在 coding 這件事情上,從資管出身的我一直以來沒怎麼受過關於底層概念的正式課程,最近總算有機會接觸到這類問題,也藉此弄懂了幾個基本觀念。
在解決問題的過程當中,也發現了從網路上根本沒辦法找到的完美解法,所以就用這篇文來記錄一下弄了整晚才搞定的坑吧,對於想用 Golang 開發卻苦於 GUI 庫又肥又麻煩的朋友來說,應該會是不錯的素材。
? 目標
1. 用 Golang 寫一個可以把兩個字串拼接起來的函式
2. 把這個函式編譯成 DLL 動態連結庫
3. 用 C# 寫一個 WinForm Application 並引用這個 DLL 檔案
4. 從 C# 傳入兩個包含中文的字串到 DLL 檔案裡面,再把結果取回來
? 開工前的準備
首先我們需要有能夠處理 C 語言的 gcc 編譯器,所以我們得在這之前先安裝 MinGW。
安裝的版本決定了你編譯出來的 DLL 架構。我們進去往下拉可以看到諸如 8.1.0、7.3.0、6.4.0 等等各種不同版本,一般來說從裡面挑最新的就可以了。決定好版本之後,你會發現每個版本底下又各自有不同的分支,這個時候我們就必須按照需求來決定我們應該下載哪一種版本。
在各版本底下的分支,可以看到指令集分成 x86_64 跟 i686。以現在大部分的家用電腦來說,優先選擇 x86_64(amd64)就行了,通常不會有太大問題。
接下來又分成 posix 和 win32,這個我 Google 查到的結果說是對於執行緒的方式有所不同,posix 支援 C++11 的多執行緒,win32 版本則沒有。因為我自己擔心編譯的時候遇到什麼奇怪的問題,所以我安裝 MinGW 的時候偏好選擇 posix 版本。
最後一項又分成 sjlj(這是三小名字?)、seh、dwarf 三種類型。這些版本分支的差異如下:
sjlj:支援 32 位、64 位;支援結構化異常處理;執行效率稍微慢一點點
seh:支援 64 位(註)
dwarf:支援 32 位
所以像我這種一般的 Windows 使用者,就選擇了 x86_64-posix-sjlj 版本。
註:我查資料有一些人說 seh 也支援 32 位,但我自己嘗試用 seh 版本編譯 32 位 DLL 的時候遇到很多問題,所以我自己是偏好使用 sjlj 版本。
把 MinGW 的環境包載下來之後,我們把它解壓,安放到一個喜歡的位置(像我是直接放在 C:\),接著把它底下的 bin 資料夾加到環境變數的 path 裡面(環境變數的設定方法可以參考這篇):
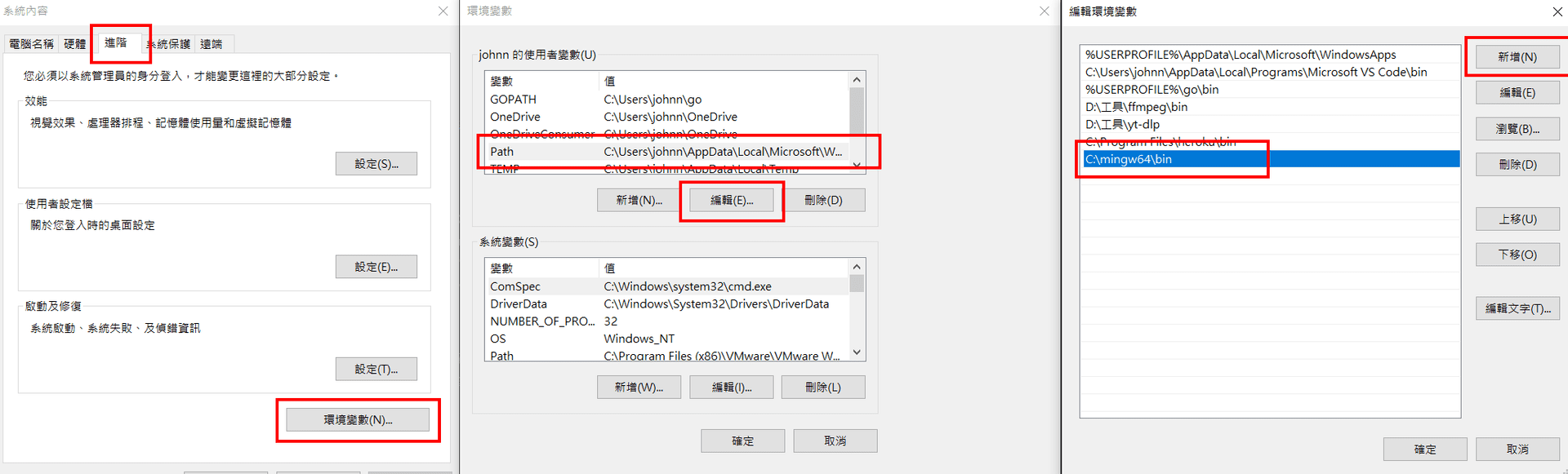
