主題
延續(xù)之前的內(nèi)容

首先一樣是動態(tài)研究
算是隨便亂搞了一下
就直接看影片吧
那動態(tài)研究可能就先告一段落
接著之前沒提到的部分
嘴部的動態(tài)
當(dāng)然這邊也是有很多處理的方式
先前也提過使用Mesh來進(jìn)行點(diǎn)位的判斷,那也可以達(dá)到一定程度的動態(tài)設(shè)定
例如可以根據(jù)嘴的上下點(diǎn)位進(jìn)行判斷,然後模型就能以類似的狀況進(jìn)行動態(tài)設(shè)定
這邊也是對臉部的表情上進(jìn)行處理

首先我們可以先看到VRM模型上的這些參數(shù)
字面意思就是可以讓口型對應(yīng)A I U E O
因為嘴巴這邊沒有單純的開闔,但是有針對幾個發(fā)音保留了口型
這邊就提供幾個方案
首先就是透過語音辨識來辨識發(fā)音,然後對應(yīng)到表情上的嘴部參數(shù)上
因為這樣可以比較直接透過發(fā)音對應(yīng)到相對的口型上
口型上也會比較正確
那這邊一樣會有的問題是辨識能否準(zhǔn)確
另外影響比較大的則是辨識需要短暫的延遲,那口型延遲會很明顯的產(chǎn)生問題
畢竟說話是非常直接的,大家聽到聲音後發(fā)現(xiàn)嘴部明顯錯誤的話會很奇怪
所以這邊就會有另一個方案,也就是只針對音量處理
但是也保留可以更精細(xì)的操作,例如想要對口型的時候可以用mesh計算
想要針對講話口型則是使用語音辨識,這就是需要邏輯變換處理的地方
畢竟每一種單獨(dú)使用都會有一些狀況會無法處理
例如你想要單純張嘴給觀眾看或是表演什麼東西的時候
如果使用的是語音辨識或音量改變口型,則會造成嘴部完全不會動的,因為沒發(fā)出聲音
這時候就還是要Mesh點(diǎn)位計算才能派上用場
而這也是常見的做法之一,就是平常使用音量,然後口型使用比較通用的A跟O
畢竟多數(shù)人並不會在意模型到底嘴巴有沒有精準(zhǔn),反而是不要太奇怪就好
當(dāng)然很多遊戲的語音也都是類似的設(shè)計,偵測到音量,對A或O口型的參數(shù)調(diào)整,就有講話感覺了
那這邊針對音量檢測進(jìn)行一些說明

首先透過這個語法可以開啟麥克風(fēng)來獲取聲音的相關(guān)參數(shù)
當(dāng)然首先需要有個外接的麥克風(fēng),至於名稱會是自己系統(tǒng)設(shè)定的那一個
那我這邊則是也把獲取名稱的方式寫在前面了
如果不知道麥克風(fēng)的名稱,就用前面那邊的語法先取名稱
當(dāng)然這邊是可以設(shè)計成讓使用者選擇自己的對應(yīng)麥克風(fēng)
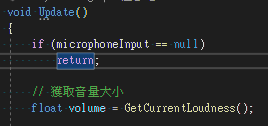
接下來我們在Update的地方執(zhí)行判斷音量
或是找一個可以穩(wěn)定執(zhí)行的地方也可以GetCurrentLoudness的內(nèi)容在下方
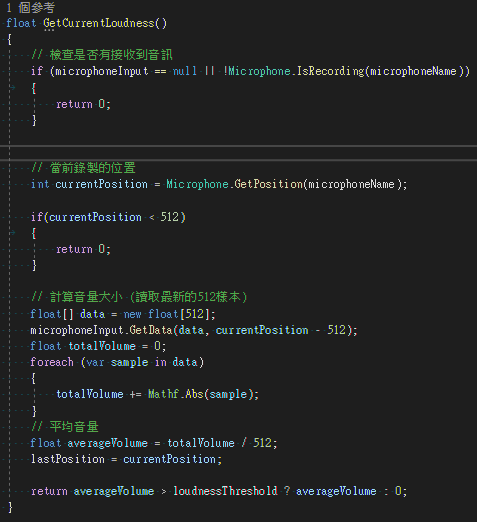
首先這邊可以看到我把聲音的前512取樣取出來進(jìn)行處理
因為剛開始開啟的時候是使用了44100取樣點(diǎn)
所以實際上這邊就是把聲音的512/44100秒拿進(jìn)去判斷,也就是大概0.01秒左右
這邊也是要確保update執(zhí)行速率等等的狀況
主要只取這麼短就是為了要夠即時反應(yīng),大家可以根據(jù)自己想要的效果調(diào)整
畢竟不管判斷怎樣的快都會造成延遲,只是延遲長短跟判斷的準(zhǔn)確度取捨的問題
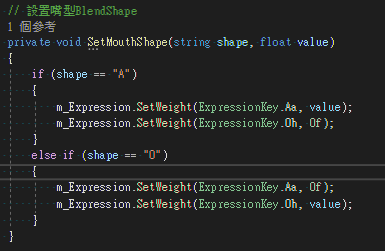
接著就是根據(jù)剛剛算出來的音量去做處理了
看是設(shè)定一個閥值,超過多少就要去做口型的操作
然後這邊也是提供看是要用A或是O,數(shù)值要多少等等的狀況
就可以根據(jù)自己需求調(diào)整
那詳細(xì)可以看以下的影片展示
那因為我影片沒有直接錄音進(jìn)去,所以特地在UI的地方設(shè)置了音量檢測的bar
可以觀察影片下方,那條bar是根據(jù)麥克風(fēng)的音量做顯示的
所以實際上是有開啟麥克風(fēng)進(jìn)行講話的,只是沒有在OBS中錄音進(jìn)去
直接就能觀察到目前設(shè)計的音量與口型之間的關(guān)係
那這次的筆記就先到這邊告一段落~
如果還有什麼疑問的話可以直接問