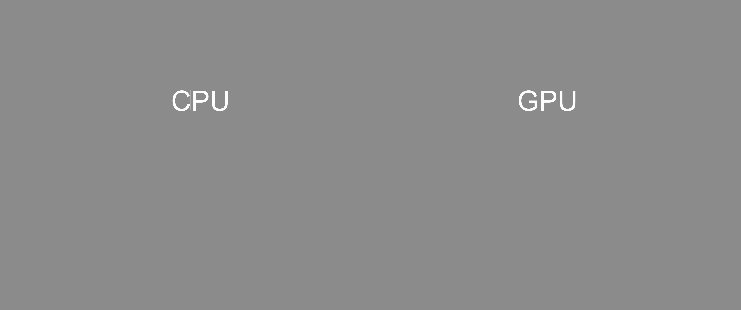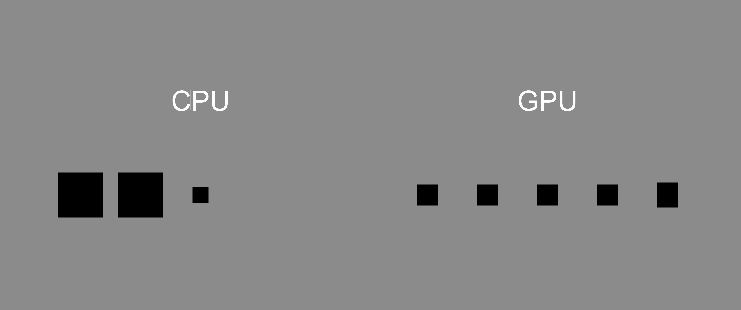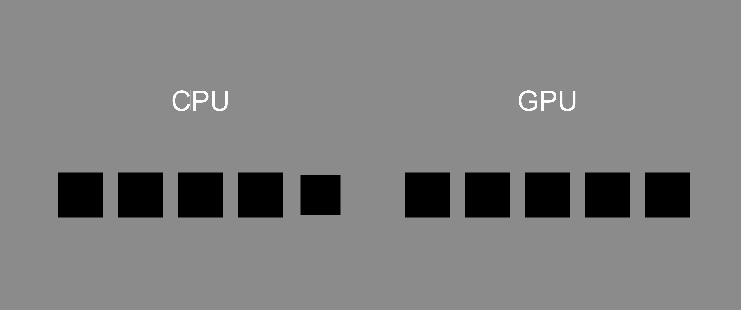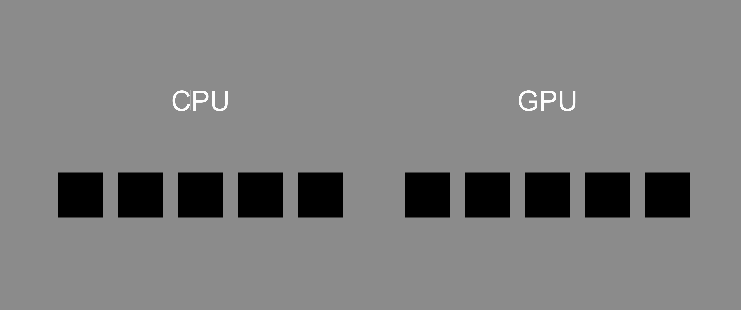文章搬運(yùn)自個(gè)人網(wǎng)站,如果有發(fā)生圖片遺失或錯(cuò)誤的話再告訴我
原文連結(jié)
點(diǎn)我,會(huì)有更好讀的排版,文長(zhǎng)注意歐 :P
概括
計(jì)算著色器 (Compute Shader) 是一種獨(dú)立於渲染管線之外,用途也不僅限於著色計(jì)算的工具,意圖利用 GPU 擁有大量核心的優(yōu)勢(shì),以平行運(yùn)算的方法解決問題。這篇文章是我在研究一段時(shí)間後總結(jié)出的各項(xiàng)初學(xué)重點(diǎn),在這裡分享給各位。
請(qǐng)注意,因?yàn)橛?jì)算著色器已經(jīng)屬於進(jìn)階應(yīng)用,所以文章將會(huì)省略基礎(chǔ)的著色器知識(shí),將重點(diǎn)放在「對(duì)圖學(xué)與著色器有一定程度理解,但還不知道如何接觸計(jì)算著色器」的角度進(jìn)行編寫。
本文的內(nèi)容一共用到兩種程式語言,由 CPU 運(yùn)作的 C# (CSharp),以及由 GPU 運(yùn)作的 HLSL (High Level Shader Language),閱讀程式時(shí)還請(qǐng)注意程式區(qū)塊的標(biāo)題。文章範(fàn)例使用的環(huán)境為 Unity 引擎,雖然著色器相關(guān)的內(nèi)容大致是通用的,但實(shí)做時(shí)也請(qǐng)注意是否有環(huán)境差異的問題在。
那麼,正式開始前請(qǐng)先讓我介紹一下計(jì)算著色器的兩大重點(diǎn):
並行運(yùn)算
首先,假設(shè)我們想重複執(zhí)行某項(xiàng)函式 10 次,在常規(guī)的 CPU 語言中可能會(huì)透過迴圈執(zhí)行,根據(jù)給定的條件(如計(jì)數(shù)器)重複執(zhí)行任務(wù)。以現(xiàn)在的例子便是根據(jù)執(zhí)行次數(shù) i,由 0 開始直到執(zhí)行完第 9 次後結(jié)束,且由於 CPU 語言是線性執(zhí)行的,因此只有在當(dāng)前迴圈的內(nèi)容被執(zhí)行完畢後,才會(huì)進(jìn)入下一次的迴圈。
但是在著色器這種 GPU 語言中,函式則會(huì)交由十個(gè)獨(dú)立的執(zhí)行緒 (thread) 進(jìn)行運(yùn)算,讓 GPU 的大量核心以平行的方式完成任務(wù),執(zhí)行時(shí)並無順序之分(亂序)。
這裡用一張簡(jiǎn)單的示意圖展示運(yùn)作差異。注意,這張圖只是表示兩者「運(yùn)作方式的差異」,與處理效率無關(guān)。
不過,在計(jì)算著色器中,運(yùn)作差異並不是真正的難點(diǎn),對(duì)有編寫過材質(zhì)著色器的人來說應(yīng)該已經(jīng)很熟悉並行這回事了。計(jì)算著色器與材質(zhì)著色器的真正差異在於,計(jì)算著色器是獨(dú)立於渲染管線之外的系統(tǒng),所以它也沒有頂點(diǎn)著色器 (vertices shader) 或片段著色器 (fragment shader) 這種渲染管線提供的「框架」來提示使用者該做些什麼。
因此計(jì)算著色器的真正的難點(diǎn)是,在少了明確的目標(biāo)指引以後我們只能靠自己判斷有什麼問題是能透過並行解決的,以及該怎麼透過並行解決問題。對(duì)初次接觸計(jì)算著色器的人來說,就可能因?yàn)椴皇煜K行的思考方式而停頓。
資料傳遞