確定所設的路徑下有 gcc 等等編譯環境的必備工具:
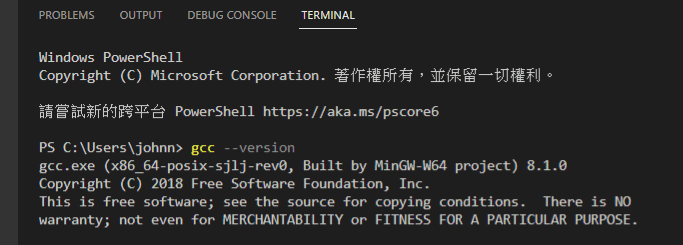
儲存好之後重新啟動 VS code,用 [Ctrl] + [~] 打開 terminal,輸入 gcc --version,你應該會看到 gcc 編譯器提供的版本資訊:
到這步,你就完成 MinGW 環境的安裝了。
? 用 Golang 開發 DLL 檔案
由於 C 語言的運作機制相對來說沒有其他語言那麼複雜,它本身已經成為大家通用的底層標準。
相較之下,Golang 作為一個複雜的高階語言,它並不像 C 語言一樣原生支援直接把原始碼編譯成 DLL 檔案的功能。為了提高 Golang 的通用性,它本身自帶了一個官方的函式庫叫做「C」,讓我們可以把 Golang 開發的功能用符合 C 語言規範的介面,提供給其他語言使用。
用白話來講,我們可以把 Golang 和 C 兩種語言嵌合,既能保留 Golang 語言本身的優點,又能用 C 語言的規範來對外溝通,這樣的技術就是所謂的 CGO。
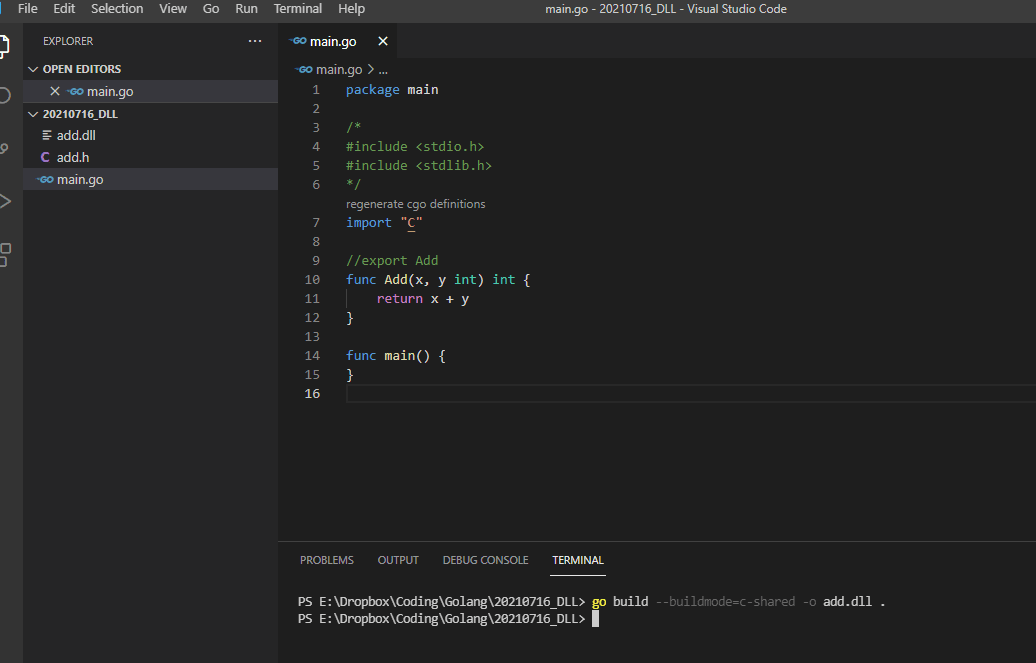
假設我們想寫一個函式 Add(x, y) = x+y,那麼就把函數寫出來,使用 Golang 的 C 函式庫,再到函式定義的上一行加上 export 標籤,以設立之後編譯成 DLL 所需要的 entry point:
注意,由於它是要開放給外部使用的,屬於 exported(向外輸出)類型,所以按照 Golang 的命名規範,函式的名稱開頭必須是大寫,這也是為什麼取作 Add 而不是 add。
CGO 的用法就是把 C 語言的部分寫在 Golang 原始碼的註解上面,綠字部分雖然平常是註解,但使用 CGO 的時候它就變得有意義了,會在編譯時一起被讀進去。我們 import 了 C 函式庫,也在 C 語言的部分引入了 C 語言基本常用的 stdio.h 和 stdlib.h。
在編譯之前,我們要先指定編譯的 DLL 檔案應該要是 32 位或 64 位(32 位的 DLL 可以被 32 位或 64 位的作業系統執行,而 64 位的 DLL 只能被 64 位的作業系統執行)。
假如是 32 位的話,執行:
go env -w GOARCH=386
假如是 64 位的話,執行:
go env -w GOARCH=amd64
決定好 32 位或 64 位之後,我們使用命令把它編譯成 DLL 檔案:
go build --buildmode=c-shared -o add.dll .
