主題
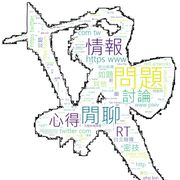
這是利用上篇爬蟲(chóng)程式所爬到的資料製作的
基本上效果不是很好
但是我只是臨時(shí)在網(wǎng)路上找教學(xué)套用ㄉ
如果有高手請(qǐng)不吝指教,感謝
| from wordcloud import WordCloud,ImageColorGenerator import numpy as np import matplotlib.pyplot as plt from PIL import Image import jieba import jieba.analyse from collections import Counter # 次數(shù)統(tǒng)計(jì) from scipy.ndimage import gaussian_gradient_magnitude from os import path # get data directory (using getcwd() is needed to support running example in generated IPython notebook) d = path.dirname(__file__) if "__file__" in locals() else os.getcwd() dictfile = d + "/dict.txt" # 字典檔 stopfile = d +"/stopwords.txt" # stopwords fontpath = d +"/msjhl.ttc" # 字型檔 mdfile = d +"/text.txt" # 文檔 pngfile = d +"/k2.jpg" # 剛才下載存的底圖 mask = np.array(Image.open(pngfile)) jieba.set_dictionary(dictfile) jieba.analyse.set_stop_words(stopfile) text = open(mdfile,"r",encoding="utf-8").read() tags = jieba.analyse.extract_tags(text) #獲取句子語(yǔ)意標(biāo)籤 seg_list = jieba.lcut(text, cut_all=False, HMM=False)#開(kāi)始進(jìn)行分詞 #去除 del_list = ["情報(bào)","問(wèn)題","討論","閒聊","心得","https","新聞","ww","com"] for word in del_list: jieba.del_word(word) dictionary = Counter(seg_list) freq = {} for ele in dictionary: if ele in tags: freq[ele] = dictionary[ele] print(freq) # 計(jì)算出現(xiàn)的次數(shù) #設(shè)定文字雲(yún)參數(shù) wc = WordCloud(background_color="white", mask= mask, stopwords=stopfile, contour_width=3, font_path= fontpath).generate_from_frequencies(freq) # generate word cloud wc.generate(text) # create coloring from image image_colors_default = ImageColorGenerator(mask) plt.figure() # recolor wordcloud and show plt.imshow(wc, interpolation="bilinear") plt.axis("off") plt.show() |
這是輸出的圖片