在常規(guī)的渲染著色器中,引擎管線會(huì)幫使用者處理完各種瑣碎的工作。但在計(jì)算著色器中,使用者擁有更大的權(quán)力指揮 GPU 幫助我們達(dá)成各種任務(wù),因此相應(yīng)的責(zé)任也產(chǎn)生了,我們必須接手一些原本會(huì)由渲染管線完成的工作:資料傳遞 。
CPU 與 GPU 運(yùn)作時(shí)使用的儲(chǔ)存空間不同,因此想執(zhí)行任何的操作前也必須先將資料傳遞給 GPU。由於資料是在兩種不同環(huán)境中進(jìn)行傳遞,資料從哪裡來、資料到哪裡去,該傳遞什麼資料以及該怎麼傳遞資料都是實(shí)做時(shí)需要面對(duì)的問題。
再加上著色器本身的除錯(cuò)難度,計(jì)算著色器出錯(cuò)時(shí)會(huì)讓使用者難以辨識(shí)究竟是資料傳遞出錯(cuò)還是計(jì)算函式有誤。對(duì)於初次接觸計(jì)算著色器,還不熟悉除錯(cuò)方法的新手來說也會(huì)是一大學(xué)習(xí)瓶頸。
腳本結(jié)構(gòu)
以下是 Unity 中的預(yù)設(shè) Compute Shader 腳本,這個(gè)章節(jié)就來逐步解析他的結(jié)構(gòu),了解一個(gè)完整的計(jì)算著色器是由哪些元素構(gòu)成的。
計(jì)算核心
就如同名稱一樣,計(jì)算核心 (Kernel) 是計(jì)算著色器中的核心區(qū)塊,當(dāng)執(zhí)行計(jì)算著色器時(shí),其中的程式便會(huì)透過並行的方式運(yùn)行 。
著色器需要透過 #pragma kernel ___ 宣告計(jì)算核心,就和宣告材質(zhì)著色器的 vert 和 frag 一樣。計(jì)算核心的名稱可以自由定義,但一定要有一個(gè)對(duì)應(yīng)的函式實(shí)做才能運(yùn)行。計(jì)算著色器也可以根據(jù)需求定義多個(gè)計(jì)算核心。
多執(zhí)行緒
在定義與實(shí)做了計(jì)算核心之後,接著便要指定他的「執(zhí)行緒數(shù)量」。並行是透過將工作分配給多個(gè)執(zhí)行緒達(dá)成的,因此除了定義計(jì)算核心外,還需要使用 [numthreads(x, y, z)] 分配這個(gè)核心需要的執(zhí)行緒數(shù)量 “num” “threads”。
numthreads() 提供的三個(gè)參數(shù)輸入分別代表維度軸 x, y, z,計(jì)算著色器運(yùn)作時(shí)便會(huì)透過函式的輸入 (uint3 id : SV___) 將執(zhí)行緒 ID 等資料傳入計(jì)算函式中。轉(zhuǎn)換成 CPU 語言中的迴圈看起來應(yīng)該會(huì)更直觀。
但請(qǐng)注意!這只是比喻,計(jì)算著色器中不會(huì)真的像迴圈那樣跑,而是以並行的方式亂序執(zhí)行,別忘了最一開始的示意圖。
至於為什麼會(huì)需要三個(gè)維度軸的執(zhí)行緒的數(shù)量呢?Microsoft 官方文檔是這樣說的:
numthreadsFor example, if a compute shader is doing 4x4 matrix addition then numthreads could be set to numthreads(4,4,1) and the indexing in the individual threads would automatically match the matrix entries. The compute shader could also declare a thread group with the same number of threads (16) using numthreads(16,1,1), however it would then have to calculate the current matrix entry based on the current thread number.