當然如果你後面要改成「-o add.dll main.go」的話也是可以的,反正在這個範例裡面也只有一個 main.go。如果只有一個半形的句點,代表的是整個資料夾的程式碼一起編譯進去,這跟平常使用的「go build .」是類似的概念。
如此一來,用 Golang 開發的 DLL 檔案就出爐了。
? 把 DLL 檔案引入 C# 開發的程式裡
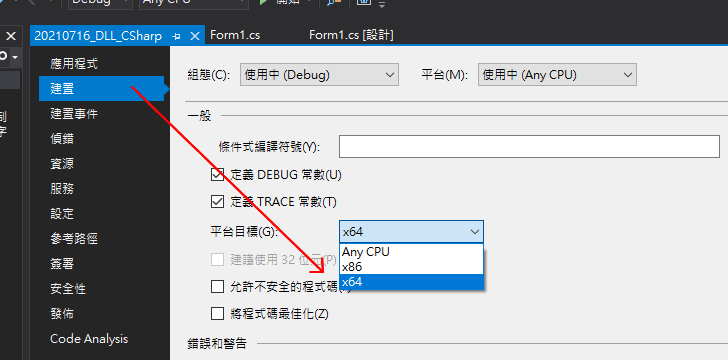
得到 DLL 檔案以後,我們就可以拿到 C# 開發的程式上面測試了。首先把從 C# 新開的專案從方案總管右鍵 > 屬性,把專案的平臺目標調成 x64 限定(如果你的 Golang 編譯環境是 32 位元,就選 x86):

首先引用 System.Runtime.InteropServices,讓程式有能力用 DllImport 語法把外部的 DLL 檔案引用進來。
接著使用:
[DllImport("add.dll", EntryPoint = "Add")]
public extern static int Add(int x, int y);
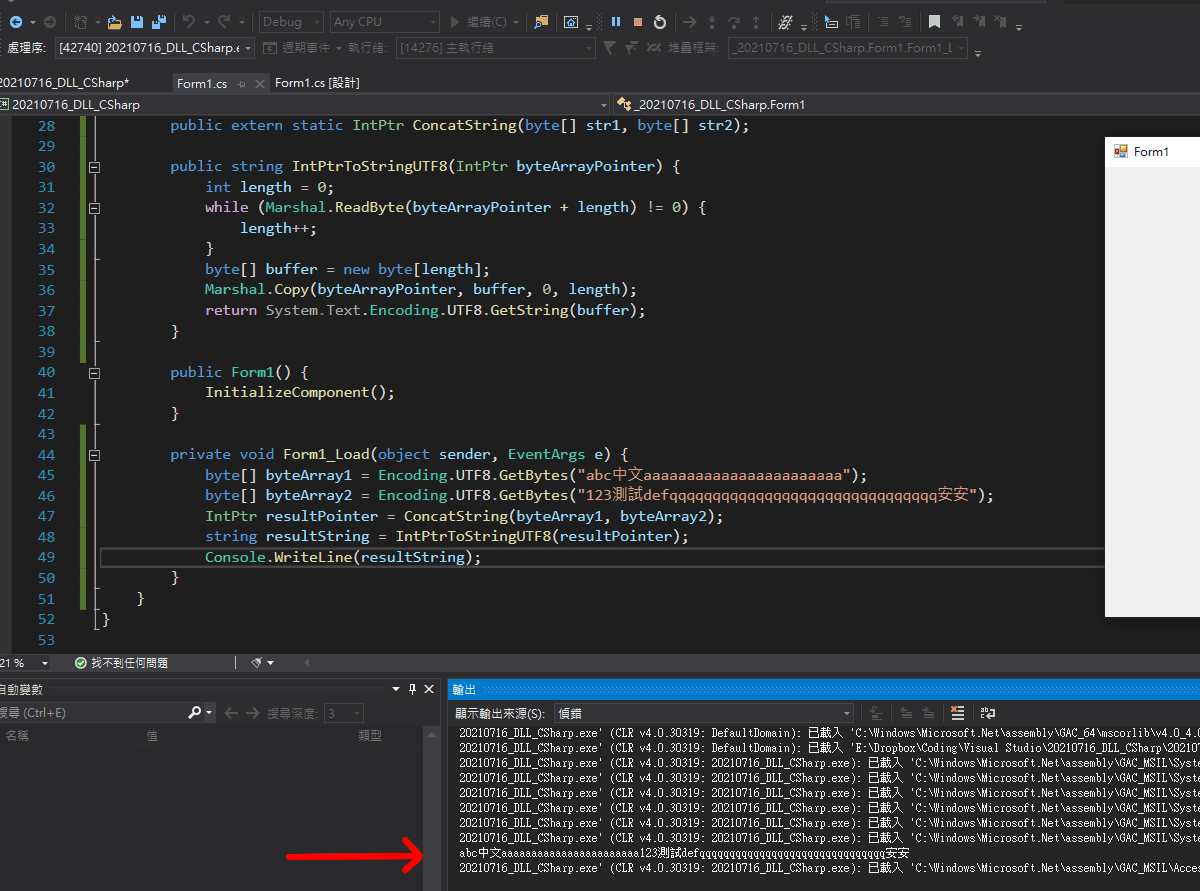
這樣子,我們就可以讓 C# 寫的程式載入 DLL 檔案,成為可以直接拿來引用的函數了。隨便綁一個 Form1 的 Load 事件進去,編譯起來跑看看:
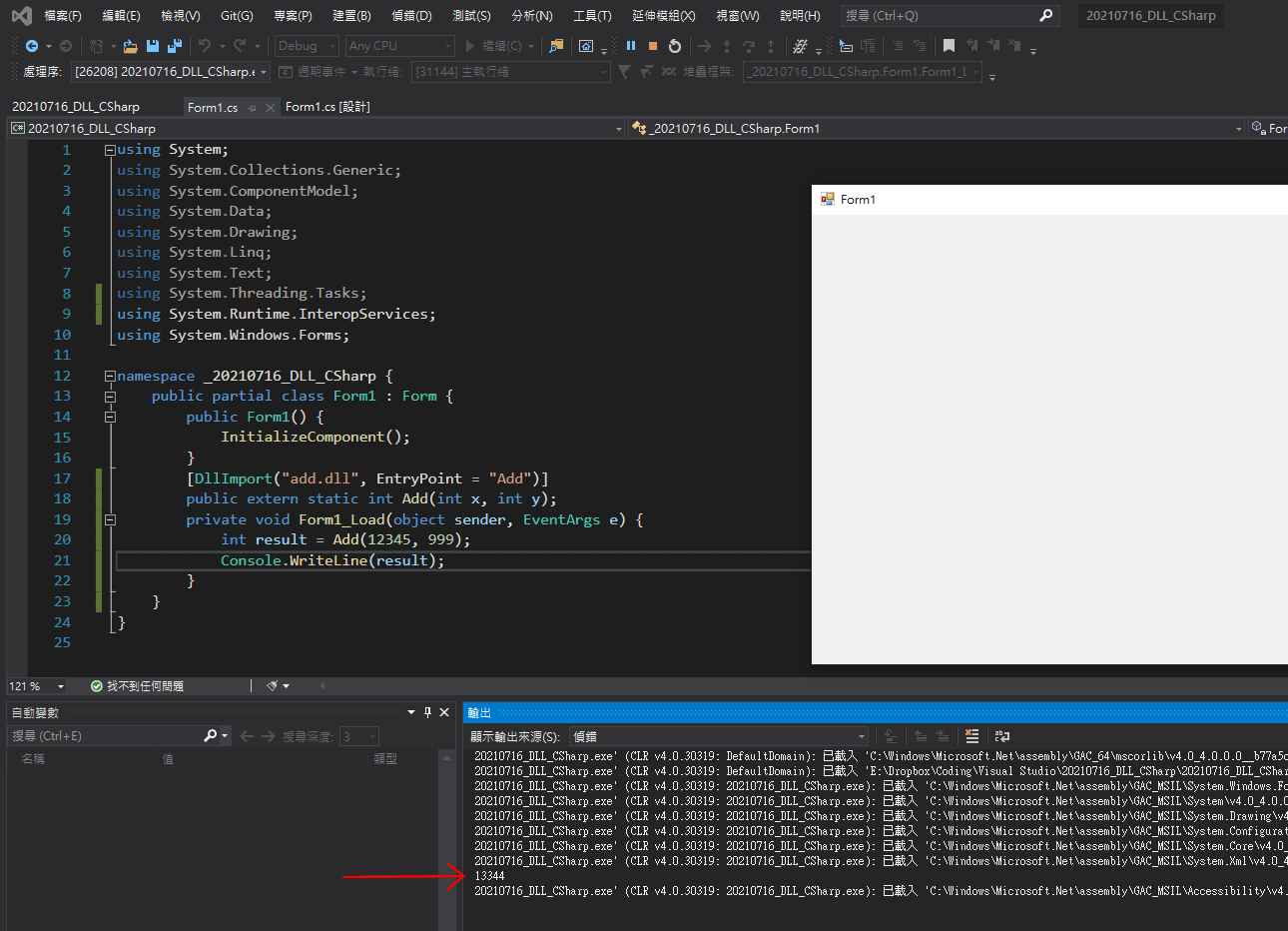
成功!
? 在不同語言之間傳遞字串
