很多人看到ChaGPT,就越欲試,覺得AI對話用在NPC可行。
因此就有人利用OpenAI的API整合到遊戲,更有公司推出相對應(yīng)的開發(fā)工具。
我有整理一篇 AI記事-發(fā)生事件記下來
你會發(fā)現(xiàn),說話、聲音語氣、圖片、3D建模、遊戲生成等等,全部都已經(jīng)到位了,只差整合這個動作,而整合難麼?
也是有超簡單的,因為你只要知道API,都能做,這是軟體工程師非常容易做的事情。
不過API有個問題,
如果玩過chatGPT應(yīng)該會知道,他常常受限於提供的公司,
所以一定還是得回歸到怎麼樣在自己模型產(chǎn)生奇蹟?shù)膯栴}上,
我想目前大多共識已經(jīng)慢慢形成,就算沒講應(yīng)該,看到FB、微軟跟google他們最近幾個月做什麼,也該有點敏銳度,預(yù)訓(xùn)練的時代基本上已經(jīng)不是資本額沒超過10億美金的小公司能碰的,去年還能在1億美金,今年1億美金可能連邊都碰不到。
我想未來比較需要的還是微調(diào)的部分,而微調(diào)的部分,我還是建議去看林沐跟另外一個老師的課,他們很多paper講得非常不錯,
有個概念後會比較容易懂現(xiàn)況。
我想有做過LLM課題的人都會注意到 Training Compute-Optimal Large Language Models
下面這張圖
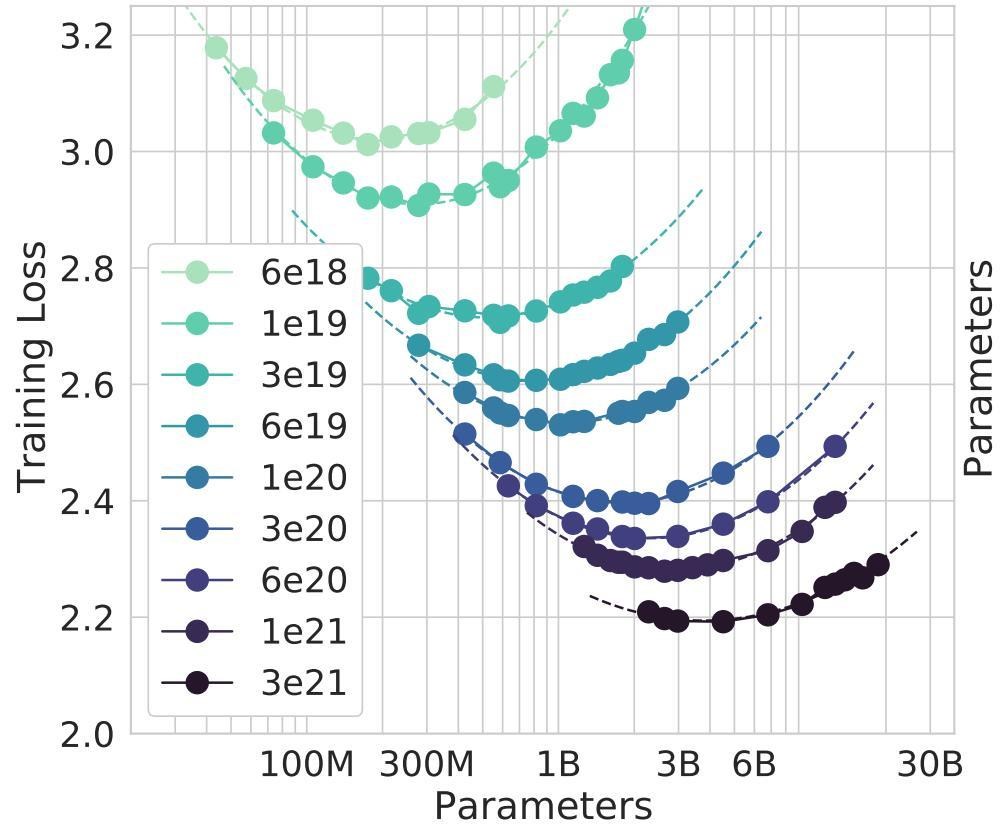
這張圖到底在說什麼呢?