簡(jiǎn)單來說就是為了「方便」,視你要處理的資料結(jié)構(gòu)而定,多的維度軸可以幫使用者省去轉(zhuǎn)換工作,讓 ID 與資料欄位直接對(duì)應(yīng)。就像 CPU 語言中,要遍歷具有座標(biāo)性質(zhì)的陣列元素時(shí),透過多層迴圈直接對(duì)應(yīng)各個(gè)維度軸會(huì)更加輕鬆。
當(dāng)然並行時(shí)也同理,假如我現(xiàn)在要處理的是圖片資料,透過兩個(gè)維度軸直接對(duì)應(yīng)至像素位置上,會(huì)比透過長(zhǎng)寬換算來的方便,這就是為什麼計(jì)算著色器也允許分配多個(gè)軸向的執(zhí)行緒數(shù)量。
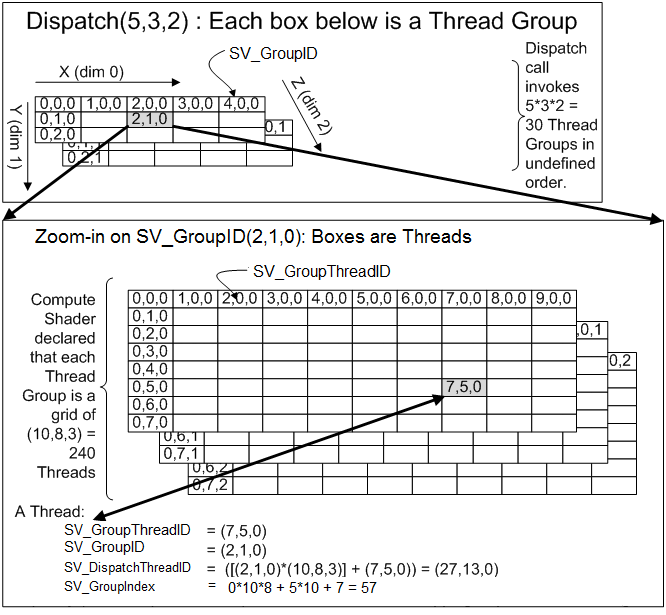
執(zhí)行緒組
計(jì)算著色器的運(yùn)行時(shí)機(jī)是由使用者掌控的,因此在定義完計(jì)算核心與執(zhí)行序數(shù)量後,還是需要手動(dòng)呼叫 ComputeShader.Dispatch() 來「運(yùn)行」計(jì)算著色器。
![]()
註:CPU 與 GPU 的運(yùn)作通常是異步的,因此「通常情況下」計(jì)算著色器並不是在使用者調(diào)用 Dispatch 的當(dāng)下就會(huì)執(zhí)行,而是有自己的運(yùn)行時(shí)機(jī)在。
註2:我猜測(cè)這也是為什麼函式會(huì)叫做 Dispatch,而非更直白的 Execute,但我還沒找到「直接」證實(shí)這一點(diǎn)的官方文檔,如果我的猜測(cè)或描述有誤的話還請(qǐng)各位指正,若有看到相關(guān)資料的也麻煩各位提供了 Orz。
Dispath 函式一共接受四個(gè)參數(shù)輸入,第一個(gè) kernelIndex 代表的是這次 Dispath 要使用的計(jì)算核心,如果著色器中有定義複數(shù)的核心,便可藉由改變參數(shù)切換計(jì)算著色器的功能。如果要取得計(jì)算核心的話,只需要使用 FindKernel() 便可透過名稱尋找對(duì)應(yīng)的計(jì)算核心。
至於後面三個(gè)參數(shù) threadGroupsX,Y,Z,代表的是這次運(yùn)行要分配的「執(zhí)行緒組」有多少個(gè)(下面簡(jiǎn)稱 “組”) “thread” “Groups”。上個(gè)部份提到的 numthread 分配的是一個(gè)組裡面要有多少執(zhí)行緒,而 threadGroups 則會(huì)指定一次運(yùn)行要分配多少個(gè)執(zhí)行緒組。
因此,當(dāng)計(jì)算著色器運(yùn)行時(shí),最終會(huì)執(zhí)行的次數(shù)會(huì)有 threadGroups * numthreads 次。同樣,替換 CPU 語言中的迴圈看起來會(huì)更直觀。但也再次提醒這只是比喻,而且組和組之間也會(huì)並行,並非上一個(gè)組完成才會(huì)進(jìn)入下一個(gè)組。
因此,當(dāng)計(jì)算著色器運(yùn)行時(shí),最終會(huì)執(zhí)行的次數(shù)會(huì)有 threadGroups * numthreads 次。同樣,替換 CPU 語言中的迴圈看起來會(huì)更直觀。但也再次提醒這只是比喻,而且組和組之間也會(huì)並行,並非上一個(gè)組完成才會(huì)進(jìn)入下一個(gè)組。
每個(gè)執(zhí)行緒的 SV_DispatchThreadID 便是當(dāng)前的執(zhí)行緒組 * 執(zhí)行緒數(shù)量 + 當(dāng)前的執(zhí)行緒,不過這些 ID 的計(jì)算系統(tǒng)都會(huì)幫我們完成,所以使用者只要分配好需要的數(shù)量即可。
至具體數(shù)量該怎麼分配呢?首先從處理資料的維度下手,假設(shè)著色器要處理的主要數(shù)據(jù)為一維的陣列就分配 (n, 1, 1),若要對(duì)圖片的二維像素陣列操作就用 (x, y, 1),或是要計(jì)算三維的體積網(wǎng)格就 (x, y, z)。