講到這裡,問題就會開始多起來了,可能有些地方看起來有些拗口,建議先確保自己精神狀態好再繼續看下去。
近代的高階語言為了提供更多的功能,通常 string 型態不會只是單純由 char 組成的 array。不同語言間對於 string 型態的定義、實作細節都不太一樣,這意味著 C# 的 string 和 Golang 的 string 結構不同,自然就沒辦法直接當成相同的資料類型來互相傳遞。
所以我們在 Golang 這端不能用 Golang 的 string 型態來接收 C# 的 string,而是應該兩邊各退一步,統一規定傳遞以 byte 為單位的 array。
這裡又牽涉到一個問題了:怎樣的型態才是以 byte 為單位的 array?
既然 C 語言在這裡扮演 C# 和 Golang 的橋樑,我們當然必須以 C 語言的型態為主。就好像如果有一個西班牙人和一個法國人都會英文的話,那麼兩個人應該要用英文來溝通,一樣的道理。
C 語言裡面最接近字串的型態就是 char array 了。在 C 語言裡,一個 char 佔用 8 bits(也就是一個 byte)的大小,寬度都是固定的。而本質上,傳遞一個 array 的同時就相當於傳遞一個指標位址,所以我們在 Golang 一端,應該要用 *C.char 作為接收和傳遞用的型態:
func ConcatString(str1, str2 *C.char) *C.char {
// ...
}
接著我們遇上了一個新的問題:C# 同時提供了 char[]、byte[] 兩種資料型態,傳入 DLL 時應該要選哪個才正確呢?
