
Softmax
ReLU
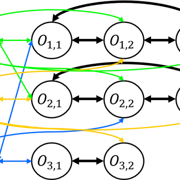
神經網路 由多層多個神經元組成
兩組花瓣長寬神經元
結果再加層組神經元
左圖經轉換變為右圖

早期神經網路
Input Layer + Hidden Layer (很多全連接層) + Output Layer

卷積神經網路
輸入透過濾波器filter 產生特徵
反覆 卷積Convolutional layer +池化pooling layer (降維)
取出影像低階特徵>高階特徵
拉平flatten 全連接分類Fully-connected layer 輸出層softmax layer

輸入層
卷積神經網路 輸入照片(含色彩三維) (矩陣)
cf. 一般神經網路 輸入向量
卷積層
濾波器filter + 特徵圖feature map + 激活函數activation function
透過濾波器 掃描輸入 (似相機濾鏡)

濾波器
找影像變化較大的地方 (微分)

zero padding
補多層0 還原影像大小 -> 濾波器 -> 產生特徵圖

使用激活函數ReLU (對於大於0的值微分為1)

池化層
最大池化 或 平均池化
(對於重複的特徵) 抓取特徵 去掉不重要部分
提升運作效能
控制過擬合
圖為最大池化 (平均池化求平均)

拉平

輸出結果 使用softmax挑出最大值使其介於0~1 加總為0

反向傳播
損失函數
分類問題使用 交叉熵cross-entropy
對預測機率與實際機率落差量化
(越相似 越小)


梯度下降修改權重 使損失函數最小化
學習率過大震盪 過小修正過慢

透過callback 調整學習率 (前期要大 後期要小)
-
卷積網路發展:
LeNet 1998
兩個卷積Convolutions + 池化Subsampling 全連接卷積 全連接層 Gaussian連接層 (output)
辨識手寫數字圖像
原圖 (32*32)
-> 使用6個濾波器 (6*5*5) -> (32-5)/1+1=28 特徵圖 步長1 (6*28*28) -> 28/2 平均池化 每兩個點選一個 (6*14*14)
-> 使用16個濾波器 (16*5*5) -> (14-5)/1+1=10 特徵圖 步長1 (16*10*10) -> 10/2 平均池化 每兩個點選一個 (16*5*5)
-> 打平 -> 全連接卷積 120個神經元 -> 全連接 84個神經元 -> Gaussian連接層 10種輸出 (數字辨識0~9)
使用Sigmoid激活函數
cf. 目前使用ReLU
output 使用 Gaussian
使用RBF函數 (徑向歐式距離函數) 計算輸入向量和參數向量的歐式距離
cf. 目前使用softmax

1998~2012沉寂
LeNet處理小數據很強 大數據很弱 -> 主流為機器學習
AlexNet 2012
ImageNet LSVRC競賽
使用深度學習 冠軍 Top-5錯誤率15.3%
遠超機器學習 第二名 Top-5錯誤率26.2%
5個卷積搭3個池化 三個全連接
全彩原圖 (3*227*227)
-> 使用兩組每組48個濾波器 (2*48*11*11) -> (227-11)/4+1 特徵圖 步長4 (2*48*55*55) -> (55-3)/2+1 重疊最大池化 尺度3*3 每兩個點選一個 (2*48*27*27)
-> 使用兩組每組128個濾波器 (2*128*5*5) -> (27-5)/1+2+2+1 特徵圖 步長1 (2*128*27*27) -> (27-3)/2+1 重疊最大池化 尺度3*3 每兩個點選一個 (2*128*13*13)
(零填充 每幅畫的左右兩邊和上下兩邊都要填充2個畫素、被減去的5也對應生成一個畫素)
-> 使用兩組每組192個濾波器 (2*192*3*3) -> (13-3)/1+1+1+1 特徵圖 步長1 (2*192*13*13)
(零填充 每幅畫的左右兩邊和上下兩邊都要填充1個畫素、被減去的3也對應生成一個畫素)
-> 使用兩組每組192個濾波器 (2*192*3*3) -> (13-3)/1+1+1+1 特徵圖 步長1 (2*192*13*13)
(零填充 每幅畫的左右兩邊和上下兩邊都要填充1個畫素、被減去的3也對應生成一個畫素)
-> 使用兩組每組128個濾波器 (2*128*3*3) -> (13-3)/1+1+1+1 特徵圖 步長1 (2*128*13*13) -> (13-3)/2+1 重疊最大池化 尺度3*3 每兩個點選一個 (2*128*6*6)
(零填充 每幅畫的左右兩邊和上下兩邊都要填充1個畫素、被減去的3也對應生成一個畫素)
-> 全連接4096個神經元 -> dropout
-> 全連接4096個神經元 -> dropout
-> 全連接1000個神經元 1000種輸出
使用ReLU
ReLU避免梯度過小
cf. Sigmoid收斂太慢
使用dropout避免過度擬合
使用資料擴增Data augmenttation
隨機裁減256*256圖片 水平翻轉、主成分分析(PCA) 高斯擾動
使用重疊池化
使用兩顆GPU平行運算
使用softmax

VGG 2014
ImageNet LSVRC 分類競賽第二名
更深 重複使用基礎模組
使用多層小卷積核代替一層中大型卷積核 減少參數量 避免過度擬合

VCG16
前2個卷積含2個基礎模組 後3個卷積內含3個基礎模組 3個全連接
全彩原圖 (3*224*224)
透過零填充控制影像長寬、透過濾波器數量調整深度
降維 深度加寬
64*224*224 ->
128*112*112 ->
256*56*56 ->
512*28*28 ->
512*14*14 ->
512*7*7 ->
...
-> 全連接4096個神經元
-> 全連接4096個神經元
-> 全連接1000個神經元 1000種輸出

Network in Network (NiN) 2014
三個 Mlpconv + Maxpooling 一個全局平均池化層(Global Average Pooling)
使用Mlpconv (MLP) 卷積層
一個卷積層後接兩個 1x1 的卷積層
將不同通道同一位置的資訊進行整合、通道的降維或升維

使用 GAP 代替拉平全連接層 降低參數量、避免過擬合



GoogleLeNet (Incecption-V1) 2014
ImageNet LSVRC 分類競賽第一名
參數少(避免過度擬合)
深度更深
準確度更高
使用NiN想法->Inceotion module 模組化設計

先使用多個1*1卷積核降低通道數及數量再做計算 (降低參數量、計算量)
(先降成1*1 再升成需要的)


多個濾波器以及池化結果以通道軸串接
儲存不同大小的特徵

使用輔助分類器解決深度過深梯度消失
損失函數是結果與輔助分類器加權總和
ResNet 2015
ImageNet LSVRC分類競賽冠軍
mageNet detection冠軍
mageNet localization冠軍
COCO detection冠軍
COCO segmentation冠軍
CVPR2016最佳論文
超深152層 (相較於20~30層的GoogLeNet)
錯誤率3.6% 低於人類錯誤率5.1%

兩種Residual Block (計算量差不多)
使用Residual Learning 解決退化問題(degradation)
殘差學習
Shortcut Connection結構-> 將輸入的x跨層傳遞
避開部分層的學習 將修正量往前送

DenseNet 2017
CVPR 2017 最佳論文

特徵重用feature reuse
多個layer全連線
看到更廣的特徵

EfficientNet 2019
使用複合係數 均勻縮放 網路層數(深度) 通道數(寬度) 圖像大小(解析度)


以B0為基礎
使用複合係數縮放 設計B1~B7系列