執(zhí)行緒的具體數(shù)量或比例則沒有明確規(guī)則,大概抓個(gè)介於 10 和資料總數(shù) 1% 以下的數(shù)值吧。假設(shè)陣列長(zhǎng)度大約一萬,numthread 就分配為 (100, 1, 1),若圖片大小 2048 的話就分配 (20, 20, 1)。
修正:理想的執(zhí)行緒組數(shù)量應(yīng)該是介於 32 至 1024 之間,並且為 32 的倍數(shù),似乎與 GPU 的硬體結(jié)構(gòu)有關(guān),資料先補(bǔ)充在文末,細(xì)節(jié)會(huì)等我深入了解後再補(bǔ)上。 (感謝巴友 美遊ちゃん 指正)
最後,組的數(shù)量可以透過資料長(zhǎng)度除以執(zhí)行緒數(shù)量得出,畢竟資料的多寡可能根據(jù)情況產(chǎn)生差異,透過這種方式可以確保在任何情況下都有足夠的執(zhí)行緒進(jìn)行計(jì)算。
並且著色器訪問陣列時(shí)不會(huì)因?yàn)?index out of range 而出誤中斷,所以只需要確保分配的數(shù)量足夠即可。(只有少數(shù)情況會(huì)因?yàn)閿?shù)量過多導(dǎo)致結(jié)果錯(cuò)誤,文章最後的範(fàn)例會(huì)提到解決方法)
資料訪問
最後,計(jì)算著色器中最關(guān)鍵的部份,透過並行運(yùn)算對(duì)傳入著色器的資料進(jìn)行操作!如果執(zhí)行緒的數(shù)量分配正確,每個(gè) ThreadID 都會(huì)對(duì)應(yīng)到各自的要處理的資料欄位上。
假如我要將一張圖片重置為黑色,只需要透過執(zhí)行緒 ID 對(duì)應(yīng)至圖片的每個(gè)像素,並將黑色寫入像素即可。由於資料的維度為二維,因此訪問資料欄位時(shí)的索引輸入也是二維 Image[id.xy]。
在每個(gè)執(zhí)行中緒訪問資料也不侷限於自己的 ID,視需求也
可以讀、寫其他欄位上的資料。例如時(shí)常應(yīng)用在影像處理中的卷積矩陣 (
Kernel Convolution),就會(huì)參考周圍像素的資料來進(jìn)行計(jì)算。下面是方框模糊的範(fàn)例程式,將像素與周圍八格進(jìn)行平均。
卷積矩陣的簡(jiǎn)單範(fàn)例,分別為無效果、方框模糊與高斯模糊。
圖片引用自 Kernel Convolution Wiki
註:當(dāng)多個(gè)執(zhí)行緒試圖同時(shí)讀寫「同個(gè)位置上」的資訊時(shí)可能會(huì)發(fā)生數(shù)據(jù)爭(zhēng)用 (data race) 或競(jìng)態(tài)條件 (race condition) 的情況,但計(jì)算著色器似乎能一定程度上預(yù)防毀滅性的後果發(fā)生,所以不要太過分應(yīng)該不用擔(dān)心?具體狀況我也還沒遇到過,相關(guān)參考資料會(huì)在文末提供。
資料傳遞資料傳遞,計(jì)算著色器的第二項(xiàng)重點(diǎn)。一開始有提到過,CPU 與 GPU 運(yùn)作時(shí)使用的儲(chǔ)存空間不同,因此在計(jì)算著色器執(zhí)行任何的操作前都必須先將資料傳遞給 GPU 才行。這個(gè)章節(jié)就開始解說計(jì)算著色器的各種資料型別,以及如何傳遞資料給計(jì)算著色器使用。
只讀參數(shù)
與一般的渲染著色器一樣,計(jì)算著色器也可以傳入單一的參數(shù)用於計(jì)算。且同樣的,這些數(shù)值在整個(gè)著色器中是全域共享並且只讀的,包括不同計(jì)算核心與函式,通常用於傳遞全域?qū)傩耘c設(shè)置類的參數(shù)。
以繪圖系統(tǒng)為例就是畫布大小、筆刷位置、筆刷強(qiáng)度與顏色等參數(shù)。透過 SetVector(), SetFloat() 等函式進(jìn)行傳遞。
要使用這些參數(shù)的話,在著色器中也需要建立對(duì)應(yīng)名稱的變數(shù)接收。
緩衝資料