這兩個型態看起來很像,但其實 C# 的 char[] 是以字元為單位,可能有些文字佔用 8 bits、有些文字佔用 16 bits,這些內容並不是等寬的。至於 byte[] 資料型態,顧名思義就是以 byte 為單位,顯然 C# 的 byte array 比較接近 C 語言的 char array。
接下來,我們事先預想到了 Golang 一端會傳送一個 C 的 char array 回來。既然 Golang 一端是用 *C.char 這樣的指標變數來接收地址,那麼當 Golang 一端傳回一個 C.char array 的時候,我們在 C# 這邊也應該用指標的型態 IntPtr 來接收從 Golang 傳過來的 C.char array:
[DllImport("add.dll", EntryPoint = "ConcatString")]
public extern static IntPtr ConcatString(byte[] str1, byte[] str2);
到這裡,我們基本上確立了兩邊的介面應該如何定義。
? 轉換字串
接下來的問題就是兩邊如何各自處理字串了。
在 Golang 裡面,處理字串時預設使用的是 UTF-8 編碼,所以我們在 C# 一端應該要把字串轉換成由 UTF-8 編碼而成的 byte array,才接著傳進 DLL 裡面:
byte[] byteArray1 = Encoding.UTF8.GetBytes("abc中文");
byte[] byteArray2 = Encoding.UTF8.GetBytes("123測試def");
IntPtr resultPointer = ConcatString(byteArray1, byteArray2);
我們最後會得到一個 IntPtr,如何處理這個指標則待會再說。我們把兩個字串傳到 Golang 一端以後,可以使用 Golang 的 C 函式庫提供的 GoString 函式,把一個 *C.char 轉換成 Golang 的 string 型態。
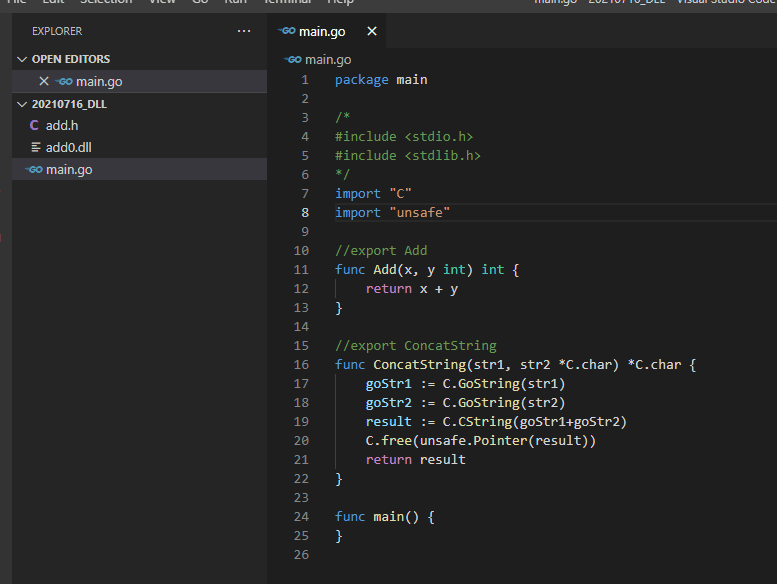
反之,我們要想把一個 Golang 的 string 轉換成 *C.char,可以使用 C.CString:
//export ConcatString
func ConcatString(str1, str2 *C.char) *C.char {
goStr1 := C.GoString(str1)
goStr2 := C.GoString(str2)
return C.CString(goStr1+goStr2)
}
這樣就可以用 Golang 的方式把兩個字串連接起來,再轉成 C string(C char array)傳回去。
