因緣際會下, 意外地發現
fmodf()還有最佳化的餘地
這個還有fmod(), fmodl()等等變種, 主要就是去取小數點相除的餘數
計算方式很單純:
V1 % V2 = V1 - V2 * truncate(V1 / V2)
truncate就是去把小數部分去掉
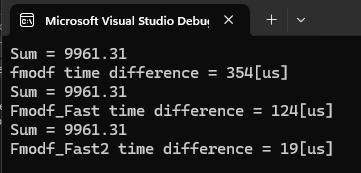
但實測之後, fmodf就是會多花點時間, 以下是三種實作方法的比較時間
而且這是在Release build下測試的, 也就是說程式最佳化基本上已經有了 (/O2)
另外還把Floating Point Model設定為快速 (/fp:fast)
從0.354ms -> 0.124ms ->0.019ms, 到底經歷了什麼?
fmodf方法:
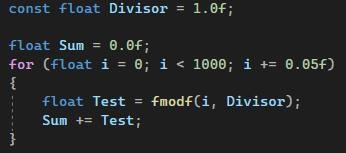
測試很單純, 簡單寫個迴圈去加總 <i除以*Dividend的餘數>
*被除數應該叫Dividend, 截圖時才發現打錯了
而Fmodf_Fast, Fmodf_Fast2是自己寫的另外兩個小函式:
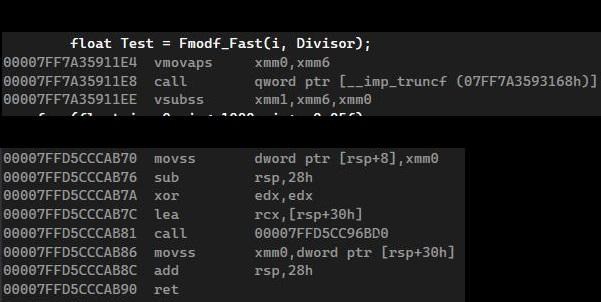
Fmodf_Fast就是去算公式, 用了另一個內建函式
truncf(), 與fmodf相比耗時直接砍半
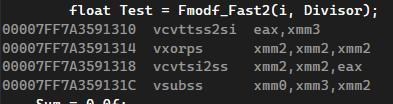
Fmodf_Fast2則是再加以利用SSE指令集, 先透過_mm_load_ss轉換為__m128
再用_mm_cvtt_ss2si轉換為整數, 最後cast成float回傳, 又比前一個方法快十倍
不過造成這種差異的主因到底是什麼?
難道fmodf()做了預料之外的事? 還真的是
先看一下兩個自製函式的彙編指令:
不意外SSE版本的指令是最少的, 內建的truncf稍微多了一點
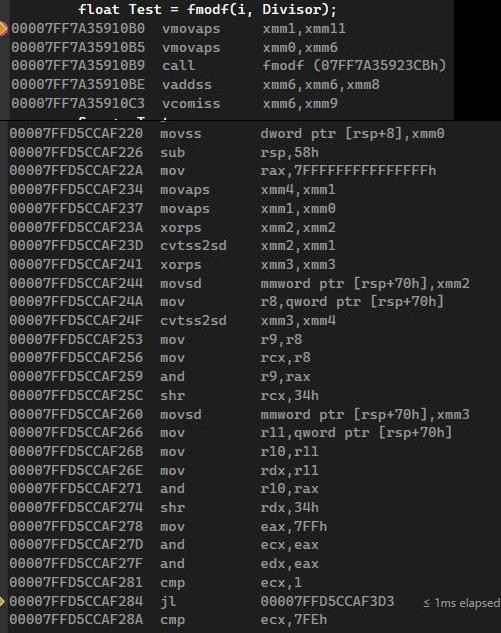
最後則是fmodf的彙編指令:
果然很多指令! 從裡面很多jl與cmp指令來判斷, 主要應該是在做錯誤處理的部分
不過不能怪它, 畢竟它要做為一個標準函式庫的內容, 這些檢查是必須的
------------------------------------------------------------------------------------------
大概就分享到這~
實際上如果被除數不是這麼好看的數字, 自製函式跟fmodf的輸出結果會有一點不同
如果應用程式不需要很精確的浮點數餘數, 並且以速度為主的話 (例如遊戲開發)
那麼自己去做fmodf還是挺值得的
至於沒有0或NaN的檢查也不是大問題
在呼叫餘數計算之前就應該要處理好或者直接避免這種情況出現
 創作內容
創作內容






 工作 (53)
工作 (53)