與只讀的全域參數(shù)不同,由於儲(chǔ)存空間的差異以及資料傳遞的成本,若想讓計(jì)算著色器對(duì)資料內(nèi)容進(jìn)行操作 ,或是想傳遞大量的獨(dú)立參數(shù)供執(zhí)行緒個(gè)別使用的話,就必須事先對(duì) GPU 的儲(chǔ)存空間進(jìn)行分配。
GPU 的資料儲(chǔ)存空間為緩衝區(qū) (Buffer),在 Unity 中只需要透過 new ComputeBuffer() 即可建立一個(gè)新的 GPU 緩衝區(qū),引擎會(huì)幫我們完成繁瑣的內(nèi)部作業(yè)。
計(jì)算緩衝區(qū)的建構(gòu)子需要接收三個(gè)參數(shù)輸入,第一個(gè) count 代表緩衝區(qū)「最多」需要儲(chǔ)存多少元素,通常就是我們想傳遞的陣列資料的長(zhǎng)度。stride 為一個(gè)欄位的元素大小,通常就是想傳遞的陣列資料的型別,可以透過 sizeof(type) 取得。
而最後的 ComputeBufferType 則是緩衝區(qū)的類別,可以根據(jù)需求使用不同的類型。具體的類型有許多種,不過這裡先關(guān)注最常用的兩種即可:
假設(shè)我要將一個(gè)長(zhǎng)度為 10000 的向量陣列傳入計(jì)算著色器,並對(duì)裡面的元素進(jìn)行過濾的話,就會(huì)需要一個(gè)結(jié)構(gòu)緩衝區(qū)與一個(gè)容器緩衝區(qū),元素?cái)?shù)量與陣列相同 (10000),元素大小為三個(gè)單精度浮點(diǎn)數(shù)。
分配完儲(chǔ)存空間後,還需要透過 SetData() 將想傳遞的資料存入緩衝區(qū)當(dāng)中。
最後,只需要將緩衝區(qū)指定給計(jì)算著色器,就能讓他在運(yùn)行時(shí)使用這些資料了,不過與先前的只讀參數(shù)不同,緩衝資料需要指定一個(gè)目標(biāo)的計(jì)算核心。不太需要擔(dān)心指定緩衝區(qū)的開銷,因?yàn)樵?SetData() 的時(shí)候資料傳遞就已經(jīng)完成了,這裡只是改變計(jì)算著色器中指向緩衝區(qū)位置的指標(biāo)而已。
計(jì)算著色器也需要對(duì)應(yīng)的緩衝區(qū)變數(shù)接收才能使用這些資料。建立時(shí)需要透過 <T> 欄位指定資料型別,型別必須與建立緩衝區(qū)時(shí)的分配的元素大小 stride 一致。
若想讓緩衝區(qū)一次傳遞複合資料,也可以透過結(jié)構(gòu)包裝多個(gè)變數(shù)。
除此之外,結(jié)構(gòu)緩衝區(qū)還有一種 RWStructuredBuffer<T>,這種緩衝區(qū)會(huì)允許計(jì)算核心將資料寫入緩衝區(qū),視需求使用。
貼圖資料
除了傳遞一維陣列的緩衝區(qū)以外,計(jì)算著色器也能接受圖片資料,將二維的像素陣列傳入計(jì)算著色器使用。透過 SetTexture() 函式傳遞圖片至著色器中,一樣需要指定計(jì)算核心。
與所有類型的資料傳遞相同,圖片接收也需要建立對(duì)應(yīng)的變數(shù)接收,並且還需要指定圖片的通道數(shù)量與精度,如 float, fixed3, half4 等等。
除此之外,在計(jì)算著色器中訪問圖片像素資訊時(shí)也與渲染著色器的方法不同,Texture2D<T> 是透過像素座標(biāo)直接訪問特定欄位上的資料,而非 sampler2D 的 uv 採樣函式 Tex2D()。
Texture2D<T> 為只讀的像素緩衝區(qū),如果要允許寫入像素的話需要用 RWTexture2D<T>。要注意的是讀寫貼圖只能傳入 RenderTexture,原理和建立緩衝區(qū)時(shí)一樣,建立渲染貼圖時(shí)也會(huì)做分配空間的工作。
釋放空間
由於 GPU 儲(chǔ)存空間是相當(dāng)珍貴的,所以在不需要緩衝區(qū)時(shí)也要記得將空間釋放。只要透過 Release() 函式執(zhí)行即可。