在 C# 一端得到一個 IntPtr 之後,接著要煩惱的問題就是:「如何從得到的 IntPtr 位置讀出字串來?」這個問題我本來 Google 查過,人家的建議是:
string resultString = Marshal.PtrToStringAnsi(resultPointer);
不過這接著會有一個問題,Marshal 函式庫只有給 Unicode、ANSI 等解析方式,並沒有提供 PtrToStringUtf8 這樣的方法(注意:Unicode 跟 UTF-8 不同)
所以上述這個方式對於純英數字串確實是絕對沒有問題的,畢竟半形的英文數字無論在哪個編碼裡面都一樣,但只要遇上了中文、日文等 ASCII 無法表現的文字,就會變成亂碼:
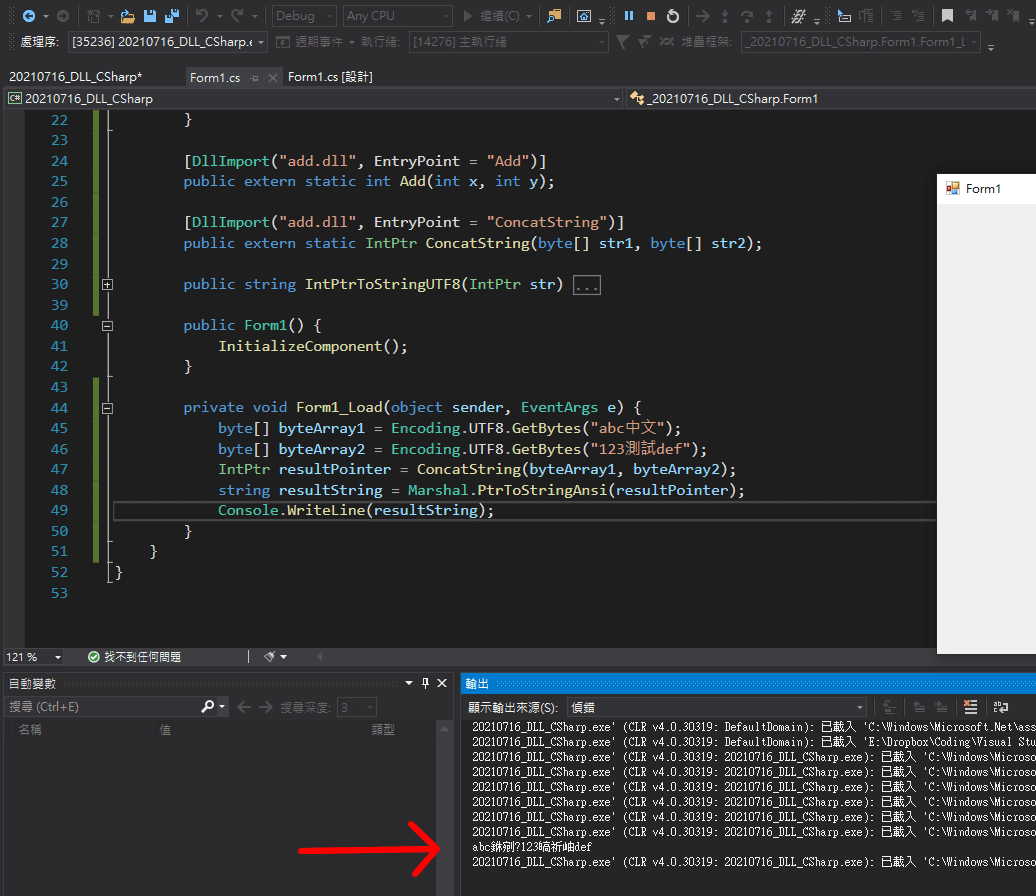
幸好 C# 的 Encoding 函式庫還是有提供把 byte array 用 UTF-8 轉換成 string 的函式——因此,我們需要想辦法從 IntPtr 記錄的位址開始逐個 byte 讀取,組成一個 byte array,然後再用 UTF-8 的編碼把這個 byte array 轉換成 string:
public string IntPtrToStringUTF8(IntPtr byteArrayPointer) {
int length = 0;
while (Marshal.ReadByte(byteArrayPointer + length) != 0) {
length++;
}
byte[] buffer = new byte[length];
Marshal.Copy(byteArrayPointer, buffer, 0, length);
return System.Text.Encoding.UTF8.GetString(buffer);
}
我們知道字串通常不會穿插空字元 0x00 在中間,所以當我們讀到 0x00 的時候就知道這個字串已經讀到底了,藉此就能首先得到字串的長度,再直接把「該位址算起,按照字串的長度」得到的資料內容複製一份到新的 byte array 裡面,就可以把這個新的 byte array 用 UTF-8 的方式轉換回 C# 的 string:
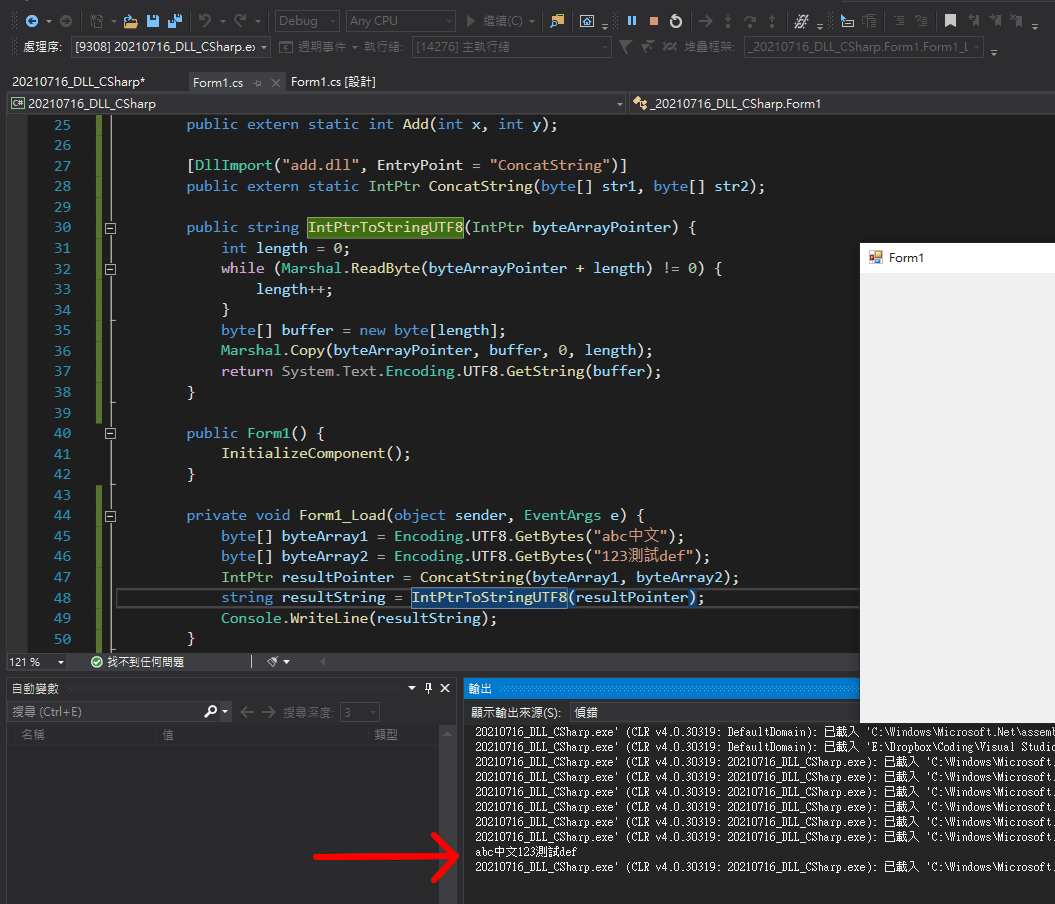
大功告成。有了這些背景知識,我們就可以在 C# 和 Golang 寫成的 DLL 之間任意傳遞字串,而且還能避免亂碼的問題。如果不想踩更多關於指標的坑,我們還可以統一把資料轉成 JSON 格式的字串再互傳,這樣就可以應付很多不同的狀況了。
? 記憶體流失(Memory Leak)
接下來才正式涉及到記憶體「管理」的層面。