其實這是張殘酷的微笑曲線,
也是去年到今年各路學(xué)者都想證明的一件事情,大力出奇蹟,
X軸是參數(shù),B是billion,所以30B=300億,而目前GPT-3是1750億,Google PaLM是5400億,你可以將它當(dāng)作人類神經(jīng)元多寡。
Y軸是training loss ,你會發(fā)現(xiàn)到中間時出現(xiàn)過擬合,越來越糟。
而臺灣很慘,多半訓(xùn)練做到6B就收手,也沒錢,正好在死亡谷這邊,
而圖中30B才開始有討論性,若依照GPT與LLaMA的文件來看,湧現(xiàn)的通常要超過60B,
但我想大多公司都沒辦法做到30B,
AI這東西分為邏輯推理跟訓(xùn)練,
訓(xùn)練又可分預(yù)訓(xùn)練與微調(diào),這個講不完,
不過你只要知道,
學(xué)習(xí)初期(預(yù)訓(xùn)練)非常難,後面累加知識(微調(diào))很簡單,
而應(yīng)用知識(推理)又相對學(xué)習(xí)簡單很多,
在你個人電腦跑6B甚至20B邏輯推理並不難,但要預(yù)訓(xùn)練,例如GPT-NeoX僅有20B就需要96張A100(約3000萬臺幣)連續(xù)運作三個月(電費另算),而且有時成敗也是三個月後才比較有定論,所以通常公司不會只有一套訓(xùn)練,而是多方案,所以這年代,你手中沒個1億美金,公司預(yù)訓(xùn)練必須找對沒人研究的項目,要不然別碰。
OK,如果你沒有預(yù)訓(xùn)練哪來的基礎(chǔ)模型,
很幸運這年代有一堆模型可以免費拿來用,
例如
GPT-J
GPT-NeoX
OPT
LLaMA
這些模型,其中最受關(guān)注的是LLaMA
他提供7B、13B、30B與65B
這幾個模型你玩過就會發(fā)現(xiàn),30B以下有很多真的都是人工智障,其中OPT非常明顯,有很多不如650M這種小模型,甚至他們只會鸚鵡學(xué)說話,但65B,突然的變得有智慧。
可玩的通常是外流模型
你可以去找
- LLaMA Dalai:因為LLaMA念起來跟喇嘛同音,所以他取名Dalai達賴,惡搞。Dalai這裡算是討論最完善,它裡面有記憶體與RAM大小關(guān)聯(lián),你可以玩到65B,3/24推出docker之後,Windows建議用Docker安裝,因為很多蠢問題都會解決,但若你是MacOS,而且是silicon晶片是最佳選擇,回答速度遠遠快於x86,我們成功讓65B流暢跑起來是在Mac Studio M1 Ultra,在I9 13900K上跑的表現(xiàn)很糟,後來也有試試Macbook air的M1,他也是跑得比I7 12700流暢不少。不過或許未來會改變,實際上如果不追求過高的要求,7B在很老的電腦都能跑,只是回答速度不快。
- alpaca.cpp:玩7B門檻很底,回答的表現(xiàn)也不錯,問程式也沒問題,但無法回答中文。
- text-generation-webui:他跟stable diffusion Automate1111提供的webUI一樣,都是用gradio建立的,因此穩(wěn)定性與表現(xiàn)都不錯,不過要小心,他似乎有病毒,然而他能玩的模型就多很多,介面也比較友善,也能用GPU加速,是個不錯的入手項目,另外即便他聲明可以用LLaMA,但我無法真的使用LLaMA。
另外目前外流的這些模型,看起來似乎類似又不太類似,
因為中間參數(shù)落差不小,
無論如何,你必須承認(rèn)他們進步都很快速。
而我前面有提到微調(diào)部分,
這些模型的微調(diào)討論真的很多,
我想如果你玩過Stable Diffusion,應(yīng)該會知道最近有個很紅的東西叫做RoLA,他僅需很少的VRAM就能訓(xùn)練新圖片,單卡即可完成,
他背後真正的神推手是Hugginface的PEFT
若有興趣可以去碰碰
有了這東西之後,真的一堆模型要在家中玩都變得很容易
新鮮的時代來臨
也太快了
總覺得一天24hr都不夠用
不知道有沒有人開發(fā)過私人伺服器,以前大學(xué)時候跟朋友玩過,
我記得當(dāng)時我在伺服器中就看到當(dāng)年遊戲AI寫法,
就是Elisa那種設(shè)計方式,一堆IF ELSE,
寫到吐血,
當(dāng)時的AI笨到不行,即便後來能玩到的smart child也明顯智障,
直到三年前我看公司為了引入銀行的一些服務(wù)機器人,著手參與chatBOT,那時參與競標(biāo)的公司還不少,
貴得要死,還是一堆人工智障,
現(xiàn)在我看問文跟一堆文獻,我都開始理解一般公司鬼打牆之後的絕望是什麼,
真的不能責(zé)怪,就沒錢啊。
只希望政府200億,多投對地方,集中在某個技術(shù)上來引領(lǐng)其他公司,
要不然未來臺灣AI只能作微調(diào),雖然也不是壞事,若以爆肝代工而論。

