實(shí)作範(fàn)例最後,回到最一開始的問題,有什麼問題是能透過並行解決的,以及該怎麼透過並行解決問題?在概括與腳本結(jié)構(gòu)的章節(jié)中有看到,無論是計(jì)算核心的編寫方法,還是代換成 C# 中迴圈的形式,他們都表現(xiàn)出了一個(gè)共同點(diǎn):重複執(zhí)行相似的工作。
意思是,只要問題能夠被拆分為「?jìng)€(gè)別獨(dú)立」並且「高度相似」的片段,就能透過重複執(zhí)行的方法完成。如此一來,無論是要透過迴圈線性執(zhí)行,或是將每個(gè)片段分配給獨(dú)立的執(zhí)行緒,以並行的方式解決,都能有效的達(dá)成目標(biāo)。
最後的章節(jié)就透過各種範(fàn)例,將文中提到的各項(xiàng)重點(diǎn)串起。問題拆分、資料傳遞、解決問題,逐步分析如何使用計(jì)算著色器,透過並行的方式達(dá)成任務(wù)。
回顧腳本
首先,在開始解決自己的問題前,先來回顧一次預(yù)設(shè)的腳本結(jié)構(gòu),分析它做了哪些事,傳遞了什麼資料,以及該怎麼使用這個(gè)計(jì)算著色器。
預(yù)設(shè)著色器宣告了一個(gè)計(jì)算核心,名稱叫做 CSMain (Compute Shader Main)。
他只宣告了一個(gè)讀寫貼讀緩衝區(qū),精度為 float,通道數(shù)量 4 個(gè)。代表這個(gè)計(jì)算著色器要處理的主要資料結(jié)構(gòu)是圖片。
由於訪問資料的維度軸為二維(圖片、ㄋ像素陣列),因此執(zhí)行緒數(shù)量的格式為 (x, y, 1)。
最後是預(yù)設(shè)的計(jì)算核心,名稱對(duì)應(yīng)一開始宣告的 CSMain。透過多個(gè)執(zhí)行緒對(duì)應(yīng)到圖片緩衝區(qū) Result 的每個(gè)像素上,同時(shí)利用像素座標(biāo)的數(shù)值(也就是 id)進(jìn)行計(jì)算,並將計(jì)算結(jié)果寫入像圖片緩衝區(qū)。(先忽略計(jì)算式的原理,那不是這裡的重點(diǎn))
回到 C# 處,來看看如何使用這個(gè)預(yù)設(shè)著色器。首先要尋找著色器中定義的計(jì)算核心 CSMain。
接著,為了提供讀寫貼圖需要的圖片資料,需要建立一個(gè) RenderTexture,並傳入計(jì)算著色器的 Result 當(dāng)中。
最後,調(diào)用著色器執(zhí)行指定的計(jì)算核心。由於著色器中指定的執(zhí)行序數(shù)量為 8,因此執(zhí)行時(shí)必須將執(zhí)行緒組的數(shù)量分配至圖片大小除以 8 才夠。
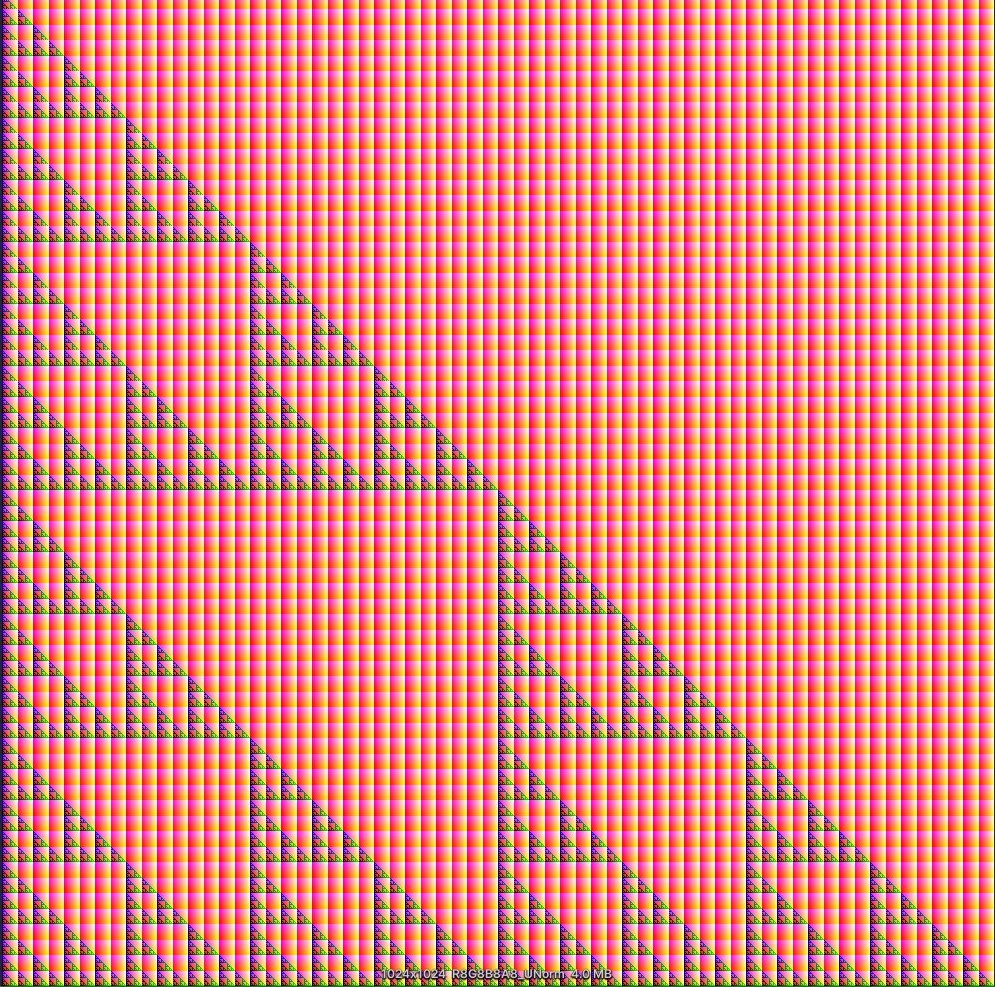
運(yùn)作結(jié)果如下,這是一個(gè)能繪製分型的計(jì)算著色器。
陣列計(jì)算看完了預(yù)設(shè)的著色器,現(xiàn)在輪到我們應(yīng)用這些知識(shí)嘗試解決自己的問題。一步一步來,首先是:
1. 要解決什麼問題
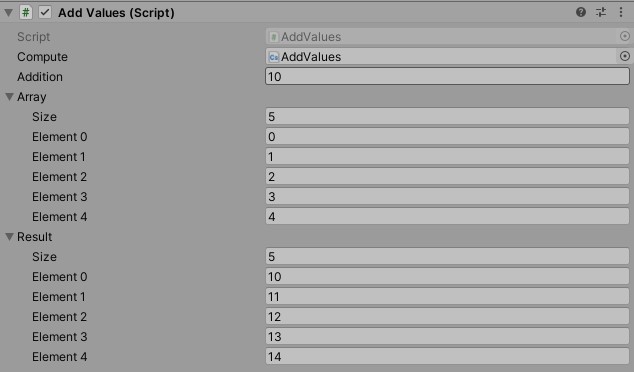
將陣列中每個(gè)元素的數(shù)值 + n
2. 要怎麼傳遞資料
首先是全域只讀的參數(shù),也就是要增加的數(shù)值 n。透過 SetInt() 函式將數(shù)值傳入計(jì)算著色器。
接著是要透過計(jì)算著色器處理的資料。建立一個(gè) ComputeBuffer 分配需要 GPU 儲(chǔ)存空間,將要進(jìn)行操作的陣列資料存入緩衝區(qū),並指定給計(jì)算著色器。
ComputeBufferType.Structured
3. 要怎麼解決問題
將問題拆分為相似的片段,透過重複執(zhí)行的方式解決問題。在這個(gè)例子中便是以多個(gè)執(zhí)行緒分別對(duì)應(yīng)到陣列的所有元素上,並各自執(zhí)行 + n 的動(dòng)作。
由於資料維度為一維陣列,因此執(zhí)行序數(shù)量的格式為 (n, 1, 1)。
最後,呼叫計(jì)算著色器執(zhí)行計(jì)算,執(zhí)行緒組的數(shù)量為陣列數(shù)量除以 10。