電腦程式使用記憶體來存放變數,一般分為兩種類型,一種是 heap、另外一種是 stack。真要把兩種的差別細說起來一時半刻講不完,但在 C 語言裡,我們可以粗略地把 heap 理解成「由程式設計師手動申請和釋放的記憶體空間」,而 stack 則是「在它所在的函式結束後會自動釋放的記憶體空間」,例如我們直接在函式裡宣告的一般變數。
通常像 Golang、Python 等等的近代高階語言,都具備 GC(Garbage Collectiion)的功能,會自動釋放那些很可能不會再用到的記憶體空間,讓那些記憶體空間得以重複使用而不會一直處在佔用狀態。
然而 C 語言作為一個相對純淨、底層的語言,它是沒有原生提供 GC 功能的。當我們使用 C 語言的 malloc 函數,在 C 的 heap 上面申請記憶體空間,就應該要在使用完畢後找個合適的時機,利用 free 函數把該空間釋放出來。
倘若我們沒有好好地讓這些記憶體空間「善終」,也許是忘記了、也許是邏輯不夠嚴謹而沒保證讓它釋放,那塊記憶體空間就會一直佔用在那裡(即便它不再有人使用),這樣的情況只要多了,你就會發現你的程式佔用了超大量的電腦記憶體,這也就連帶造成了程式會隨著運作時間而越來越胖,沒辦法穩定在電腦上長久運作。
這樣的現象,就稱為記憶體流失(Memory Leak)。
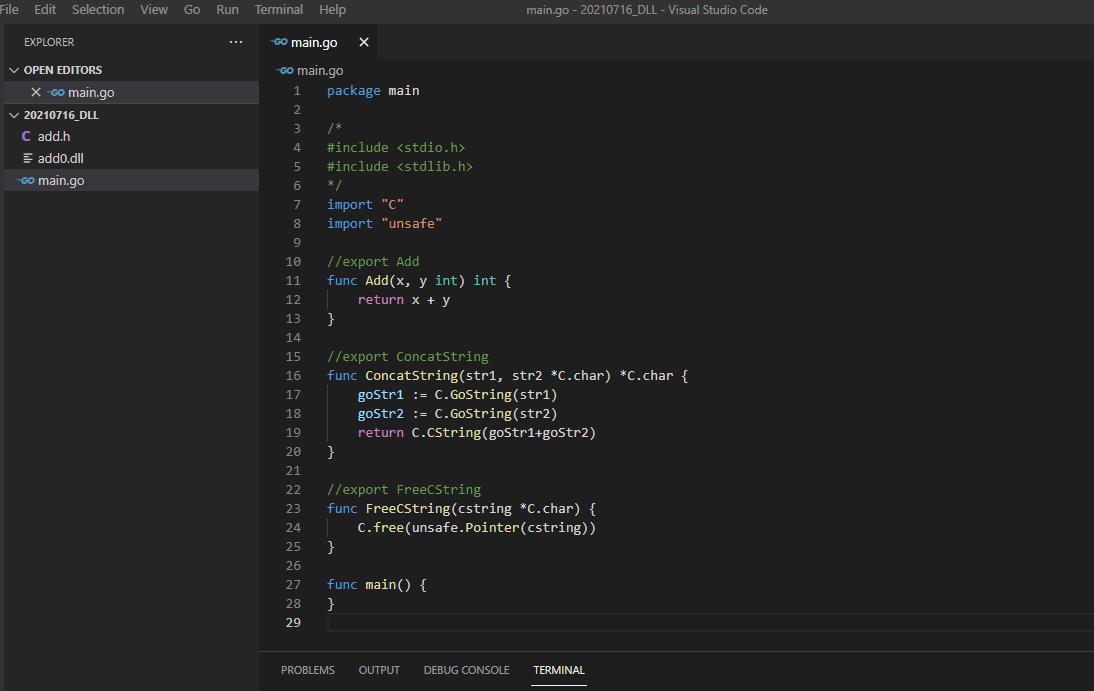
當我們使用 C.CString 把一個 Golang 的 string 轉換成 C 的 string 時,實際上這個函式是用 malloc 函數來實作,過程中在 C 語言部分的 heap 上面申請了一塊記憶體空間。所以如果我們在 CGO 裡面用 C.CString 產生了一個 C 的 string:
func f() {
a := C.CString("abcdefg")
}
這個變數 a 即使在函式結束以後,它仍然會存在 C 的 heap 上面,而不會像 stack 上面的變數一樣自動被釋放。所以,我們應該要在 CGO 上面使用 C.free 函式,在變數 a 不用之後把它釋放掉:
func f() {
a := C.CString("abcdefg")
C.free(unsafe.Pointer(a))
}
在 free 之後,那塊記憶體空間就是自由的了,可以被重新分配利用。
? 回傳 CString 的狀況下該如何釋放空間
問題來了!在這次的例子裡,我們希望在 Golang 一端處理完字串,然後回傳一個 C string 到 C# 這端,回傳之後這個函式就執行完而結束了,我們勢必沒有好的時機在這個函式裡面把這塊空間釋放掉。
如果在回傳結果之前,就提前釋放掉這塊記憶體,那麼這塊記憶體空間就會變成自由狀態。基於殘值的原理,我們還是有可能會得到正確的結果:
但在你釋放了記憶體空間之後,這塊記憶體空間就隨時都可以被其他的程式拿去用。你如何保證在 C# 一端接收並讀取完資料之前,這塊記憶體空間的內容不會被佔用、修改呢?