資料過濾
第二個(gè)範(fàn)例,透過計(jì)算著色器進(jìn)行資料過濾。首先:
1. 要解決什麼問題
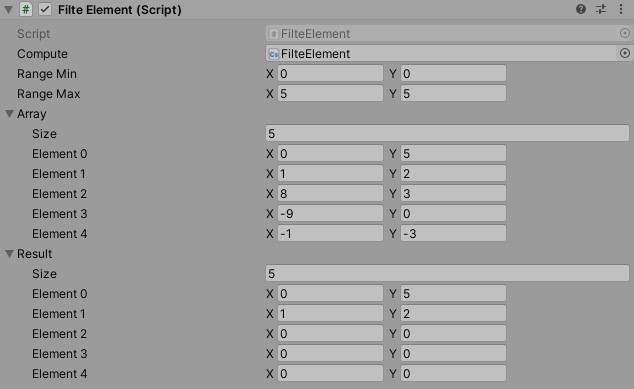
對(duì)陣列的元素進(jìn)行過濾,找出位於指定範(fàn)圍中的向量元素。
2. 要怎麼傳遞資料
首先是兩個(gè)只讀的全域向量,用於作為過濾範(fàn)圍的最小與最大值。使用 SetVector() 函式進(jìn)行傳遞。
接著是要透過計(jì)算著色器處理的資料。由於我們像要對(duì)元素進(jìn)行過濾,因此需要建立兩個(gè)計(jì)算緩衝區(qū),一個(gè)為 StructuredBuffer 用於傳遞原始陣列資料進(jìn)著色器,另一個(gè)則是用於儲(chǔ)存過濾後元素的 AppendBuffer。
除此之外,使用計(jì)算著色器過濾元素時(shí),可能因?yàn)閳?zhí)行序數(shù)量過多而導(dǎo)致錯(cuò)誤的元素被添加至結(jié)果緩衝區(qū)當(dāng)中,也就是資料傳遞章節(jié)中提到的非預(yù)期錯(cuò)誤。為了防止錯(cuò)誤發(fā)生,還需要將實(shí)際的陣列長(zhǎng)度傳遞給著色器。
3. 要怎麼解決問題
將問題拆分為相似的片段,在這個(gè)範(fàn)例中便是透過執(zhí)行緒 ID 讀取各自欄位上的資料,並將符合條件的元素加入結(jié)果緩衝區(qū)中。透過 Append 函式即可將元素存入緩衝區(qū)。
為了避免將非預(yù)期的元素也存入緩衝區(qū),可以判斷執(zhí)行緒 ID 是否超出陣列的長(zhǎng)度,作為防呆判斷。
執(zhí)行緒的數(shù)量和上個(gè)範(fàn)例相同,因?yàn)橘Y料維度為一維陣列,所以執(zhí)行序數(shù)量的格式為 (n, 1, 1)。
最後,呼叫著色器執(zhí)行計(jì)算。
4. 要怎麼使用資料
運(yùn)算完成後,透過 GetData() 取得緩衝區(qū)資料,用於檢視效果。
要注意的是緩衝區(qū)在建立時(shí),欄位數(shù)量是根據(jù)「可能的最大值」建立的,即使 AppendBuffer 當(dāng)中沒有「添加」那麼多元素,他的
長(zhǎng)度還是會(huì)與完整陣列相同。如果想獲得實(shí)際存入的元素?cái)?shù)量,可以透過
ComputeBuffer.CopyCount 函式取得。
除錯(cuò)建議
由於著色器本身的除錯(cuò)難度,再加上兩個(gè)環(huán)境之間的資料傳遞問題,計(jì)算著色器的除錯(cuò)過程也是相當(dāng)令人頭疼的。範(fàn)例的最後就提供幾項(xiàng)除錯(cuò)時(shí)的指標(biāo)供各位參考,一步步縮小可能的問題範(fàn)圍。
檢查資料有沒有正確寫入緩衝區(qū)
在 buffer.SetData() 的環(huán)節(jié)中是否錯(cuò)誤?資料有成功傳入緩衝區(qū)嗎?資料有沒有傳遞進(jìn)正確的緩衝區(qū)?原始資料本身是正確的嗎?
檢查緩衝區(qū)有沒有分配給著色器
在 compute.SetBuffer() 的環(huán)節(jié)是否正常?是否有將緩衝區(qū)指定給計(jì)算著色器?指定時(shí)的計(jì)算核心正不正確?緩衝區(qū)的名稱是否匹配?
檢查著色器讀取資料有沒有正確
計(jì)算函式訪問緩衝區(qū)資料時(shí)是否出錯(cuò)?有沒有訪問到正確的緩衝區(qū)?資料欄位的 ID 是否正確?
檢查著色器寫入資料有沒有正確
計(jì)算函式輸出結(jié)果的過程是否正常?有沒有將結(jié)果寫入緩衝區(qū)?有沒有寫入到正確的緩衝區(qū)中?
檢查著色器計(jì)算函式有沒有正確
最後,當(dāng)上述檢查都確認(rèn)過以後,問題可能就出在著色器的計(jì)算函式本身了。由於各種需求的實(shí)際差異甚大,這裡就比較難提供建議了,但請(qǐng)放心,與資料傳遞相比這是最好除錯(cuò)的部份了~
更多例子
上面用了兩個(gè)簡(jiǎn)單的例子展示如何編寫自己的計(jì)算著色器,但要注意這並不是真正「應(yīng)用」計(jì)算著色器時(shí)會(huì)使用的做法。由於 CPU 與 GPU 間的資料傳遞成本高昂以及運(yùn)行時(shí)機(jī)等問題,通常不會(huì)像範(fàn)例中透過 GetData() 將資料取回 C#,而是直接讓渲染管線使用這些資料。
或者將它視為一種「開發(fā)工具」也是可以的,使用計(jì)算著色器製作出輔助工具,在編輯器狀態(tài)下事先將高成本的運(yùn)算完成,例如生成光照貼圖與噪聲圖之類的。可惜的是更實(shí)際的範(fàn)例放進(jìn)來會(huì)讓篇幅過長(zhǎng),所以這裡就提供一些實(shí)際應(yīng)用的例子,讓有興趣的人自行深入研究吧~
Conway’s Game of Life
康威生命遊戲,以網(wǎng)格為空間單位,每個(gè)單位格都是一個(gè)細(xì)胞,而回合則為這個(gè)世界的時(shí)間單位,在每個(gè)回合中細(xì)胞都會(huì)根據(jù)周圍的環(huán)境狀態(tài)來決定自己將存活還是死亡。屬於比較好分辨出如何並行的例子,實(shí)做難度低。
引用自 Conway’s Game of Life Wiki
GPU Slime Simulations
透過計(jì)算著色器模擬大量的單位,並讓這些單位以簡(jiǎn)單的行為互相交互,產(chǎn)生有趣的結(jié)果。屬於比較好玩的例子。實(shí)做上稍微複雜一點(diǎn),需要透過多個(gè)階段的處裡才能達(dá)成最終效果。
引用自 Coding Adventure: Ant and Slime Simulations
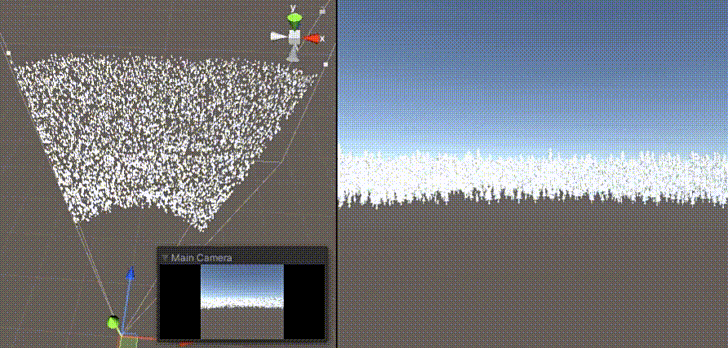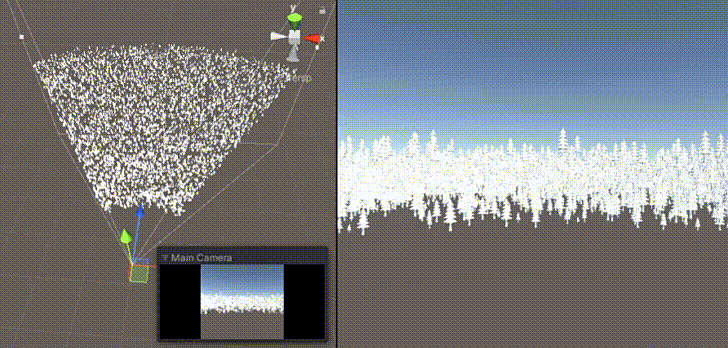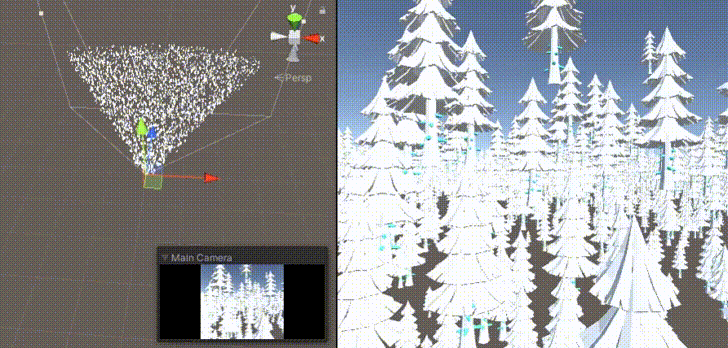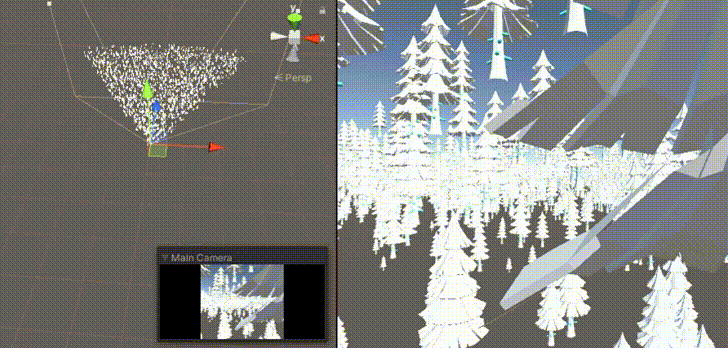
GPU Culling與 GPU Instance 搭配使用的技術(shù),透過計(jì)算著色器進(jìn)行視錐剃除,過濾出位在攝影機(jī)視角內(nèi)的物件,達(dá)成更高效的渲染優(yōu)化。需要注意的主要是渲染相關(guān)的問題,是比較實(shí)際而且簡(jiǎn)單的例子,建議初學(xué)著進(jìn)行嘗試。
圖片引用自 Unity中使用ComputeShader做視錐剔除
GPU Ray Tracing
將環(huán)境、物件與材質(zhì)等資料傳入計(jì)算著色器,直接透過自訂的方法進(jìn)行渲染,並將結(jié)果輸出至畫面上。方法不侷限於光線追蹤,任何以螢?zāi)幌袼貫閱挝坏膩K行都可以使用(如射線邁進(jìn)),是比較實(shí)際但較高難度的運(yùn)用。
引用自 GPU Ray Tracing in Unity
感謝閱讀
在知道了 GPU Instance 和 GPU Culling 兩項(xiàng)技術(shù)後,我也接觸到計(jì)算著色器這項(xiàng)工具,並正式踏入 GPU 並行的世界了。為了學(xué)計(jì)算著色器我查了不少資料研究,但總覺的很多內(nèi)容都不夠直觀,不然就是一口氣跳到太深的內(nèi)容(像是直接教 RayTracing 的文章),以至於我花了不少時(shí)間試錯(cuò)後才得出一些基礎(chǔ)但相當(dāng)重要的結(jié)論。
於是,在幾個(gè)月的實(shí)做研究後,我嘗試用自己的理解重新解釋了一次計(jì)算著色器,將學(xué)習(xí)時(shí)注意到的各項(xiàng)重點(diǎn)分享給各位,希望能提供有興趣的人參考方向!
有任何建議和想法都?xì)g迎提出討論,如果喜歡文章內(nèi)容的話也請(qǐng)幫我點(diǎn)一下 Like Button :D
參考資料
 創(chuàng)作內(nèi)容
創(chuàng)作內(nèi)容





 --- 重點(diǎn)文章 --- (0)
--- 重點(diǎn)文章 --- (0)