所以,我們可以另外獨立出一個專門用來釋放記憶體空間的函式,在 C# 一端確認已經讀取完字串之後,再把指標傳回去由 CGO 釋放它:
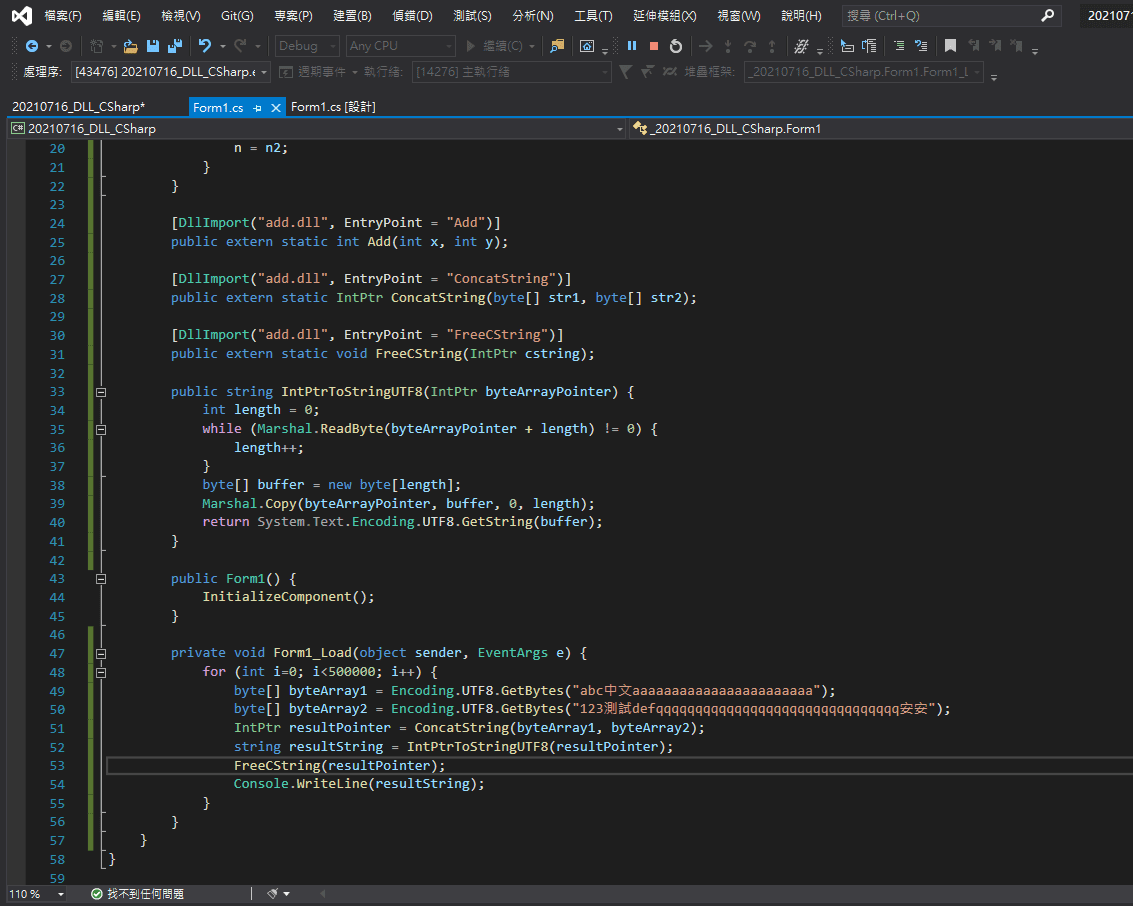
實驗一下:分成兩種方式各執行 50 萬次,一種正常執行 FreeCString 函式,另一種完全不去執行 FreeCString。用工作管理員比較看看兩者的記憶體佔用量,我這邊測試出來的數據分別是 17.6 MB 和 63.6 MB,可以感受得到剛才定義的 FreeCString 有正確地釋放記憶體空間。
至此,基本上就解決了 C# 和 CGO 之間的型態問題、編碼問題、記憶體流失問題。
? 如果從 DLL 直接回傳 GoString
本文前面所談到的方法都是相對合理、步驟比較少的最佳解,像是統一轉換成 C# byte array(C char array)之後互傳,採取這樣的策略都有現成的簡單方法可以互相轉換,也保證能夠在 UTF-8 的編碼下運作。
但這也不代表傳入其他類型就絕對無可能。例如,我們可以在 C# 一端定義 GoString 型態:
public struct GoString {
public IntPtr p;
public int n;
public GoString(IntPtr n1, int n2) {
p = n1;
n = n2;
}
}
用 C# 一端自行定義的 GoString 資料型態,接收從 DLL 傳回來的 Golang string,仍然可以成功。只是,在 DLL 裡面產生的 Golang string 畢竟是由 Golang 申請的記憶體空間,這個型態的結構本身包含了由 Golang 產生(並管理)的指標,CGO 預設是不能把這樣的指標傳出來的,這麼做的話執行的時候會告訴你「cgo result has Go pointer」,除非你在 C# 一端把 cgocheck 的環境變數從預設的 1 改為 0:
// cgocheck 參數可以是 0~2,其中 2 最為嚴格
Environment.SetEnvironmentVariable("GODEBUG", "cgocheck=0");
但即使把它強制設為 0、繞過安全檢查機制而成功避免程式被終止,你仍然沒辦法保證這個字串的記憶體空間會不會在什麼時候被 Golang 的 GC 機制回收,所以到頭來還是用前面所提到轉為 CString 的方法最保險,至少我們都能清楚地掌握這個變數空間的流向,也就比較不容易產生資料意外損毀的問題。
掌握這些細節之後,我們就可以用 C# 開發 GUI、用 Golang 開發核心功能,兩種語言各自的優點也就能同時拿來利用了。